第 1 章 对程序员来说 CPU 是什么
CPU 的内部结构
- CPU 的内部由
寄存器、控制器、运算器和时钟四个部分构成,各部分之间由电流信号相互连通。 - 寄存器:可用来暂存指令、数据等处理对象,可以将其看 作是内存的一种。根据种类的不同,一个 CPU 内部会有 20~100 个寄存器。
- 控制器:负责把内存上的指令、数据等读入寄存器,并根据指令的执行结果来控制整个计算机。
- 运算器:负责运算从内存读入寄存器的数据。
- 时钟:负责发出 CPU 开始计时的时钟信号。不过,也有些计算机的时钟位于 CPU 的外部。
程序启动后,根据时钟信号,控制器会从内存中读取指令和数据。通过对这些指令加以解释和运行,运算器就会对数据进行运算, 控制器根据该运算结果来控制计算机。
看到“控制”一词时,大家可能会将事情想象得过于复杂,其实所谓的控制就是指数据运算以外的处理(主要是数据输入输出的时机控制)。比如内存和磁盘等媒介的输入输出、键盘和鼠标的输入、显示器和打印机的输出等,这些都是控制的内容。
- 程序是把寄存器作为对象来描述的。
- 哪怕是高级语言编写的程序,函数调用处理也是通过把程序计数器的值设定成函数的存储地址来实现的。
第 2 章 数据是用二进制数表示的
算术和逻辑两个术语的区别
- 在运算中,与
逻辑相对的术语是算术。 - 我们不妨这样考虑,将二进制数表示的信息作为四则运算的数值来处理就是算术,而像图形模式那样,将数值处理为单纯的 0 和 1 的罗列就是逻辑 。
- 计算机能处理的运算,大体可分为
算术运算和逻辑运算。算术运算是指加减乘除四则运算。逻辑运算是指对二进制数各数字位的 0 和 1 分别进行处理的运算,包括逻辑非(NOT 运算)、逻辑与(AND 运 算)、逻辑或(OR 运算)和逻辑异或(XOR 运算 )四种。
第 3 章 计算机进行小数运算时出错的原因
如何避免计算机计算出错
把小数转换成整数来计算。
计算机在进行小数计算时可能会出错,但进行整数计算(只要不超过可处理的数值范围)时一定不会出现问题。因此,进行小数的计算时可以暂时使用整数,然后再把计算结果用小数表示出来即可。
例如,将 0.1 相 加 100 次这一计算,就可以转换为将 0.1 扩大 10 倍后再将 1 相加 100 次的计算,最后把结果除以 10 就可以了。
使用BCD(Binary Coded Decimal):用 4 位来表示 0~9 的 1 位数字
第 4 章 熟练使用有棱有角的内存
高级语言中数据类型的本质
高级编程语言中的数据类型表示的是什么?占据内存区域的大小和存储在该内存区域的数据类型。
第 5 章 内存和磁盘的亲密关系
虚拟内存
- 虚拟内存虽说是把磁盘作为内存的一部分来使用,但实际上正在运行的程序部分,在这个时间点上是必须存在在内存中的。
- 也就是说,为了实现虚拟内存,就必须把实际内存 (也可称为物理内存 )的内容,和磁盘上的虚拟内存的内容进行部分置换(swap),并同时运行程序。
虚拟内存的方法有 分页式 和分段式 两种:
- 分段式是指,把要运行的程序分割成以处理集合及数据集合等为单位的段落,然后再以分割后的段落为单位在内存和磁盘之间进行数据置换。
