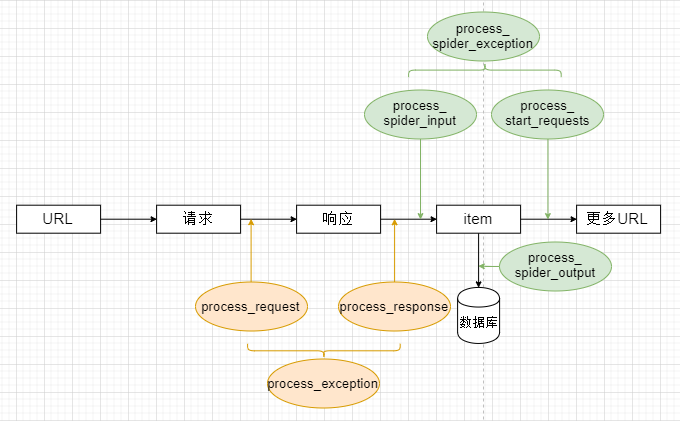
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
| class ImagesPipeline(FilesPipeline):
"""Abstract pipeline that implement the image thumbnail generation logic
"""
MEDIA_NAME = 'image'
MIN_WIDTH = 0
MIN_HEIGHT = 0
THUMBS = {}
DEFAULT_IMAGES_URLS_FIELD = 'image_urls'
DEFAULT_IMAGES_RESULT_FIELD = 'images'
@classmethod
def from_settings(cls, settings):
cls.MIN_WIDTH = settings.getint('IMAGES_MIN_WIDTH', 0)
cls.MIN_HEIGHT = settings.getint('IMAGES_MIN_HEIGHT', 0)
cls.EXPIRES = settings.getint('IMAGES_EXPIRES', 90)
cls.THUMBS = settings.get('IMAGES_THUMBS', {})
s3store = cls.STORE_SCHEMES['s3']
s3store.AWS_ACCESS_KEY_ID = settings['AWS_ACCESS_KEY_ID']
s3store.AWS_SECRET_ACCESS_KEY = settings['AWS_SECRET_ACCESS_KEY']
cls.IMAGES_URLS_FIELD = settings.get('IMAGES_URLS_FIELD', cls.DEFAULT_IMAGES_URLS_FIELD)
cls.IMAGES_RESULT_FIELD = settings.get('IMAGES_RESULT_FIELD', cls.DEFAULT_IMAGES_RESULT_FIELD)
store_uri = settings['IMAGES_STORE']
return cls(store_uri)
def file_downloaded(self, response, request, info):
return self.image_downloaded(response, request, info)
def image_downloaded(self, response, request, info):
checksum = None
for path, image, buf in self.get_images(response, request, info):
if checksum is None:
buf.seek(0)
checksum = md5sum(buf)
width, height = image.size
self.store.persist_file(
path, buf, info,
meta={'width': width, 'height': height},
headers={'Content-Type': 'image/jpeg'})
return checksum
def get_images(self, response, request, info):
path = self.file_path(request, response=response, info=info)
orig_image = Image.open(StringIO(response.body))
width, height = orig_image.size
if width < self.MIN_WIDTH or height < self.MIN_HEIGHT:
raise ImageException("Image too small (%dx%d < %dx%d)" %
(width, height, self.MIN_WIDTH, self.MIN_HEIGHT))
image, buf = self.convert_image(orig_image)
yield path, image, buf
for thumb_id, size in self.THUMBS.iteritems():
thumb_path = self.thumb_path(request, thumb_id, response=response, info=info)
thumb_image, thumb_buf = self.convert_image(image, size)
yield thumb_path, thumb_image, thumb_buf
def convert_image(self, image, size=None):
if image.format == 'PNG' and image.mode == 'RGBA':
background = Image.new('RGBA', image.size, (255, 255, 255))
background.paste(image, image)
image = background.convert('RGB')
elif image.mode != 'RGB':
image = image.convert('RGB')
if size:
image = image.copy()
image.thumbnail(size, Image.ANTIALIAS)
buf = StringIO()
image.save(buf, 'JPEG')
return image, buf
def get_media_requests(self, item, info):
return [Request(x) for x in item.get(self.IMAGES_URLS_FIELD, [])]
def item_completed(self, results, item, info):
if self.IMAGES_RESULT_FIELD in item.fields:
item[self.IMAGES_RESULT_FIELD] = [x for ok, x in results if ok]
return item
def file_path(self, request, response=None, info=None):
def _warn():
from scrapy.exceptions import ScrapyDeprecationWarning
import warnings
warnings.warn('ImagesPipeline.image_key(url) and file_key(url) methods are deprecated, '
'please use file_path(request, response=None, info=None) instead',
category=ScrapyDeprecationWarning, stacklevel=1)
if not isinstance(request, Request):
_warn()
url = request
else:
url = request.url
if not hasattr(self.file_key, '_base'):
_warn()
return self.file_key(url)
elif not hasattr(self.image_key, '_base'):
_warn()
return self.image_key(url)
image_guid = hashlib.sha1(url).hexdigest()
return 'full/%s.jpg' % (image_guid)
def thumb_path(self, request, thumb_id, response=None, info=None):
def _warn():
from scrapy.exceptions import ScrapyDeprecationWarning
import warnings
warnings.warn('ImagesPipeline.thumb_key(url) method is deprecated, please use '
'thumb_path(request, thumb_id, response=None, info=None) instead',
category=ScrapyDeprecationWarning, stacklevel=1)
if not isinstance(request, Request):
_warn()
url = request
else:
url = request.url
if not hasattr(self.thumb_key, '_base'):
_warn()
return self.thumb_key(url, thumb_id)
thumb_guid = hashlib.sha1(url).hexdigest()
return 'thumbs/%s/%s.jpg' % (thumb_id, thumb_guid)
def file_key(self, url):
return self.image_key(url)
file_key._base = True
def image_key(self, url):
return self.file_path(url)
image_key._base = True
def thumb_key(self, url, thumb_id):
return self.thumb_path(url, thumb_id)
thumb_key._base = True
|