gorp的update语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 func UpdateWebhook (src gorp.SqlExecutor, item *WebHook) error if item == nil { return nil } var build strings.Builder var args []interface {} build.WriteString("UPDATE webhook SET " ) if !utils.IsEmptyString(item.Name) { build.WriteString("`name`=?, " ) args = append (args, item.Name) } if !utils.IsEmptyString(item.URL) { build.WriteString("`url`=?, " ) args = append (args, item.URL) } if item.IsBatch != 0 { build.WriteString("`is_batch`=?, " ) args = append (args, item.IsBatch) } if item.BatchCount != 0 { build.WriteString("`batch_count`=?, " ) args = append (args, item.BatchCount) } if item.Status != 0 { build.WriteString("`status`=?, " ) args = append (args, item.Status) } build.WriteString(fmt.Sprintf("`update_time`=? WHERE uuid='%s';" , item.UUID)) args = append (args, time.Now().Unix()) _, err := src.Exec(build.String(), args...) if err != nil { return err } return nil }
gorp的事务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 func DBMTransact (src *gorp.DbMap, txFunc func (*gorp.Transaction) error ) (err error) tx, err := src.Begin() if err != nil { err = errors.Sql(err) return } defer func () if p := recover (); p != nil { log.Warn("%s: %s" , p, debug.Stack()) switch p := p.(type ) { case error: err = p default : err = fmt.Errorf("%s" , p) } } if err != nil { tx.Rollback() return } err = errors.Sql(tx.Commit()) }() return txFunc(tx) }
go的相对路径 1 2 3 4 go_test |-- mymod | |-- qweqe.txt |--aaa.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func main () p1 := "/Users/heyingliang/go/src/go_test/mymod/qweqe.txt" p2 := "./mymod/qweqe.txt" p3 := "mymod/qweqe.txt" f1, err := os.Open(p1) f2, err := os.Open(p2) f3, err := os.Open(p3) if err != nil { fmt.Printf("%s\n" , err) } Print(f1) Print(f2) Print(f3) }
./ 是你当前的project目录(即go_test)
mymod/qweqe.txt就是./mymod/qweqe.txt
Go不能跨包写方法 新建a和b两个文件夹.再分别新建2个文件a.go , b.go
a/a.go
1 2 3 4 package a type Student struct { Name String }
b/b.go
1 2 3 4 package b func (s a.Student) Show () fmt.Println(s.Name) }
main.go
1 2 3 4 5 func main () { student := new (a.Student) student.Name = "百里" student.Show () // (1 ) 会报错的. }
new和make的区别
new(T) 返回的是 T 的指针:
new(T) 为一个 T 类型新值分配空间并将此空间初始化为 T 的零值,返回的是新值的地址,也就是 T 类型的指针 *T,该指针指向 T 的新分配的零值。
1 2 3 4 5 6 7 8 9 10 11 12 13 p1 := new (int ) fmt.Printf("p1 --> %#v \n " , p1) fmt.Printf("p1 point to --> %#v \n " , *p1) var p2 *int i := 0 p2 = &i fmt.Printf("p2 --> %#v \n " , p2) fmt.Printf("p2 point to --> %#v \n " , *p2) p1 := new (int ) var p2 *int
make 只能用于 slice,map,channel:
**make(T, args) 返回的是初始化之后的 T 类型的值,这个新值并不是 T 类型的零值,也不是指针 *T,是经过初始化之后的 T 的引用**。
1 2 3 4 5 6 7 8 9 10 11 var s1 []int if s1 == nil { fmt.Printf("s1 is nil --> %#v \n " , s1) } s2 := make ([]int , 3 ) if s2 == nil { fmt.Printf("s2 is nil --> %#v \n " , s2) } else { fmt.Printf("s2 is not nill --> %#v \n " , s2) }
