简介 Tokenizer 和 Lexical anaylizer 1 2 3 4 package mainfunc main () println ("Hello, World!" ) }
这段go 代码做了什么?很简单吧,package是main,定义了个main函数,main函数里调用了println函数,参数是“Hello, World!”。好,你是知道了,可当你运行go run时,go 怎么知道的?
go先要把你的代码打散成自己可以理解的构成部分(token),这一过程就叫tokenize。
例如,第一行就被拆成了package和main。 这个阶段,go 就像小婴儿只会理解我、要、吃饭等词,但串不成合适句子。因为“吃饭我要”是讲不通的,所以把词按一定的语法串起来的过程就是lexical anaylize 或者parse,简单吧!和人脑不同的是,被程序理解的代码,通常会以abstract syntax tree(AST )的形式存储起来,方便进行校验和查找。
Go的AST 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ( "go/ast" "go/parser" "go/token" ) func main () src := ` package main func main() { println("Hello, World!") } ` fset := token.NewFileSet() f, err := parser.ParseFile(fset, "" , src, 0 ) if err != nil { panic (err) } ast.Print(fset, f) }
为了不吓到你,我先只打印前6行:
1 2 3 4 5 6 7 0 *ast.File { 1 . Package: 2:1 2 . Name: *ast.Ident { 3 . . NamePos: 2:9 4 . . Name: "main" 5 . } // 省略之后的50+行
可见,go 解析出了package这个关键词在文本的第二行的第一个(2:1)。“main”也解析出来了,在第二行的第9个字符,但是go 的解析器还给它安了一个叫法:ast .Ident, 标示符 或者大家常说的ID,如下图所示:
1 2 3 4 5 Ident +------------+ | Package +-----+ | v v package main
接下来我们看看那个main函数被整成了什么样。
1 2 3 4 5 6 7 8 9 6 . Decls: []ast.Decl (len = 1) { 7 . . 0: *ast.FuncDecl { 8 . . . Name: *ast.Ident { 9 . . . . NamePos: 3:6 10 . . . . Name: "main" 11 . . . . Obj: *ast.Object { 12 . . . . . Kind: func 13 . . . . . Name: "main" 14 . . . . . Decl: *(obj @ 7)
此处func main被解析成ast .FuncDecl(function declaration),而函数的参数(Params)和函数体(Body)自然也在这个FuncDecl中。Params对应的是ast .FieldList,顾名思义就是项列表;而由大括号“{}”组成的函数体对应的是ast *.BlockStmt(block statement)。如果不清楚,可以参考下面的图:
1 2 3 4 5 6 7 8 9 FuncDecl.Params +----------+ | FuncDecl.Name +--------+ | v v +----------------------> func main() { | +-> FuncDecl ++ FuncDecl.Body +-+ println("Hello, World!") | +-> +----------------------> }
而对于main函数的函数体中,我们可以看到调用了println函数,在ast 中对应的是ExprStmt(Express Statement),调用函数的表达式对应的是CallExpr(Call Expression),调用的参数自然不能错过,因为参数只有字符串,所以go 把它归为ast .BasicLis (a literal of basic type)。如下图所示:
1 2 3 4 5 6 +-----+ ExprStmt +---------------+ | | | CallExpr BasicLit | | + + | | v v | +---> println("Hello, World!")<--+
还有什么?