- 分页式是指,在不考虑程序构造的情况下,把运行的程序按照一定大小的页(page) 进行分割,并以页为单位在内存和磁盘间进行置换。Windows 计算机的页的大小是 4KB。也就是说,把大程序用 4KB 的页来进行切分,并以页为单位放入磁盘(虚拟 内存)或内存中。
通过 DLL 文件实现函数共有来节约内存
通过多个应用共有同一个 DLL 文件可以达到节约内存的效果。
有一个函数 MyFunc()。应用 A 和应用 B 都会使用这个函数。在各个应用的运行文件中内置函数 MyFunc()(这个称为 Static Link,静态链接)后同时运行这两个应用, 内存中就存在了具有同一函数的两个程序。但这会导致内存的利用效率降低。
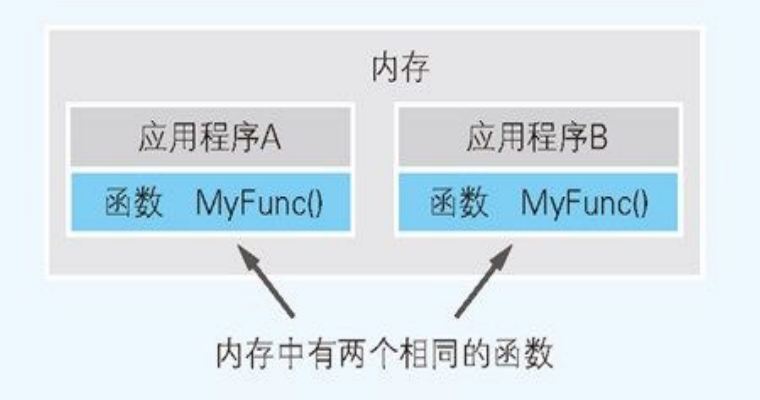
如果函数 MyFunc() 是独立的 DLL 文件而不是应用的执行文件 (EXE 文件)。由于同一个 DLL 文件的内容在运行时可以被多个应用共有,因此内存中存在的函数 MyFunc() 的程序就 只有 1 个。这样一来,内存的利用效率也就提高了。
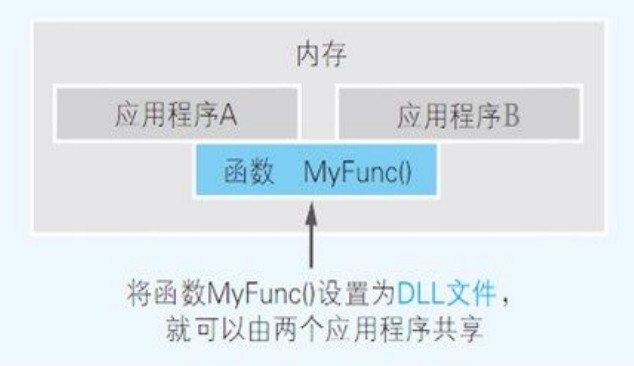
Windows 的操作系统本身也是多个 DLL 文件的集合体。有时在安装新应用时,DLL 文件也会被追加。应用则会通过利用这些 DLL 文件的功能来运行。之所以要利用多个 DLL 文件,其中一个原因就是可以节约内存。而且 DLL 文件还有一个优点就是,在不变更 EXE 文件的情况下,只通过升级 DLL 文件就可以更新。
栈清理处理
- C 语言中,在调用函数后,需要执行栈清理处理指令。
栈清理处理是指,把不需要的数据从接收和传递函数的参数时使用的内存上的栈区域中清理出去。- 该命令不是程序记述的,而是在程序编译时由编译器自动附加到程序中的。编译器默认将该处理附加在函数调用方。
1 | // 函数调用方 |
上述代码对应的汇编程序:
1 | push 1C8h # 将参数456(=1c8h)入栈 |
- C 语言通过栈来传递函数的参数。push是往栈中存入数据的指令。32 位 CPU 中,1 次 push 指令可以存储 4 个字节的数据。
- 由于使用了两次 push 指令把两个参数(456 和 123)存入到了栈中,因此存储了 8 字节的数据。通过 call 指令调用函数 MyFunc() 后,栈中存储的数据就不再需要了。于是这时就通过
add esp, 8这个指令,使存储着栈数据的 esp 寄存器前进 8 位(设定为指向高 8 位字节地址),来进行数据清理。由于栈是在各种情况下都可以再利用的内存领域,因此使用完毕后有必要将其恢复到原状态。上述这些操作就是栈的清理处理。 - 另外,在 C 语言中,函数的返回值,是通过寄存器而非栈来返回的。
说人话:所谓的
栈清理指的就是add esp, 8这句汇编代码。
通过调用 _stdcall 来减小程序文件的大小
通过调用