slice 的零值是 nil,使用 make 之后 slice 是一个初始化的 slice,即 slice 的长度、容量、底层指向的 array 都被 make 完成初始化,此时 slice 内容被类型 int 的零值填充,形式是 [0 0 0],map 和 channel 也是类似的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 var m1 map [int ]string if m1 == nil { fmt.Printf("m1 is nil --> %#v \n " , m1) } m2 := make (map [int ]string ) if m2 == nil { fmt.Printf("m2 is nil --> %#v \n " , m2) } else { fmt.Printf("m2 is not nill --> %#v \n " , m2) } var c1 chan string if c1 == nil { fmt.Printf("c1 is nil --> %#v \n " , c1) } c2 := make (chan string ) if c2 == nil { fmt.Printf("c2 is nil --> %#v \n " , c2) } else { fmt.Printf("c2 is not nill --> %#v \n " , c2) }
变量生命周期 对于在包一级声明的变量来说,它们的生命周期和整个程序的运行周期是一致的。
刻意区分类型 1 2 3 4 5 6 7 8 9 10 11 type Celsius float64 type Fahrenheit float64 const ( AbsoluteZeroC Celsius = -273.15 FreezingC Celsius = 0 BoilingC Celsius = 100 ) func CToF (c Celsius) Fahrenheit return Fahrenheit(c*9 /5 + 32 ) }func FToC (f Fahrenheit) Celsius return Celsius((f - 32 ) * 5 / 9 ) }
刻意区分类型,可以避免一些像无意中使用不同单位的温度混合计算导致的错误;因此需要一个类似**Celsius(t)或 Fahrenheit(t)**形式的显式转型操作才能将float64转为对应的类型。
Celsius(t)和Fahrenheit(t)是类型转换操作,它们并不是函数调用。类型转换不会改变值本身,但是会使它们的语义发生变化 。
go不遵守python的LEGB原则
python的LEGB是:内层变量只能读取,不能改变外层变量
但是go允许内层变量修改外穿变量的值
1 2 3 4 5 6 7 8 9 var char = 1 func myfunc () char = 2 } func main () fmt.Println(char) myfunc() fmt.Println(char) }
go mod 如果出现go mod download失败,
1 2 export GO111MODULE=onexport GOPROXY=https://goproxy.io
之后再执行go mod download
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 func parserTimeStr (stringTime string ) (int64 , error) loc, _ := time.LoadLocation("Local" ) formats := []string { "2006-01-02" , "2006-01-02 15:04" , "2006-01-02 15:04:05" , "2006-1-2" , "2006-1-02" , "2006-01-2" , "01/02/2006" , "1/02/2006" , "01/2/2006" , "1/2/2006" , "01/02/2006 15:04" , "1/02/2006 15:04" , "01/2/2006 15:04" , "1/2/2006 15:04" , "01/02/2006 15:04:05" , "1/02/2006 15:04:05" , "01/2/2006 15:04:05" , "1/2/2006 15:04:05" , "2006/01/02" , "2006/1/02" , "2006/01/2" , "2006/1/2" , "2006/01/02 15:04" , "2006/1/02 15:04" , "2006/01/2 15:04" , "2006/1/2 15:04" , "2006/01/02 15:04:05" , "2006/1/02 15:04:05" , "2006/01/2 15:04:05" , "2006/1/2 15:04:05" , } for _, format := range formats { t, err := time.ParseInLocation(format, stringTime, loc) if err == nil { return t.Unix(), nil } } return 0 , errors.New("parse time error" ) }
limit,offset的常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 type Block struct { Since int End int } var DefaultBlockSize = 10 func NewBlocks (length int , blockSize int ) Blocks blocks := []*Block{} if blockSize <= 0 { return blocks } since := 0 for i := 0 ; i < length; { i += blockSize if i > length { i = length } blocks = append (blocks, &Block{Since: since, End: i}) since = i } return blocks } func (b *Block) Range () int return b.End - b.Since } func NewDefaultBlocks (length int ) []*Block return NewBlocks(length, DefaultBlockSize) } type Blocks []*Blockfunc (b Blocks) Each (f func (block *Block) error ) error for i := range b { err := f(b[i]) if err != nil { return errors.Trace(err) } } return nil }