1 2 3 4 5 6 7 8 9 50 . Scope: *ast.Scope { 51 . . Objects: map[string]*ast.Object (len = 1) { 52 . . . "main": *(obj @ 11) 53 . . } 54 . } 55 . Unresolved: []*ast.Ident (len = 1) { 56 . . 0: *(obj @ 29) 57 . } 58 }
我们可以看出ast 还解析出了函数的作用域,以及作用域对应的对象。
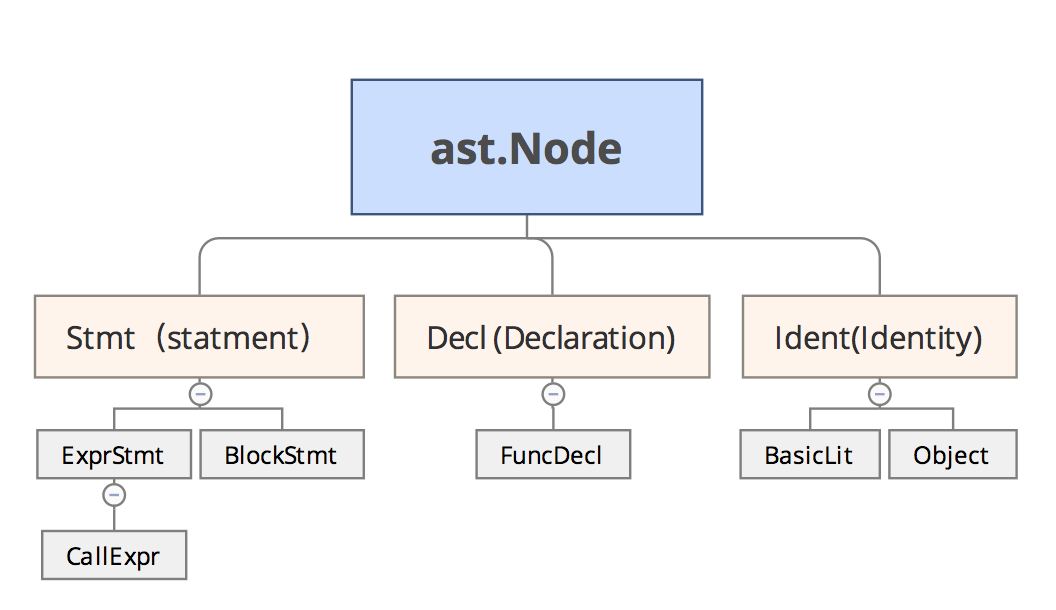
小结 Go 将所有可以识别的token抽象成Node,通过interface方式组织在一起,它们之间的关系如下图示意:
ast.Expr - 代表表达式和类型的节点
ast.Stmt - 代表报表节点
ast.Decl - 代表声明节点
Go的AST内部是如何组织的? 我们知道,根据编译过程,一般来说首先我们需要词法分析,然后才有语法分析。
Go的parser接受的输入是源文件,内嵌了一个scanner,最后把scanner生成的token变成一颗抽象语法树(AST)。
我们现在打印下输出hello,world的抽象语法树。这也是官网的例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ( "go/ast" "go/parser" "go/token" ) func main () src := ` package main func main() { println("Hello, World!") } ` fset := token.NewFileSet() f, err := parser.ParseFile(fset, "" , src, 0 ) if err != nil { panic (err) } ast.Print(fset, f) }
先看下语法树,解释下都有哪些东西:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 0 *ast.File { 1 . Package: 2:1 2 . Name: *ast.Ident { 3 . . NamePos: 2:9 4 . . Name: "main" 5 . } 6 . Decls: []ast.Decl (len = 1) { 7 . . 0: *ast.FuncDecl { 8 . . . Name: *ast.Ident { 9 . . . . NamePos: 3:6 10 . . . . Name: "main" 11 . . . . Obj: *ast.Object { 12 . . . . . Kind: func 13 . . . . . Name: "main" 14 . . . . . Decl: *(obj @ 7) 15 . . . . } 16 . . . } 17 . . . Type: *ast.FuncType { 18 . . . . Func: 3:1 19 . . . . Params: *ast.FieldList { 20 . . . . . Opening: 3:10 21 . . . . . Closing: 3:11 22 . . . . } 23 . . . } 24 . . . Body: *ast.BlockStmt { 25 . . . . Lbrace: 3:13 26 . . . . List: []ast.Stmt (len = 1) { 27 . . . . . 0: *ast.ExprStmt { 28 . . . . . . X: *ast.CallExpr { 29 . . . . . . . Fun: *ast.Ident { 30 . . . . . . . . NamePos: 4:5 31 . . . . . . . . Name: "println" 32 . . . . . . . } 33 . . . . . . . Lparen: 4:12 34 . . . . . . . Args: []ast.Expr (len = 1) { 35 . . . . . . . . 0: *ast.BasicLit { 36 . . . . . . . . . ValuePos: 4:13 37 . . . . . . . . . Kind: STRING 38 . . . . . . . . . Value: "\"Hello, World!\"" 39 . . . . . . . . } 40 . . . . . . . } 41 . . . . . . . Ellipsis: - 42 . . . . . . . Rparen: 4:28 43 . . . . . . } 44 . . . . . } 45 . . . . } 46 . . . . Rbrace: 5:1 47 . . . } 48 . . } 49 . } 50 . Scope: *ast.Scope { 51 . . Objects: map[string]*ast.Object (len = 1) { 52 . . . "main": *(obj @ 11) 53 . . } 54 . } 55 . Unresolved: []*ast.Ident (len = 1) { 56 . . 0: *(obj @ 29) 57 . } 58 }
Package: 2:1代表Go解析出package这个词在第二行的第一个
main是一个ast.Ident标识符,它的位置在第二行的第9个
此处func main被解析成ast.FuncDecl(function declaration),而函数的参数(Params)和函数体(Body)自然也在这个FuncDecl中。Params对应的是*ast.FieldList,顾名思义就是项列表;而由大括号“{}”组成的函数体对应的是ast.BlockStmt(block statement)
而对于main函数的函数体中,我们可以看到调用了println函数,在ast中对应的是ExprStmt(Express Statement),调用函数的表达式对应的是CallExpr(Call Expression),调用的参数自然不能错过,因为参数只有字符串,所以go把它归为ast.BasicLis (a literal of basic type)。
最后,我们可以看出ast还解析出了函数的作用域,以及作用域对应的对象。
Go将所有可以识别的token抽象成Node,通过interface方式组织在一起。
在这里说到token我们需要说一下词法分析,token是词法分析的结果,即将字符序列转换为标记(token)的过程,这个操作由词法分析器完成。这里的标记是一个字符串,是构成源代码的最小单位。
语法树的生成过程 FileSet就是源文件集合,因为我们一次解析可能不止解析一个文件,而是一系列文件。