_stdcall来减小程序文件的方法,是用 C 语言编写应用时可以利用的高级技巧,也可以应用在其他编程语言中。_stdcall是 standard call(标准调用)的略称。Windows 提供的 DLL 文件内的函数,基本上都是 _stdcall 调用方式。这主要是为了节约内存。另一方面,用 C 语言编写的程序内的函数,默认设置都不是 _stdcall。C 语言特有的调用方式称为 C 调用。C 语言之所以 默认不使用 _stdcall,是因为 C 语言所对应的函数的传入参数是可变的(可以设定任意参数),只有函数调用方才能知道到底有多少个参数,而这种情况下,栈的清理作业便无法进行。不过,在 C 语言中,如果函数的参数数量固定的话,指定 _stdcall 是没有任何问题的。
栈清理处理,比起在函数调用方进行,在反复被调用的函数一方进行时,程序整体要小一些。这时所使用的就是 _stdcall。在函数前加上 _stdcall,就可以把栈清理处理变为在被调用函数一方进行。把前面代码中的
int MyFunc(int a, int b)部分转成int _stdcall MyFunc(int a, int b)进行再编译后,add esp, 8就会在函数 MyFunc() 一方执行。虽然该处理只能节约 3 个字节(add esp, 8 是机器语的 3 个字节)的程序大小,不过在整个程序中还是有效果的。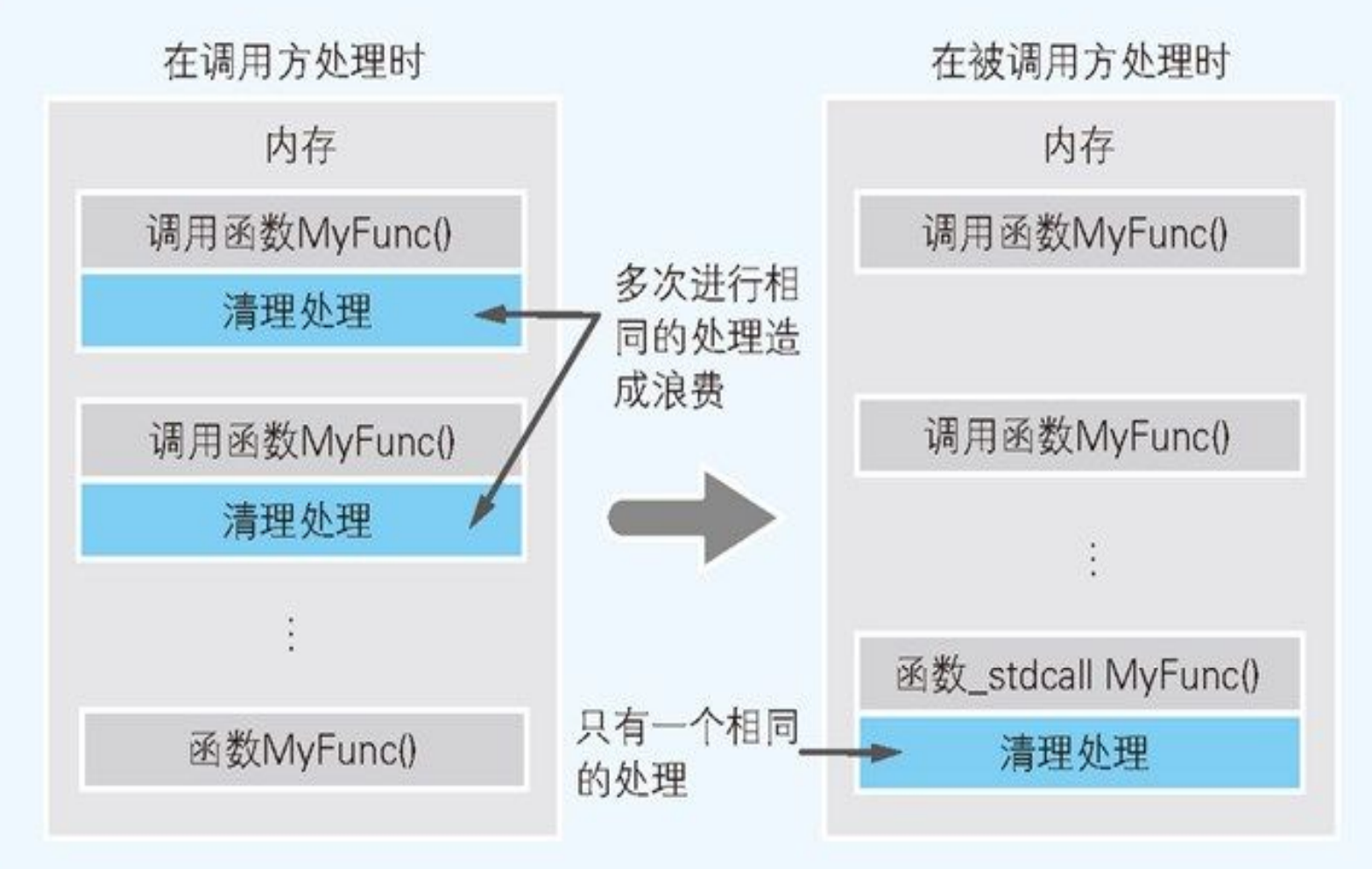
磁盘的物理结构
磁盘的物理结构是指磁盘存储数据的形式。
磁盘是通过把其物理表面划分成多个空间来使用的。划分的方式有
扇区方式和可变长方式两种,扇区方式是指将磁盘划分为固定长度的空间,可变长方式则是指把磁盘划分为长度可变的空间。
Windows 采用的是扇区方式。扇区方式中,把磁盘表面分成若干个同心圆的空间就是
磁道,把磁道按照固定大小(能存储的 数据长度相同)划分而成的空间就是扇区。扇区是对磁盘进行物理读写的最小单位。Windows 中使用的磁盘, 1 个扇区是 512 字节。不过,Windows 在逻辑方面(软件方面)对磁盘进行读写的单位是扇区整数倍
簇。根据磁盘容量的不同,1 簇可以是 512 字节(1 簇 = 1 扇区)、1KB(1 簇 = 2 扇区)、2KB、4KB、 8KB、16KB、32KB(1 簇 = 64 扇区)。磁盘的容量越大,簇的容量也越大。不过,在软盘中,1 簇 = 512 字节 = 1 扇区,簇和扇区的大小是相等的。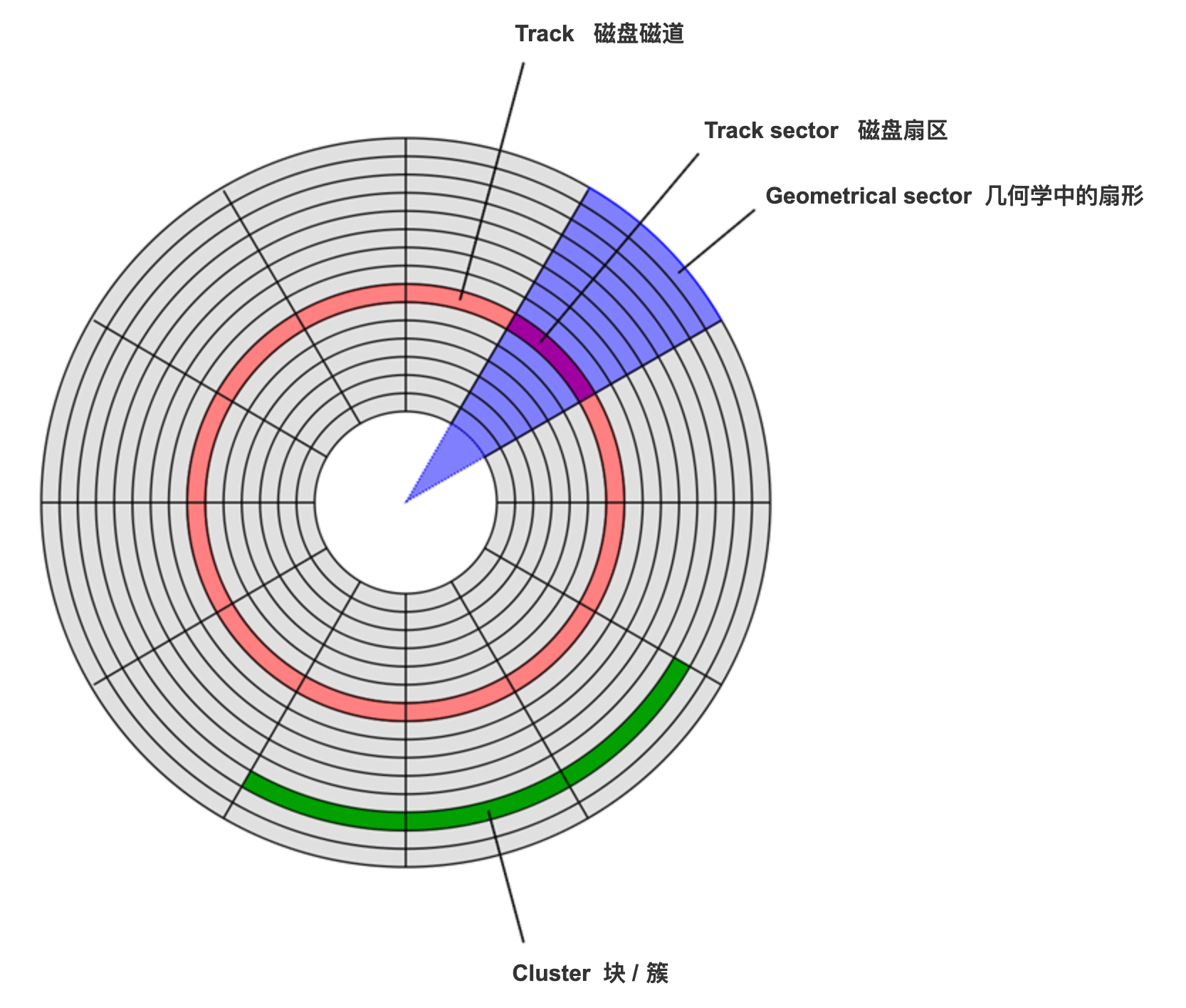
不管是硬盘还是软盘,不同的文件是不能存储在同一个簇中的,否则就会导致只有一方的文件不能被删除。因此,不管是多么小的文件, 都会占用 1 簇的空间。这样一来,所有的文件都会占用 1 簇的整数倍的磁盘空间。
大多数磁盘分区方案旨在使文件占据整数个扇区,而不管文件的实际大小如何。未填充完整个扇区的文件将最后一个扇区的其余部分填充零。实际上,操作系统通常使用数据块操作,数据块可跨越多个扇区。
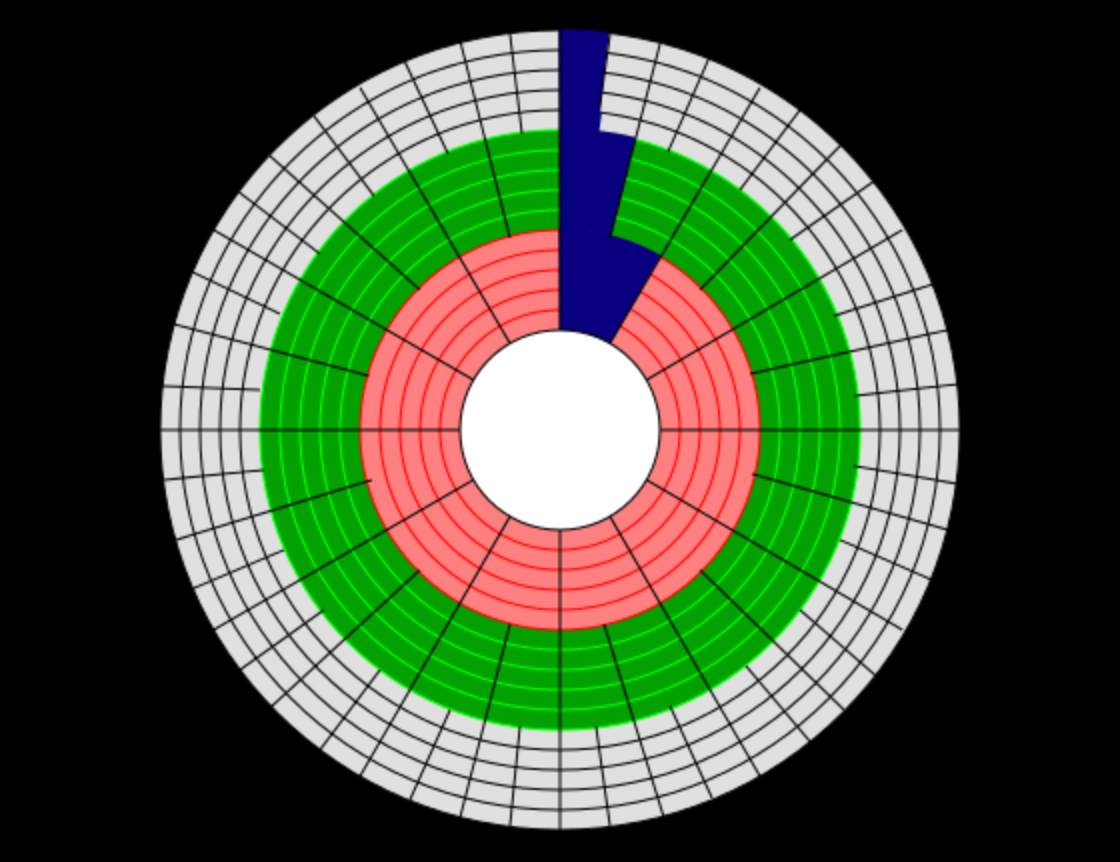
ZBR 区位记录