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 sqlSample := "SELECT %s FROM activity WHERE team_uuid=? AND related_ppm_task_uuid IN (%s) AND status=?;" blocks := utilsModel.NewBlocks(length, defaultBlockSize) for _, block := range blocks { subPPMTaskUUIDs := ppmTaskUUIDs[block.Since:block.End] sql := fmt.Sprintf(sqlSample, activityColumnsStr, utilsModel.SqlPlaceholds(len (subPPMTaskUUIDs))) activities := make ([]*Activity, 0 ) args, _ := utilsModel.BuildSqlArgs(teamUUID, subPPMTaskUUIDs, ActivityNormal) _, err := src.Select(&activities, sql, args...) if err != nil { return nil , errors.Sql(err) } results = append (results, activities...) }
BuildSqlArgs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 func BuildSqlArgs (args ...interface {}) ([]interface {}, error) newArgs := make ([]interface {}, 0 ) addEleFun := func (ele interface {}) newArgs = append (newArgs, ele) return } for _, arg := range args { switch v := arg.(type ) { case string , int , int32 , int64 , bool , *string , *int , *int32 , *int64 , time.Time: addEleFun(v) case []string : for _, e := range v { addEleFun(e) } case []int : for _, e := range v { addEleFun(e) } case []int32 : for _, e := range v { addEleFun(e) } case []int64 : for _, e := range v { addEleFun(e) } case []*string : for _, e := range v { addEleFun(e) } case nil : addEleFun(v) default : return nil , errors.TypeMismatchError(arg, "string" , "int" , "int32" , "int64" , "bool" , "*string" , "*int" , "*int32" , "*int64" , "[]string" , "[]int" , "[]int32" , "[]int64" , "[]string" , "nil" ) } } return newArgs, nil }
使用:
1 2 3 4 sql := "SELECT user_uuid FROM sync_user WHERE corp_uuid=? AND sync_id IN(%s) AND status!=?;" sql = fmt.Sprintf(sql, utilsModel.SqlPlaceholds(length)) args, _ := utilsModel.BuildSqlArgs(corpUUID, syncIDs[block.Since:block.End], utilsModel.SyncUserStatusDelete) _, err := src.Select(&data, sql, args...)
golang的继承复用 BaseExector只实现了GetUpdateKeys(),其他ValidateAndPrepare,Commit,SuccessCallback,AsyncSuccessCallback,GetUserUUID交由子类实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type Executer interface { GetUpdateKeys() *UpdateKeys ValidateAndPrepare(src gorp.SqlExecutor) error Commit(*gorp.Transaction) (interface {}, error) SuccessCallback() AsyncSuccessCallback() GetUserUUID() string } type BaseExecutor struct { UpdateKeys Task *taskModel.Task Transition *workflow.Transition TeamUUID string UserUUID string } func (e BaseExecutor) GetUpdateKeys () *UpdateKeys return &e.UpdateKeys }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 type DiscussionExecutor struct { executors.BaseExecutor Discussion *SendMessageRequest message *messageModel.Message resource *resourceModel.FileResource mentions []string projectUsers []string isPushMessage bool } func (e *DiscussionExecutor) ValidateAndPrepare (src gorp.SqlExecutor) (result error) ... } func (e *DiscussionExecutor) GetUserUUID () string return e.UserUUID } type FieldValueExecutor struct { executors.BaseExecutor FieldValues []*field.FieldRawValue messages []*push.PendingMessage asyncMessages []*message.AsyncMessagePayload helper *TaskHelper } func (e *FieldValueExecutor) GetUserUUID () string return e.UserUUID }