FileSet最主要的用途是用来保存token的位置信息,每个token在当前文件的位置可以用行号,列号,token在当前文件中的偏移量这三个属性来描述,使用PositionFileSet中保存所有token的Position信息,而在ast中,只保存一个Posast的时候,我们需要使用Pos索引向FileSetPosition。
1 fset := token.NewFileSet()
新建一个AST文件集合,
1 2 3 4 5 6 7 8 9 type FileSet struct { mutex sync.RWMutex base int files []*File last *File }
然后,解析该集合,f, err := parser.ParseFile(fset, "", src, 0)
ParseFile会解析单个Go源文件的源代码并返回相应的ast.File节点。
源代码可以通过传入源文件的文件名,或src参数提供。如果src!= nil,则ParseFile将从src中解析源代码,文件名为仅在记录位置信息时使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 func ParseFile (fset *token.FileSet, filename string , src interface {}, mode Mode) (f *ast.File, err error) if fset == nil { panic ("parser.ParseFile: no token.FileSet provided (fset == nil)" ) } text, err := readSource(filename, src) if err != nil { return nil , err } var p parser defer func () if e := recover (); e != nil { if _, ok := e.(bailout); !ok { panic (e) } } if f == nil { f = &ast.File{ Name: new (ast.Ident), Scope: ast.NewScope(nil ), } } p.errors.Sort() err = p.errors.Err() }() p.init(fset, filename, text, mode) f = p.parseFile() return }
parse是解析器的结构体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 type parser struct { file *token.File errors scanner.ErrorList scanner scanner.Scanner mode Mode trace bool indent int comments []*ast.CommentGroup leadComment *ast.CommentGroup lineComment *ast.CommentGroup pos token.Pos tok token.Token lit string syncPos token.Pos syncCnt int exprLev int inRhs bool pkgScope *ast.Scope topScope *ast.Scope unresolved []*ast.Ident imports []*ast.ImportSpec labelScope *ast.Scope targetStack [][]*ast.Ident }
我们来看下具体的解析过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 func (p *parser) parseFile () *ast .File if p.trace { defer un(trace(p, "File" )) } if p.errors.Len() != 0 { return nil } doc := p.leadComment pos := p.expect(token.PACKAGE) ident := p.parseIdent() if ident.Name == "_" && p.mode&DeclarationErrors != 0 { p.error(p.pos, "invalid package name _" ) } p.expectSemi() if p.errors.Len() != 0 { return nil } p.openScope() p.pkgScope = p.topScope var decls []ast.Decl if p.mode&PackageClauseOnly == 0 { for p.tok == token.IMPORT { decls = append (decls, p.parseGenDecl(token.IMPORT, p.parseImportSpec)) } if p.mode&ImportsOnly == 0 { for p.tok != token.EOF { decls = append (decls, p.parseDecl(syncDecl)) } } } p.closeScope() assert(p.topScope == nil , "unbalanced scopes" ) assert(p.labelScope == nil , "unbalanced label scopes" ) i := 0 for _, ident := range p.unresolved { assert(ident.Obj == unresolved, "object already resolved" ) ident.Obj = p.pkgScope.Lookup(ident.Name) if ident.Obj == nil { p.unresolved[i] = ident i++ } } return &ast.File{ Doc: doc, Package: pos, Name: ident, Decls: decls, Scope: p.pkgScope, Imports: p.imports, Unresolved: p.unresolved[0 :i], Comments: p.comments, } }
我们来看下AST的每种类型结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 type Node interface { Pos() token.Pos End() token.Pos } type Expr interface { Node exprNode() } type Stmt interface { Node stmtNode() } type Decl interface { Node declNode() }
上面就是语法的三个主体,表达式(expression),语句(statement)和声明(declaration),Node是基类接口,任何类型的主体都是Node,用于标记该节点位置的开始和结束.