- 在早期的硬盘驱动器中,所有的磁道包含的扇区数目都是一样的,按照固定的圆心角辐射出去,就可以简单的将各磁道的扇区数进行统一。这样,在磁道边缘的扇区弧长就要大于内部的扇区弧长,其存储数据的密度也要比内部磁道的密度要小。最终,导致外部磁道的空间浪费。
- 为了有效利用外部磁道空间,让所有的磁道扇区存储数据密度一致,就需要保证所有扇区的弧长一致。这样就要根据磁道的半径来重新分配扇区数目。
- ZBR 区位记录,是指为了提高磁盘的存储容量,充分利用磁盘外面磁道的存储能力,现代磁盘不再把内外磁道划分为相同数目的扇区。ZBR通过在外部磁道上每个区域放置比内部磁道更多的扇区来实现此目的。
- 如下图片所示,可以看到粉红色、绿色、灰色部分的扇区数量不一样。
第 6 章 亲自尝试压缩数据
RLE 压缩算法
- RLE(Run Length Encoding,行程长度编码)压缩算法:将文件的内容用“字符 × 重复次数”这样的方式来压缩。
- 比如: AAAAAABBCDDEEEEEF 就可以用 A6B2C1D2E5F1 来表示。
- RLE 算法经常被用于传真 FAX 等。G3 类传真机是把文字和图形都作为黑白图像来发送的。由于黑白图像的数据中,白或黑通常是部分连续的,因此就没有必要再发送这部分数据的值(白或者黑),而只需附带上重复次数即可,这样压缩效率就得到了大幅提升。例如,像白色部分重复 5 次,黑色部分重复 7 次,白色部分重复 4 次,黑色部分重复 6 次这样的部分图像,就可以用 5746 这样的重复次数数字来进行压缩。
JPEG 格式文件有 3 种压缩方式
- 把构成图像的点阵的颜色信息由 RGB(红色、绿色、蓝色)形式转化成 YCbCr(亮度、蓝色色度、红色色度)形式。我们知道,人眼对亮度很敏感,但对颜色的变化却有些迟钝。因此,人眼比较敏感的亮度 Y 就是一个很重要的参数,而表示颜色的 Cb、Cr 则没有那么重要。于是我们就可以通过减少 Cb 和 Cr 的信息间距来缩小图像数据的大小。
- 将每个点的色素变化看作是波形的信号变化,进行傅里叶变换。傅里叶变换是指将波形按照频率分量进行分解。照片等图像文件的特点是低频率(柔和的颜色变化)的部分较多,高频率(强烈的颜色变化)的部分较少。因此,我们就可以把高频率的部分剪切掉。这样一来,图像数据也就会缩小。虽然剪切掉了高频率部分,但人眼分辨不 出什么差别。不过,如果是用 Windows 画笔描绘的简单图形,其中颜色变化强烈的部分就会出现模糊现象。大家不妨使用 Windows 画笔做一个圆形或者四方形的图形,并将其保存成 JPEG 格式。然后再打开这个 JPEG 文件,你就会发现颜色变化强烈的部分变模糊了。
- 将已经瘦身的图像数据通过哈夫曼算法进行压缩。这样就可以使图像数据进一步缩小。
第 7 章 程序是在何种环境中运行的
什么是运行环境
Mac 的软件不能在 Windows 中运行。为什么?因为运行环境不同。这里的
运行环境指的就是操作系统和计算机本身 ( 硬件 ) 的种类。应用的运行环境通常是用类似于 Windows(OS) 和 AT 兼容机(硬件)这样的 OS 和硬件的种类来表示的。
简单来讲:运行环境 = 操作系统 + 硬件