使用流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 func main () arg := "a" Executor := BuildExecutors(arg) otherArg := "b" DoService(otherArg, Executor) } func BuildExecutors (arg string ) Executer var e Executer switch arg { case "a" : e = NewResourceExecutor(arg) case "b" : e = NewDiscussionExecutor(arg) } return e } func DoService (arg string , e Executor) RunSuccessCallback(e) } func RunSuccessCallback (e Executer) e.SuccessCallback() go func () defer func () if err := recover (); err != nil { log.Error("%s\n%s\n" , err, debug.Stack()) } }() e.AsyncSuccessCallback() }() }
slice append避免使用var 1 2 3 4 5 6 7 8 9 func main () var s []string arr := []string {"1" , "2" } for _, ele := range arr { s = append (s) } }
优化如下:
1 2 3 4 5 6 7 8 9 10 func main () s := make ([]string , 0 , 1 ) arr := []string {"1" , "2" } for _, ele := range arr { s = append (s) } }
复制 struct pointer 1 2 3 var start *Pointa := start c := start
1 2 3 4 var start *Pointa := start c := *start d := &c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 type FieldTypeEnumConverter struct { byLabel map [string ]int byEnum map [int ]string } func NewDefaultFieldTypeEnumConverter () *FieldTypeEnumConverter c := NewFieldTypeEnumConverter() c.Set(FieldTypeOption, 1 ) c.Set(FieldTypeText, 2 ) return c } func (c *FieldTypeEnumConverter) Set (label string , enum int ) c.byLabel[label] = enum c.byEnum[enum] = label } func (c *FieldTypeEnumConverter) Enum (label string ) (int , error) if enum, ok := c.byLabel[label]; ok { return enum, nil } else { return 0 , fmt.Errorf("invalid filed type" ) } } func (c *FieldTypeEnumConverter) Label (enum int ) (string , error) if label, ok := c.byEnum[enum]; ok { return label, nil } else { return "" , fmt.Errorf("invalid filed type" ) } }
通过reflect获取structName来进行判断 在scrapy中,spider的parse()方法可以yield Item/yield Request,这一点在Golang中如何实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type Response interface { Url() string Body() []byte Meta() map [string ]interface {} Copy() Replace() UrlJoin(url string ) Text() string CSS() string XPath(args []string , kwargs []string ) interface {} Follow() *request.Request } func (ee *ExecutionEngine) handleDownloaderOutput (resp response.Response) interface if reflect.TypeOf(resp).Name() == "Request" { ee.Crawl(req, spider) return nil } ee.scraper.EnqueueScrape(resp, req, spider) return nil }
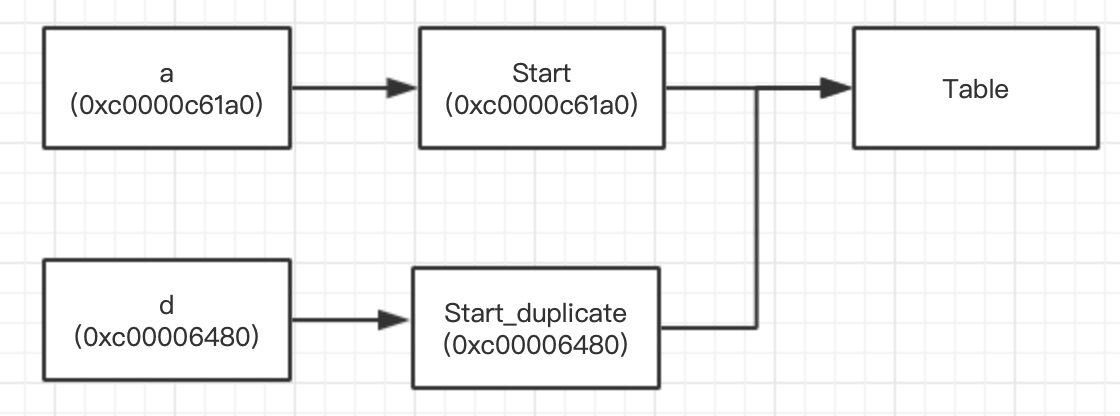
通过抽出一层来解决所属不清的问题 现有一个围棋游戏,point有:
isValid()方法用于判断是否超出棋盘,
left()方法用于获取该点左边的点