不过三个主体的函数没有实际意义,只是用三个interface来区分不同的语法单位,如果某个语法是Stmt的话,就实现一个空的stmtNode函数即可.
这样的好处是可以对语法单元进行comma,ok来判断类型,并且保证只有这些变量可以赋值给对应的interface.但是实际上这个划分不是很严格
遍历语法树 语法树层级较深,嵌套关系复杂,如果不能完全掌握node之间的关系和嵌套规则,我们很难自己写出正确的遍历方法。不过好在ast包已经为我们提供了遍历方法:
$GOROOT/src/go/ast/ast.go
1 2 3 4 5 func Walk (v Visitor, node Node) type Visitor interface { Visit(node Node) (w Visitor) }
Walk方法会按照深度优先搜索方法(depth-first order)遍历整个语法树,我们只需按照我们的业务需要,实现Visitor接口即可。 Walk每遍历一个节点就会调用Visitor.Visit方法,传入当前节点。如果Visit返回nil,则停止遍历当前节点的子节点。本示例的Visitor实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 type Visitor struct {}func (v *Visitor) Visit (node ast.Node) ast .Visitor switch node.(type ) { case *ast.GenDecl: genDecl := node.(*ast.GenDecl) if genDecl.Tok == token.IMPORT { v.addImport(genDecl) return nil } case *ast.InterfaceType: iface := node.(*ast.InterfaceType) addContext(iface) return nil } return v } func (v *Visitor) addImport (genDecl *ast.GenDecl) hasImported := false for _, v := range genDecl.Specs { imptSpec := v.(*ast.ImportSpec) if imptSpec.Path.Value == strconv.Quote("context" ) { hasImported = true } } if !hasImported { genDecl.Specs = append (genDecl.Specs, &ast.ImportSpec{ Path: &ast.BasicLit{ Kind: token.STRING, Value: strconv.Quote("context" ), }, }) } } func addContext (iface *ast.InterfaceType) if iface.Methods != nil || iface.Methods.List != nil { for _, v := range iface.Methods.List { ft := v.Type.(*ast.FuncType) hasContext := false for _, v := range ft.Params.List { if expr, ok := v.Type.(*ast.SelectorExpr); ok { if ident, ok := expr.X.(*ast.Ident); ok { if ident.Name == "context" { hasContext = true } } } } if !hasContext { ctxField := &ast.Field{ Names: []*ast.Ident{ ast.NewIdent("ctx" ), }, Type: &ast.SelectorExpr{ X: ast.NewIdent("context" ), Sel: ast.NewIdent("Context" ), }, } list := []*ast.Field{ ctxField, } ft.Params.List = append (list, ft.Params.List...) } } } }
demo:Go-AST 获取函数属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 package utilimport ( "fmt" "go-less/exception" "go/ast" "go/parser" "go/token" "io/ioutil" "strings" ) type ASTFunction struct { Package string Name string Exported bool Recv []map [string ]string Params []map [string ]string Results []map [string ]string } func (f ASTFunction) Println () fmt.Print("所在包:" + f.Package) fmt.Print(",是否公开:" , f.Exported) fmt.Print(",函数名字:" + f.Name) fmt.Print(",函数接收者:" ) fmt.Print(f.Recv) fmt.Print(",函数参数:" ) fmt.Print(f.Params) fmt.Print(",函数返回值:" ) fmt.Print(f.Results) fmt.Println() } func exprToTypeStringRecursively (expr ast.Expr) string if arr, ok := expr.(*ast.ArrayType); ok { if arr.Len == nil { return "[]" + exprToTypeStringRecursively(arr.Elt) } else if lit, ok := arr.Len.(*ast.BasicLit); ok { return "[" + lit.Value + "]" + exprToTypeStringRecursively(arr.Elt) } else { panic (1 ) } } if _, ok := expr.(*ast.InterfaceType); ok { return "interface{}" } if indent, ok := expr.