我们下载软件的时候,下载页面一定会列出
操作系统和硬件。这里指的就是软件的运行环境。
FreeBSD 的 Ports 机制
- 众所周知,操作系统抹平了除 CPU 以外的全部差异。
- 既然 CPU 类型不同会导致机器代码无法重复利用,那么为何不直接把源代码分发给程序呢?FreeBSD 的 Ports 机制能够结合当前运行的硬件环境来编译应用的源代码,进而得到可以运行的机器代码。
- 可以说 Ports 能够克服包含 CPU 在内的所有硬件差异的系统。而且 Ports 这个术语表示的是 porting(移植)的意思。而根据不同的运行环境来重新调整程序,一般也称为
移植。
提供相同运行环境的 Java 虚拟机
同其他编程语言相同,Java 也是将 Java 语法记述的源代码编译后运行。不过,编译后生成的并不是特定 CPU 使用的本地代码,而是名为
字节代码的程序。字节代码的运行环境就称为 Java 虚拟机。Java 虚拟机是一边把 Java 字节代码逐一转换成本地代码一边运行的。在程序运行时,将编译后的字节代码转换成本地代码,由此可以实现同样的字节代码在不同的环境下运行。
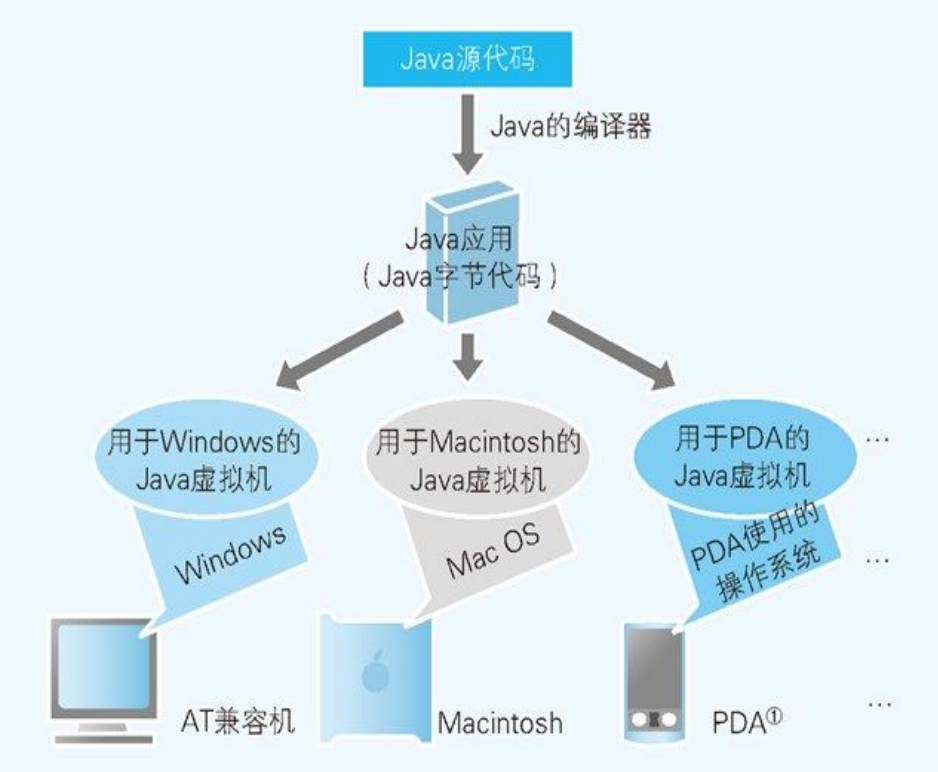
从 Java 应用方面来看,Java 虚拟机就是运行环境。Java 虚拟机每次运行时都要把字节代码变换成本机代码,这一机制是造成运行速度慢的原因。
BIOS 和引导
- BIOS 存储在 ROM 中,是预先内置在计算机主机内部的程序。
- BIOS 除了键盘、磁盘、显卡等基本控制程序外,还有启动
引导程序的功能。 - 引导程序是存储在启动驱动器起始区域的小程序。开机后,BIOS 会确认硬件是否正常运行,没有问题的话就会启动引导程序。引导程序的功能是把在硬盘等记录的 OS 加载到内存中运行。虽然启动应用是 OS 的功能,但 OS 并不能自己启动自己,而是通过引导程序来启动。
第 8 章 从源文件到可执行文件
Windows 中的编译和链接机制
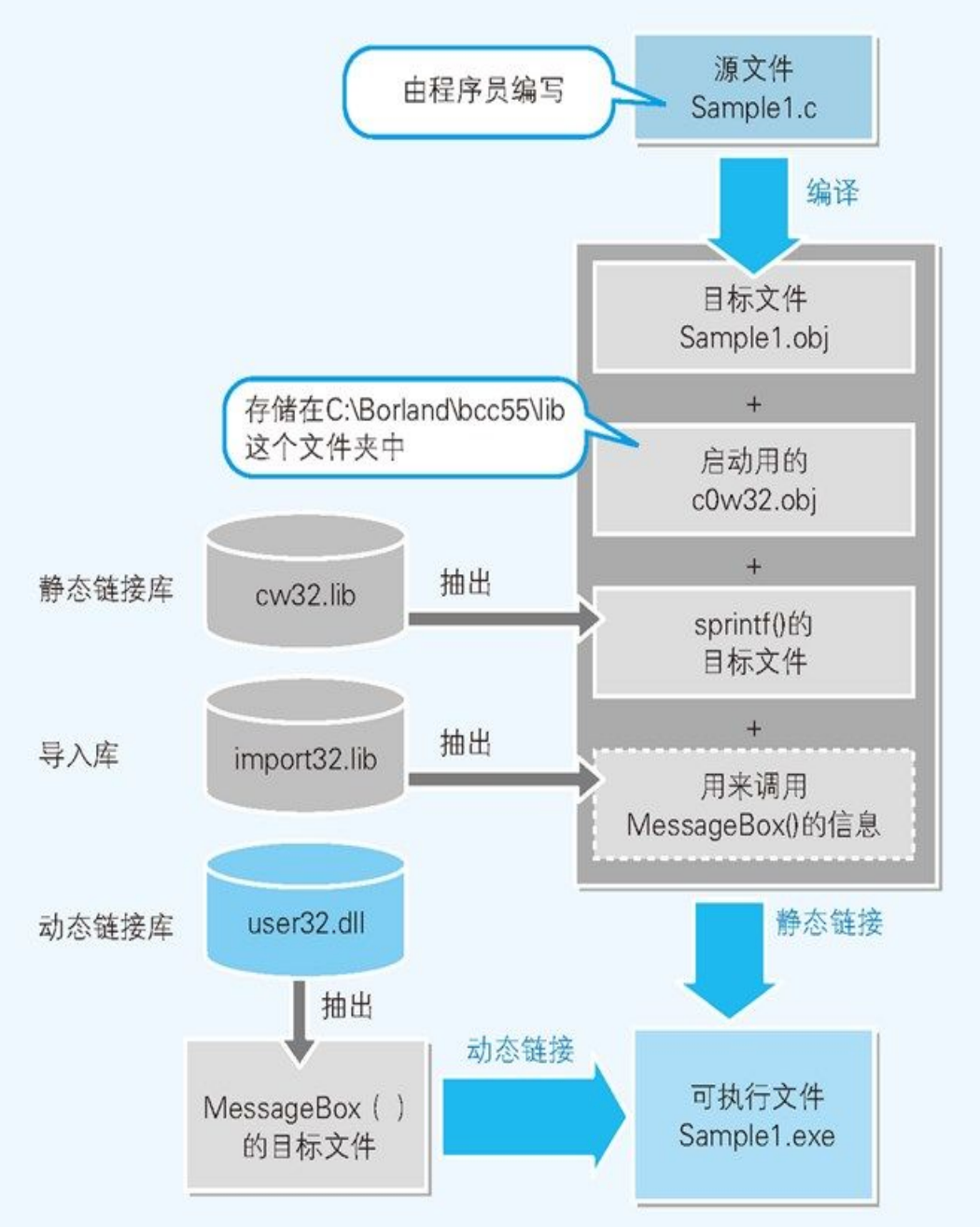
可执行文件运行时的必要条件
本地代码在对程序中记述的变量进行读写时,是参照数据存储的内存地址来运行命令的。在调用函数时,程序的处理流程就会跳转到存储着函数处理内容的内存地址上。EXE 文件作为本地代码的程序,并没有指定变量及函数的实际内存地址。在类似于 Windows 操作系统这样的可以加载多个可执行程序的运行环境中,每次运行时,程序内的变量及函数被分配到的内存地址都是不同的。
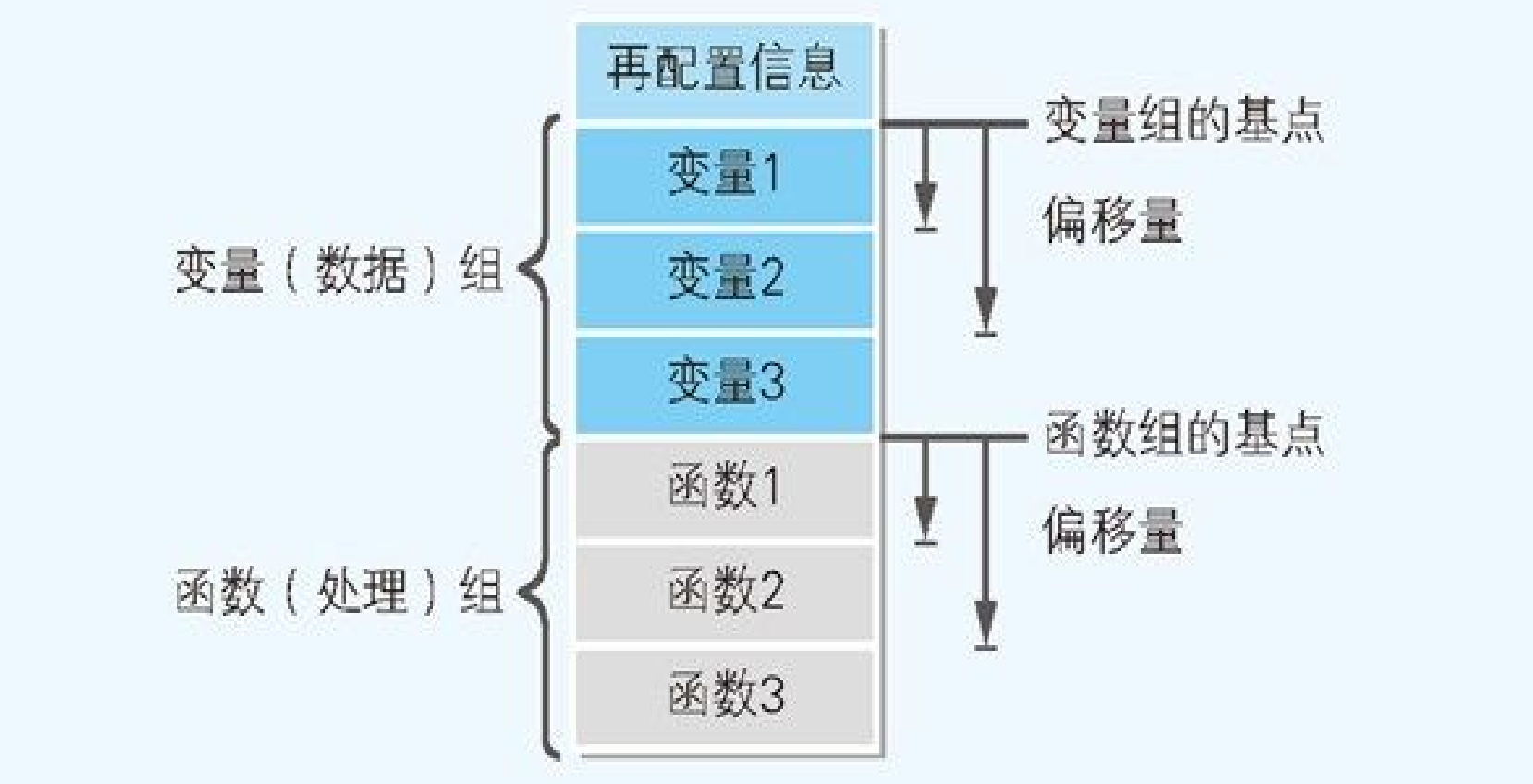
那么,在 EXE 文件中,变量和函数的内存地址的值,是如何来表示的呢?那就是 EXE 文件中给变量及函数分配了虚拟的内存地址。在程序运行时,虚拟的内存地址会转换成实际的内存地址。链接器会在 EXE 文件的开头,追加转换内存地址所需的必要信 息。这个信息称为