这两个方法都需要用到Table,但是给isValid传入table变量又是一件很奇怪的事。
此时就可以将Table提升为全局变量,通过抽出一层来解决
1 2 3 4 5 6 7 8 9 10 11 12 type GameTable struct { xLen int yLen int } type Point struct { x int y int } func (p *Point) IsVaild (table Table) bool
1 2 3 4 5 6 var Table = NewGameTable(...)func (p *Point) IsVaild () bool if Table[p.x][p.y] == .... }
报错exit status 1
log.Fatal()会导致程序(调用os.Exit(1))退出->退出返回值为1
log.Panic()会导致挂掉(且会打印出panic时的信息)并退出->退出返回值为2
https://stackoverflow.com/questions/18159704/how-to-debug-exit-status-1-error-when-running-exec-command-in-golang/18159705
向无缓冲的 channel 发送数据,只要 receiver 准备好了就会立刻返回 只有在数据被 receiver 处理时,sender 才会阻塞。因运行环境而异,在 sender 发送完数据后,receiver 的 goroutine 可能没有足够的时间处理下一个数据。如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func main () ch := make (chan string ) go func () for m := range ch { fmt.Println("Processed:" , m) time.Sleep(1 * time.Second) } }() ch <- "cmd.1" ch <- "cmd.2" }
在 range 迭代 slice、array、map 时通过更新引用来更新元素 在 range 迭代中,得到的值其实是元素的一份值拷贝,更新拷贝并不会更改原来的元素,即是拷贝的地址并不是原有元素的地址:
1 2 3 4 5 6 7 func main () data := []int {1 , 2 , 3 } for _, v := range data { v *= 10 } fmt.Println("data: " , data) }
如果要修改原有元素的值,应该使用索引直接访问:
1 2 3 4 5 6 7 func main () data := []int {1 , 2 , 3 } for i, v := range data { data[i] = v * 10 } fmt.Println("data: " , data) }
如果你的集合保存的是指向值的指针,需稍作修改。依旧需要使用索引访问元素,不过可以使用 range 出来的元素直接更新原有值:
1 2 3 4 5 6 7 func main () data := []*struct { num int }{{1 }, {2 }, {3 },} for _, v := range data { v.num *= 10 } fmt.Println(data[0 ], data[1 ], data[2 ]) }
defer 函数的执行时机 对 defer 延迟执行的函数,会在调用它的函数结束时执行,而不是在调用它的语句块结束时执行,注意区分开。比如在一个长时间执行的函数里,内部 for 循环中使用 defer 来清理每次迭代产生的资源调用,就会出现问题。
解决办法:defer 延迟执行的函数写入匿名函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func main () for _, target := range targets { func () f, err := os.Open(target) if err != nil { fmt.Println("bad target:" , target, "error:" , err) return } defer f.Close() }() } }
匿名函数中的循环变量快照问题 1 2 3 4 5 6 7 8 9 10 11 12 13 func makeThumbnails3 (filenames []string ) ch := make (chan struct {}) for _, f := range filenames { go func (f string ) thumbnail.ImageFile(f) ch <- struct {}{} }(f) } for range filenames { <-ch } }
注意我们将f的值作为一个显式的变量传给了函数,而不是在循环的闭包中声明:
1 2 3 4 5 6 for _, f := range filenames { go func () thumbnail.ImageFile(f) }() }
上面这个单独的变量f是被所有的匿名函数值所共享,且会被连续的循环迭代所更新 的。当新的goroutine开始执行字面函数时,for循环可能已经更新了f并且开始了另一轮的迭代或者(更有可能的)已经结束了整个循环,所以当这些goroutine开始读取f的值时,它们所看到的值已经是slice的最后一个元素了。 显式地添加这个参数,我们能够确保使用的f是当go语句执行时的“当前”那个f。
部分Unmarshal 好处有二:
提高性能
避免因为struct缺少某些字段,在marshal时字段丢失
对于IssueTypeDefaultConfigs这个原struct,假设我们只需要修改default_field_configs字段:
1 2 3 4 5 6 7 8 9 10 type IssueTypeDefaultConfigs struct { DefaultFieldConfigs []*DefaultFieldConfig `json:"default_field_configs"` DefaultImportantFields []string `json:"default_important_fields"` DefaultTaskStatusConfigs []*DefaultTaskStatusConfig `json:"default_task_status_configs"` DefaultTransitions []*DefaultTransition `json:"default_transitions"` DefaultPermissions []*DefaultPermission `json:"default_permission"` DefaultNoticeRules []*DefaultNoticeRule `json:"default_notice_rules"` DefaultTabConfigs []*DefaultTabConfig `json:"default_tab_configs"` DefaultLayout string `json:"layout_uuid"` }