(*ast.Ident); ok { return indent.Name } else if selExpr, ok := expr.(*ast.SelectorExpr); ok { return exprToTypeStringRecursively(selExpr.X) + "." + exprToTypeStringRecursively(selExpr.Sel) } else if star, ok := expr.(*ast.StarExpr); ok { return "*" + exprToTypeStringRecursively(star.X) } else if mapType, ok := expr.(*ast.MapType); ok { return "map[" + exprToTypeStringRecursively(mapType.Key) + "]" + exprToTypeStringRecursively(mapType.Value) } else if funcType, ok := expr.(*ast.FuncType); ok { params := parseFieldList(funcType.Params) results := parseFieldList(funcType.Results) tf := func (data []map [string ]string ) string ts := make ([]string , 0 ) for _, v := range data { ts = append (ts, v["Name" ]+" " +v["Type" ]) } return strings.Join(ts, "," ) } return "func(" + tf(params) + ")" + " (" + tf(results) + ")" } else if chanType, ok := expr.(*ast.ChanType); ok { if chanType.Dir == ast.SEND { return "chan <- " + exprToTypeStringRecursively(chanType.Value) } else if chanType.Dir == ast.RECV { return "<- chan " + exprToTypeStringRecursively(chanType.Value) } else { return "chan " + exprToTypeStringRecursively(chanType.Value) } } fmt.Println(expr) panic (1 ) } func parseFieldList (fList *ast.FieldList) []map [string ]string dst := make ([]map [string ]string , 0 ) if fList != nil { list := fList.List for i := 0 ; i < len (list); i++ { names := list[i].Names typeStr := exprToTypeStringRecursively(list[i].Type) for j := 0 ; j < len (names); j++ { dst = append (dst, map [string ]string { "Name" : names[j].Name, "Type" : typeStr, }) } if len (names) == 0 { dst = append (dst, map [string ]string { "Name" : "" , "Type" : typeStr, }) } } } return dst } func CreateASTFunctionFromASTNode (node ast.Node, pack string ) *ASTFunction fn, ok := node.(*ast.FuncDecl) if ok { astFunction := ASTFunction{ Package: pack, Name: fn.Name.Name, Exported: fn.Name.IsExported(), } astFunction.Params = parseFieldList(fn.Type.Params) astFunction.Results = parseFieldList(fn.Type.Results) astFunction.Recv = parseFieldList(fn.Recv) return &astFunction } return nil } func CreateASTFunctionsFromFile (target string ) []*ASTFunction rawData, err := ioutil.ReadFile(target) if err != nil { panic (exception.NewDefaultException(exception.IOException, err.Error())) } fileSet := token.NewFileSet() file, err := parser.ParseFile(fileSet, "" , string (rawData), 0 ) if err != nil { panic (exception.NewDefaultException(exception.ASTParseException, err.Error())) } pack := "" ast.Print(fileSet, file) functions := make ([]*ASTFunction, 0 ) ast.Inspect(file, func (node ast.Node) bool pk, ok := node.(*ast.Ident) if ok { if pack == "" { pack = pk.Name } } fn := CreateASTFunctionFromASTNode(node, pack) if fn != nil { functions = append (functions, fn) } return true }) return functions }
1 2 3 4 5 6 7 8 functions := util.CreateASTFunctionsFromFile("C:\\Program Files\\Go\\src\\go\\ast\\ast.go" ) for _, f := range functions { f.Println() }