再配置信息。EXE 文件的再配置信息,就成为了变量和函数的相对地址。相对地址表示的是相对于基点地址的偏移量,也就是相对距离。在源代码中,虽然变量及函数是在不同位置分散记述的,但在链接后的 EXE 文件中,变量及函数就会变成一个连续排列的组。这样一来,各变量的内存地址就可以用相对于变量组起始位置这一基点的偏移量来表示,同样,各函数的内存地址也可以用相对于函数组起始位置这一基点的偏移量来表示。而各组基点的内存地址则是在程序运行时被分配的。
简单来说:
- 多个程序可以同时运行,在单个 CPU 上共享时间,操作系统的这种能力叫
多任务处理。- 同时运行多个程序有个问题,每个程序都会占一些内存,当切换到另一个程序时,我们不能丢失数据。解决办法是,给每个程序分配专属内存块。举个例子,假设计算机一共有 10000 个内存位置,程序 A 分配到内存地址 0 到 999,而程序 B 分配到内存地址 1000 到 1999,以此类推。如果一个程序请求更多内存,操作系统会决定是否同意,如果同意,分配哪些内存块。
- 这种灵活性很好,但带来一个奇怪的后果,程序 A 可能会分配到非连续的内存块,比如内存地址 0 到 999,以及 2000 到 2999,也就是说程序可能会分配到内存中数十个地方。程序员来说很难跟踪。
- 为了隐藏这种复杂性,操作系统会把内存地址进行 “虚拟化”,这叫
虚拟内存,程序可以假定内存总是从地址0开始。而实际物理位置被操作系统隐藏和抽象了,操作系统会自动处理虚拟内存和物理内存之间的映射。- 这种机制使程序的内存大小可以灵活增减,叫
动态内存分配。对程序来说,内存看起来是连续的,它简化了一切,为操作系统同时运行多个程序,提供了极大的灵活性。
第 9 章 操作系统和应用的关系
系统调用和高级编程语言的移植性
操作系统的硬件控制功能,通常是通过一些小的函数集合体的形式来提供的。这些函数及调用函数的行为统称为
系统调用(system call), 也就是应用对操作系统(system)的功能进行调用(call)的意思。time() 及 printf() 等函数内部也都使用了系统调用。
这里之所以用“内部”这个词,是因为在 Windows 操作系统中,提供返回当前日期和时刻,以及在显示器中显示字符串等功能系统调用的函数名,并不是 time() 和 printf()。系统调用是在 time() 和 printf() 函数的内部执行的。
C 语言等高级编程语言并不依存于特定的操作系统。这是因为人们希望不管是 Windows 还是 Linux,都能使用几乎相同的源代码。因此, 高级编程语言的机制就是,使用独自的函数名,然后再在编译时将其转换成相应操作系统的系统调用。
在高级编程语言中,也存在可以直接调用系统调用的编程语言。不过,利用这种方式做成的应用,移植性并不友好。
Windows 操作系统的特征
32 位操作系统(也有 64 位版本)
通过 API 函数集来提供系统调用
- 32 位版 Windows API 也称为
Win32 API。64 位版的称为Win64 API。 - API 通过多个 DLL 文件来提供。
- 各 API 的实体都是用 C 语言编写的函数。因而,C 语言程序的情况下,API 的使用更加容易。
- 32 位版 Windows API 也称为