可以如下使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 const ( planStartDateFieldUUID = "field027" planEndDateFieldUUID = "field028" productsFieldUUID = "field029" productModuleFieldUUID = "field030" ) type IssueTypeDefaultConfigsRaw map [string ]json.RawMessagefunc updateFieldsPosition (defaultConfigsByte []byte ) ([]byte , error) if len (defaultConfigsByte) == 0 { return defaultConfigsByte, nil } issueTypeDefaultConfigsMap := make (IssueTypeDefaultConfigsRaw) if err := json.Unmarshal(defaultConfigsByte, &issueTypeDefaultConfigsMap); err != nil { return nil , errors.Trace(err) } defaultFieldConfigsByte := issueTypeDefaultConfigsMap["default_field_configs" ] defaultFieldConfigs := make ([]*DefaultFieldConfig, 0 ) if err := json.Unmarshal(defaultFieldConfigsByte, &defaultFieldConfigs); err != nil { return nil , errors.Trace(err) } var planStartDateFieldIdx, planEndDateFieldIdx, productsFieldIdx, productModuleFieldIdx = -1 , -1 , -1 , -1 for idx, defaultConfig := range defaultFieldConfigs { switch defaultConfig.FieldUUID { case planStartDateFieldUUID: planStartDateFieldIdx = idx case planEndDateFieldUUID: planEndDateFieldIdx = idx case productsFieldUUID: productsFieldIdx = idx case productModuleFieldUUID: productModuleFieldIdx = idx } } if planStartDateFieldIdx != -1 && planEndDateFieldIdx != -1 && planStartDateFieldIdx > planEndDateFieldIdx { defaultFieldConfigs[planStartDateFieldIdx], defaultFieldConfigs[planEndDateFieldIdx] = defaultFieldConfigs[planEndDateFieldIdx], defaultFieldConfigs[planStartDateFieldIdx] } if productsFieldIdx != -1 && productModuleFieldIdx != -1 && productsFieldIdx > productModuleFieldIdx { defaultFieldConfigs[productsFieldIdx], defaultFieldConfigs[productModuleFieldIdx] = defaultFieldConfigs[productModuleFieldIdx], defaultFieldConfigs[productsFieldIdx] } defaultFieldConfigsByte, err := json.Marshal(defaultFieldConfigs) if err != nil { return nil , errors.Trace(err) } issueTypeDefaultConfigsMap["default_field_configs" ] = defaultFieldConfigsByte defaultConfigsByte, err = json.Marshal(issueTypeDefaultConfigsMap) if err != nil { return nil , errors.Trace(err) } return defaultConfigsByte, nil } type DefaultFieldConfig struct { FieldUUID string `json:"field_uuid"` Required bool `json:"required"` CanDelete bool `json:"can_delete"` CanModifyRequired bool `json:"can_modify_required"` Position int64 `json:"-"` }
判断是否实现某个接口(接口类型检测) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "io" type myWriter struct {}func (w myWriter) Write (p []byte ) (n int , err error) return } func main () var _ io.Writer = (*myWriter)(nil ) var _ io.Writer = (*myWriter){} }
方法二好理解, 方法一如何看待?
(*T)(nil)其实是类型转换。
正常的类型转换是T(expr),如string(a),但是取址符号*的优先级更高,因此*T(expr)需要写成(*T)(expr)
所以(*T)(nil)就很好理解了,这里就是将nil转换为*T类型。
一个变量是具有类型和地址两个属性,强制类型转换只修改了类型,但是地址是原来那个(例如是nil),经过这样转换的变量不用重新分配地址。
例如下列代码:
1 2 3 4 var _ Context = (*ContextBase)(nil )var b string = string (nil )
nil的类型是nil, 地址值为0,利用强制类型转换成了*ContextBase,返回的变量就是类型为*ContextBase,地址值为0,然后Context=xx赋值。如果xx实现了Context接口就没事,如果没有实现在编译时期就会报错,实现编译期间检测接口是否实现。
同一个包有两个main包 该出错原因属于go 的多文件加载问题,采用go run 命令执行的时候,需要把待加载的**.go**文件都包含到参数里面
1 2 3 4 5 6 7 8 ... ├── frpc │ ├── frpc.go │ └── main.go ├── frps │ ├── frps.go │ └── main.go ...
1 2 go run main.go frps.go go run main.go frpc.go
或者
阻塞轮询接口状态 在timeout时间内,阻塞并轮询接口状态,只有当状态正常时才解开阻塞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package mainimport ( "fmt" "math/rand" "time" ) func main () rand.Seed(time.Now().Unix()) ok := <-wait() if ok { fmt.Println("wait ok" ) } else { fmt.Println("wait failed" ) } } func wait () chan bool waitChan := make (chan bool ) timeout := 10 runTime := 0 checkInterval := 1 checkTimer := time.NewTimer(time.Duration(checkInterval) * time.Second) go func () for { <-checkTimer.C ok := checkAPIStatus() if ok { waitChan <- true return } runTime += checkInterval if runTime > timeout { waitChan <- false return } checkTimer.Reset(time.Duration(checkInterval) * time.Second) } }() return waitChan } func checkAPIStatus () bool result := rand.Intn(10 ) return result == 1 }
灵活控制返回的时机 将上面的 <-wait() 封装成返回自己,就可以得到如下的代码,这也是 net/rpc 库的写法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package mainimport ( "fmt" "net/http" ) type Context struct { request *http.Request response *http.Response Done chan *Context } func NewContext (request *http.Request) *Context return &Context{ request: request, Done: make (chan *Context, 1 ), } } func (c *Context) done () c.Done <- c } func (c *Context) send () *Context client := &http.Client{} res, _ := client.Do(c.request) c.response = res c.done() return c } func (c *Context) Go () *http .Response context := <-c.send().Done return context.response } func main () req, _ := http.NewRequest("GET" , "baidu.com" , nil ) c := NewContext(req) response := c.Go() fmt.Println(response) }
注意,上面的 response := c.Go() 只有等到调用 c.done(),才能返回,这样就能灵活的控制返回的时机 。
比如说,如果有一个 Client struct,负责发送 Context,那么就可以交由 Client 执行 c.done(),这样 Client 就能准确的知道每一个 Context 的返回时机。
总结:对于不定时间返回的SomeFunc,可以返回一个chan,用来标志返回的时机。可以对比 Call1 和 Call2
1 2 3 4 5 func Call1 () string someThing := doSomeSyncTime() return someThing }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func SomeFunc () chan string waitChan := make (chan string ) go func () someThing := doSomeSyncTime() waitChan <- someThing }() return waitChan } func Call2 () string data := <- SomeFunc() return data }
1 2 3 4 5 func main () data1 := Call1() data2 := Call2() }