提供采用了图形用户界面的用户界面
通过 WYSIWYG 实现打印输出
提供多任务功能
- Windows 是通过
时钟分割技术来实现多任务功能的。 - 时钟分割指的是在短时间间隔内,多个程序切换运行的方式。在用户看来,就是多个程序在同时运行。
- Windows 是通过
提供网络功能及数据库功能
通过即插即用实现设备驱动的自动设定
- 即插即用 (Plug-and-Play)指的是新的设备连接(Plug)后立刻就可以 使用(Play)的机制。
- 新的设备连接到计算机后,系统就会自动安装和设定用来控制该设备的设备驱动程序。
第 10 章 通过汇编语言了解程序的实际构成
函数的参数是通过栈来传递,返回值是通过寄存器来返回的
1 | int AddNum(int a,int b) { |
1 | _MyFunc proc near |
- 虽然记述为函数 AddNum(123,456),但入栈时则会按照 456、123 这样的顺序,也就是位于后面的数值先入栈。 这是 C 语言的规定。
- 编译器有最优化功能。编译器在本地代码上费尽功夫实现的,其目的是让编译后的程序运行速度更快、文件更小。由于存储着 AddNum 函数返回值的变量 c 在后面没有被用到,因此编译器就会认为“该处理没有意义”, 进而也就没有生成与之对应的汇编语言代码。
- 函数的参数是通过栈来传递,返回值是通过寄存器来返回的。
始终确保全局变量用的内存空间
- C 语言中,在函数外部定义的变量称为
全局变量,在函数内部定义的变量称为局部变量。全局变量可以引用源代码的任意部分,而局部变量只能在定义该变量的函数内进行引用。我们通过汇编语言的源代码,来看一下全局变量和局部变量的不同。 - 简单来讲:
全局变量会被放置在自己的数据段。
1 | //定义被初始化的全局变量 |
对应的汇编:
1 | _DATA segment dword public use32 'DATA'--------------------┐ |
- 编译后的程序,会被归类到名为段定义的组。
- 初始化的全局变量,就像(1)一样,被汇总到名为
_DATA的段定义中, - 没有初始化的全局变量,就像(2)一样,被汇总到名为
_BSS的段定义中。 - 指令则会像(3)那样被汇总到名为
_TEXT的段定义中。这些段定义的名称是由 Borland C++ 的使用规范来决定的。
- 初始化的全局变量,就像(1)一样,被汇总到名为
- 观察(8)(9),发现在 MyFunc 函数中定义的局部变量所需要的内存领域,会被尽可能地分配在寄存器中。寄存器空闲时就使用寄存器,寄存器空间不足的话就使用栈。
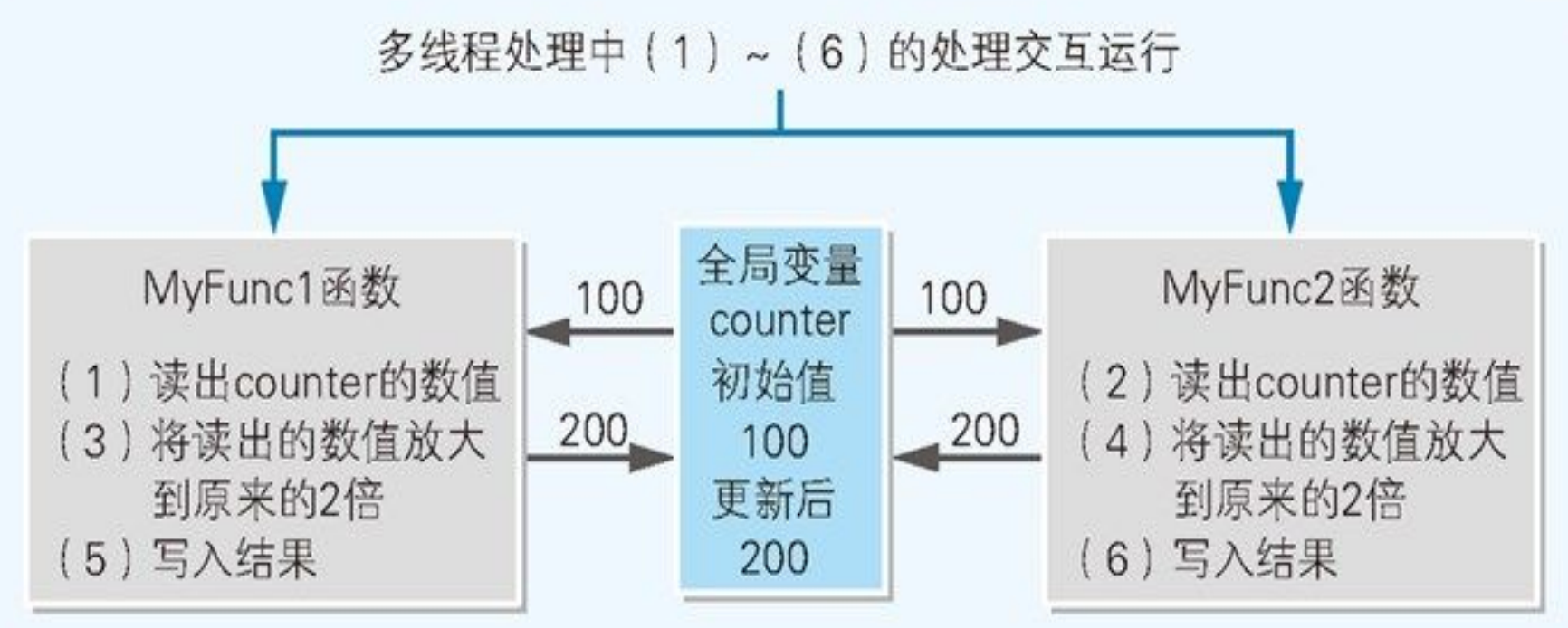
从汇编角度解释多线程下race的发生
两个线程同时执行,一个跑MyFunc1,另一个跑MyFunc2。理想结果 counter 应变成 100×2×2 = 400。
1 | int counter = 100; |
转成汇编:
1 | _DATA segment dword public use32 'DATA' |