json.Unmarshal() 传入 reflect.New(v).Interface() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package mainimport ( "encoding/json" "fmt" "log" "reflect" ) type Body struct { Message string } func main () body := Body{Message: "123123123" } b, err := json.Marshal(body) if err != nil { log.Println(err) } ret := new (Body) err = json.Unmarshal(b, &ret) if err != nil { log.Println(err) } fmt.Println(ret) v := reflect.TypeOf(ret) ret2 := reflect.New(v).Interface() err = json.Unmarshal(b, &ret2) if err != nil { log.Println(err) } fmt.Println(ret) }
导包路径问题 通常情况下,import的包都是相对$GOPATH/src目录引入的。比如从github上面clone下来的项目,直接放到$GOPATH/src目录下,就可以直接import。
如果项目的import路径是这样写的:import "github.com/yourname/projectname",需要将项目代码放置在:$GOAPTH/src/github.com/yourname/projectname/下
如果项目的import是这样写的:import "message",则将message.go放到:$GOAPTH/src/message/目录下即可。
getFreePort 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import "net" func GetFreePort () (int , error) addr, err := net.ResolveTCPAddr("tcp" , "localhost:0" ) if err != nil { return 0 , err } l, err := net.ListenTCP("tcp" , addr) if err != nil { return 0 , err } defer l.Close() return l.Addr().(*net.TCPAddr).Port, nil } func GetFreePorts (count int ) ([]int , error) var ports []int for i := 0 ; i < count; i++ { addr, err := net.ResolveTCPAddr("tcp" , "localhost:0" ) if err != nil { return nil , err } l, err := net.ListenTCP("tcp" , addr) if err != nil { return nil , err } defer l.Close() ports = append (ports, l.Addr().(*net.TCPAddr).Port) } return ports, nil }
更高效率的string2bytes 1 2 3 4 5 6 7 8 9 func ToString (p []byte ) string return *(*string )(unsafe.Pointer(&p)) } func ToBytes (str string ) []byte return *(*[]byte )(unsafe.Pointer(&str)) }
1 2 3 4 5 6 7 8 9 10 11 12 13 func BenchmarkToBytes (b *testing.B) for i := 0 ; i <= b.N; i++ { _ = ToBytes(str) } } func BenchmarkBytes (b *testing.B) for i := 0 ; i <= b.N; i++ { _ = []byte (str) } }
writer 的进度条 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package mainimport ( "fmt" "io" "net/http" "os" "strings" ) type WriteCounter struct { Total uint64 } func (wc *WriteCounter) Write (p []byte ) (int , error) n := len (p) wc.Total += uint64 (n) wc.PrintProgress() return n, nil } func (wc WriteCounter) PrintProgress () fmt.Printf("\r%s" , strings.Repeat(" " , 35 )) fmt.Printf("\rDownloading... %d Byte" , wc.Total) } func DownloadFile (filepath string , url string ) error out, err := os.Create(filepath + ".tmp" ) if err != nil { return err } resp, err := http.Get(url) if err != nil { out.Close() return err } defer resp.Body.Close() counter := &WriteCounter{} if _, err = io.Copy(out, io.TeeReader(resp.Body, counter)); err != nil { out.Close() return err } fmt.Print("\n" ) out.Close() if err = os.Rename(filepath+".tmp" , filepath); err != nil { return err } return nil } func main () fmt.Println("Download Started" ) fileUrl := "https://dl.google.com/go/go1.11.1.src.tar.gz" err := DownloadFile("go1.11.1.src.tar.gz" , fileUrl) if err != nil { panic (err) } fmt.Println("Download Finished" ) }