- 在多线程处理中,用汇编语言记述的代码每运行 1 行,处理都有可能切换到其他线程(函数)中。
- 因而,假设 MyFunc1 函数在读出 counter 的数值 100 后,还未来得及将它的 2 倍值 200 写入 counter 时,正巧 MyFunc2 函数读出了 counter 的数值 100,那么结果就会导致 counter 的数值变成了 200。
第 11 章 硬件控制方法
在用 C 语言等高级编程语言开发的 Windows 应用中,大家很少能接触到直接控制硬件的指令。这是因为硬件的控制是由 Windows 全权负责的。
不过,Windows 提供了通过应用来间接控制硬件的方法。利用操作系统提供的
系统调用功能就可以实现对硬件的控制。这些函数的实体被存储在 DLL 文件中。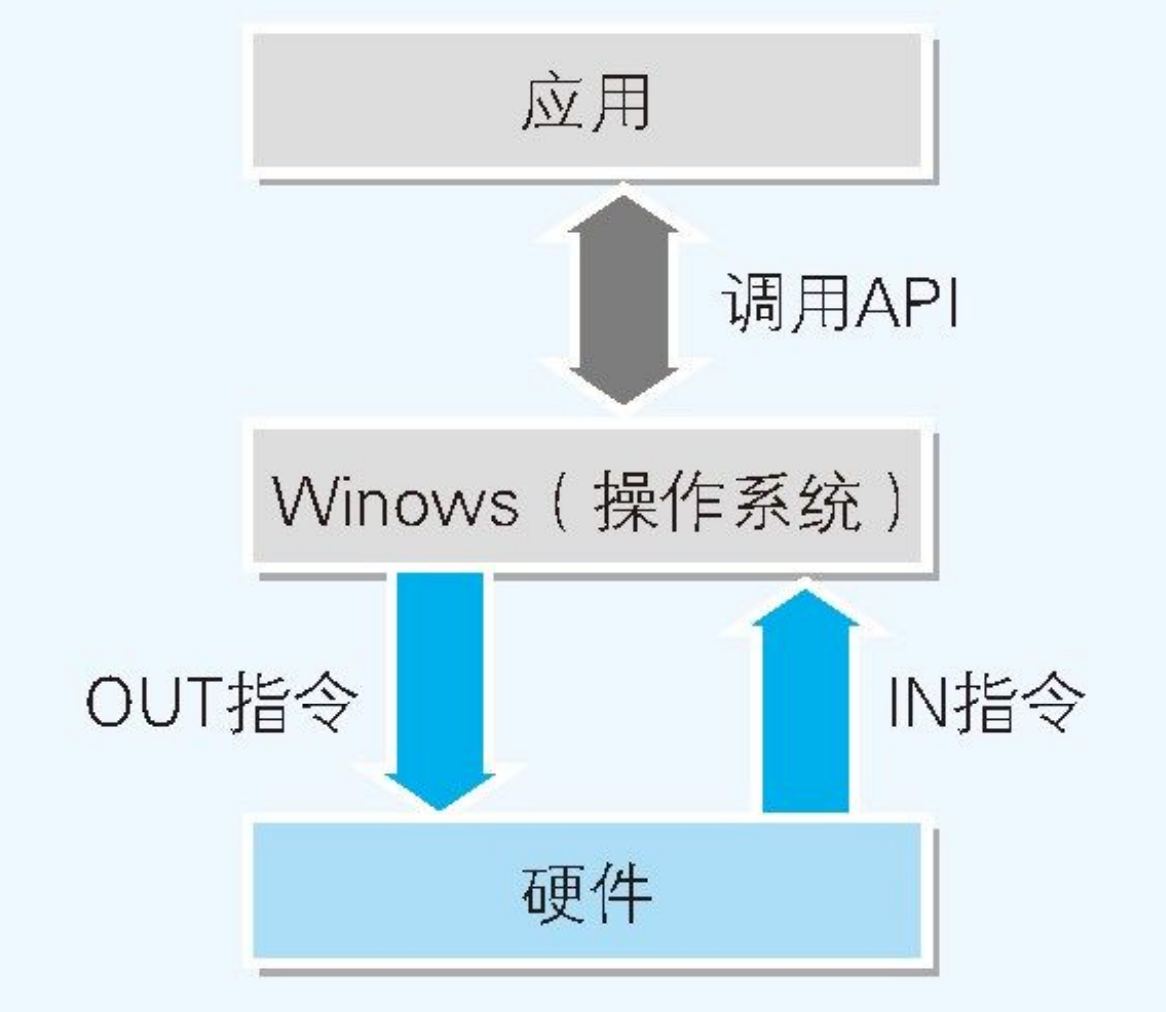
但 Windows 本身也是 软件,由此可见,Windows 应该向 CPU 传递了某些指令,从而通过软件控制了硬件。
IN 指令和 OUT 指令在端口号指定的端口和 CPU 之间进行数据的输入输出
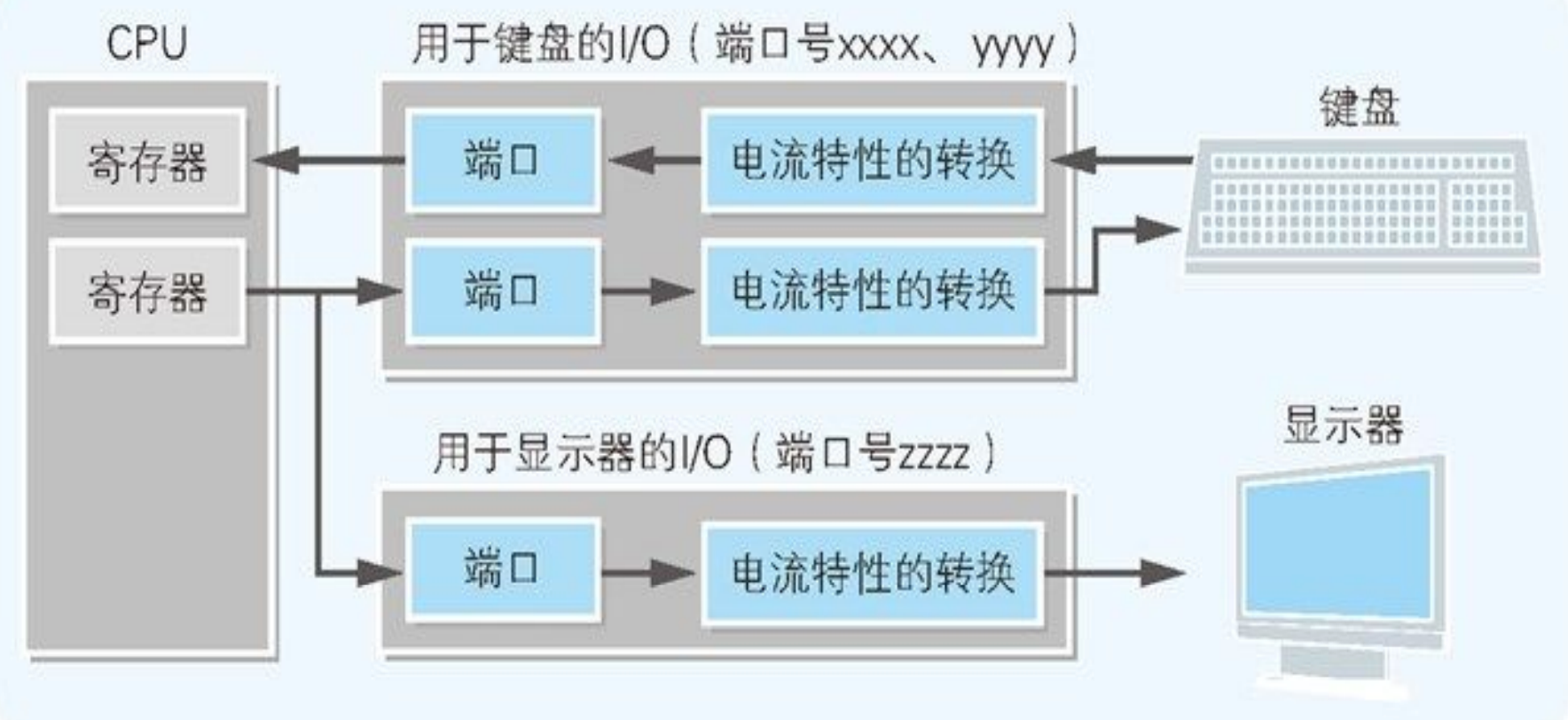
利用 IN/OUT 指令来控制蜂鸣器
1 | void main(){ |
上面的代码在现在的 Windows 其实执行不了的。因为现在的 Windows 禁止了应用直接控制硬件的方式。
中断
- 中断处理程序的第一步处理,就是把 CPU 所有寄存器的数值保存到内存的栈中。
- 因为不同程序访问的内存不同,其他程序是无法修改不同程序所使用的内存的,所以中断发生后,只要寄存器的值保持不变,主程序就可以像没有发生任何事情一样继续处理。
DMA 可以实现短时间内传送大量数据
DMA(Direct Memory Access):是指在不通过 CPU 的情况下,外围设备直接和主内存进行数据传送。
磁盘等都用到了 DMA 机制。通过利用 DMA,大量数据就可以在短时间内转送到主内存。之所以这么快速,是因为 CPU 作为中介的时间被节省了。
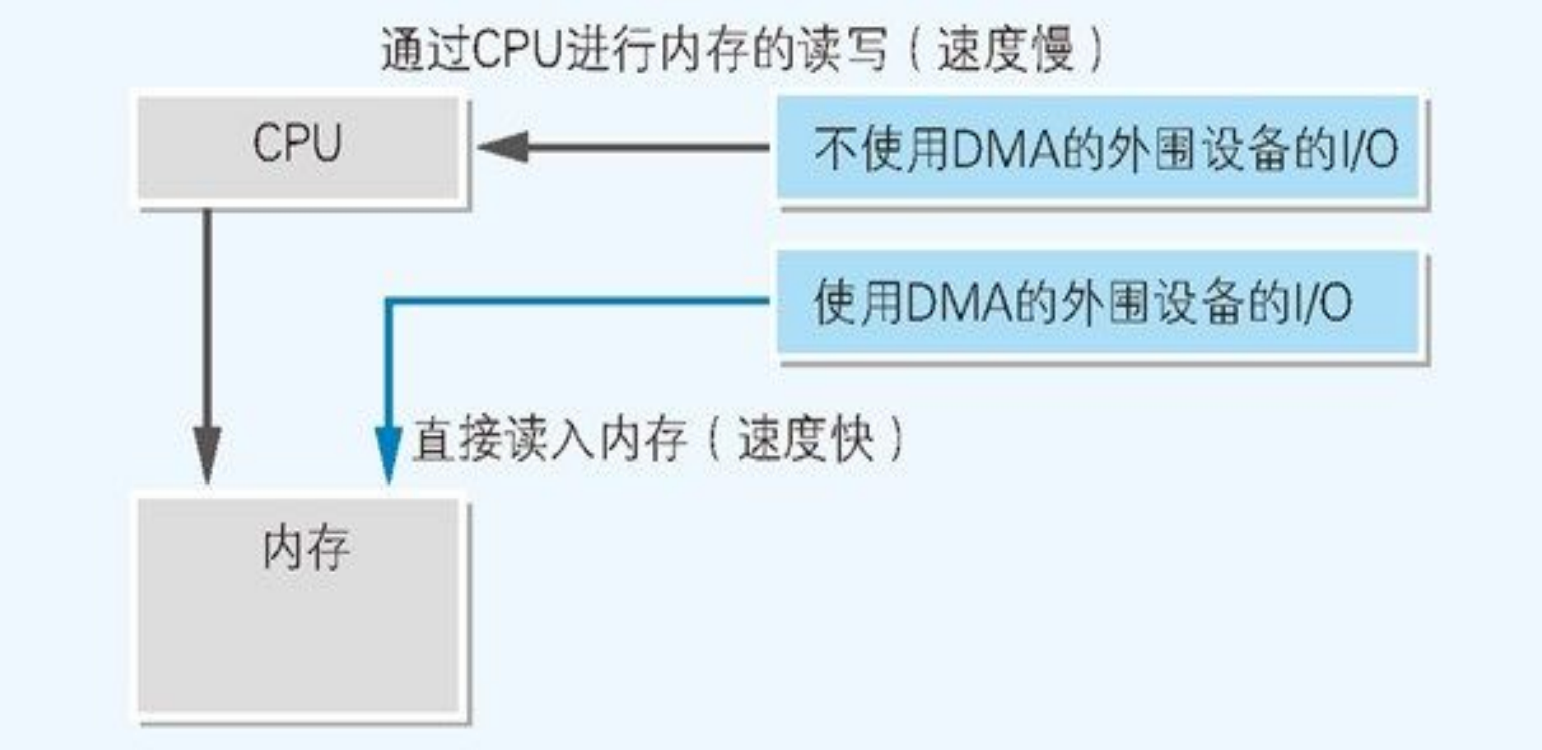
不同的外围设置使用不同的编号,这个编号称为
DMA 通道。CPU 借助 DMA 通道,来识别是哪一个外围设备使用了 DMA。
第 12 章 让计算机“思考”
随机算法:线性同余法
把 Ri 作为当前随机数,那么下一个出现的随机数 Ri + 1 就可以用下面的公式来获取:
1 | Ri + 1 = (a × Ri + b ) mod c |
- 对 a 、b 、c 各参数设定合适的整数后,可以从该公式获得的随机数的范围就是 0 到 c (不包含)。
- 把 a 设定为 5,b 设定为 3,c 设定为 8,就可以获得的随机数。不过,产生 8 次随机数后,下 8 次产生的随机数就和前面的数值相同了。这种周期性是伪随机数的特征,也是为什么不是真随机数的原因。
- C 语言的随机种子:获取当前时间的参数。以 time(NULL) 的值为基础,来设定 Ri 、a 、b 、c 的数值。
没什么阅读价值的书,鉴定完毕。
FIN