mysql 数据库 GTID 介绍
概念
从 MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式。通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的 ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力。
GTID:Global Transaction ID,是全局事务 ID,由主库上生成的与事务绑定的唯一标识,这个标识不仅在主库上是唯一的,在 MySQL 集群内也是唯一的。
1 | GTID = server_uuid:transaction_id |
示例:3E11FA47-71CA-11E1-9E33-C80AA9429562:1
- GTID 实际上是由 UUID+TID 组成的。
- 其中 UUID 是一个 MySQL 实例的唯一标识。TID 代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。
- server_uuid 一般是发起事务的 uuid,标识了该事务执行的源节点,存储在数据目录中的 auto.cnf 文件中,transaction_id 是在该主库上生成的事务序列号,从 1 开始,1-2 代表第二个事务;第 1-n 代表 n 个事务。
- 示例中 3E11FA47-71CA-11E1-9E33-C80AA9429562 是这个节点的 server_uuid,1 为这个节点上提交的第 1 个事务的事务号,如果提交了 10 个事务,GTID 会是这样: 3E11FA47-71CA-11E1-9E33-C80AA9429562:1-10
当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务,对 DBA 来说意义就很大了,我们可以适当的解放出来,不用手工去可以找偏移量的值了,而是通过 CHANGE MASTER TO MASTER_HOST=’xxx’,MASTER_AUTO_POSITION=1 的即可方便的搭建从库,在故障修复中也可以采用 MASTER_AUTO_POSITION=‘X’的方式。
为什么要有 GTID
- 在主从复制中,尤其是半同步复制中, 由于 Master 的 dump 进程一边要发送 binlog 给 Slave,一边要等待 Slave 的 ACK 消息,这个过程是串行的,即前一个事物的 ACK 没有收到消息,那么后一个事物只能排队候着; 这样将会极大地影响性能;
- 有了 GTID 后,SLAVE 就直接可以通过数据流获得 GTID 信息,而且可以同步;
- 另外,主从故障切换中,如果一台 MASTER down,需要提取拥有最新日志的 SLAVE 做 MASTER,而有了 GTID,就只要以 GTID 为准即可方便判断;而有了 GTID 后,SLAVE 就不需要一直保存这 bin-log 的文件名和 Position 了;只要启用 MASTER_AUTO_POSITION 即可。
- 当 MASTER crash 的时候,GTID 有助于保证数据一致性,因为每个事物都对应唯一 GTID,如果在恢复的时候某事物被重复提交,SLAVE 会直接忽略;
从架构设计的角度,GTID 是一种很好的分布式 ID 实践方式,通常来说,分布式 ID 有两个基本要求:
- 全局唯一性
- 趋势递增
这个 ID 因为是全局唯一,所以在分布式环境中很容易识别。因为趋势递增,所以 ID 是具有相应的趋势规律,在必要的时候方便进行顺序提取。所以换一个角度来理解 GTID,其实是一种优雅的分布式设计。
GTID 有什么优缺点
优点
GTID 相对于行复制数据安全性更高,故障切换更简单。
- 根据 GTID 可以快速的确定事务最初是在哪个实例上提交的。
- 简单的实现 failover,不用以前那样在需要找 log_file 和 log_pos。
- 更简单的搭建主从复制,确保每个事务只会被执行一次。
- 比传统的复制更加安全,一个 GTID 在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
- GTID 是连续的,没有空洞的,保证数据的一致性,零丢失
- GTID 用来代替 classic 的复制方法,不再使用 binlog+pos 开启复制。而是使用 master_auto_postion=1 的方式自动匹配 GTID 断点进行复制。
- GTID 的引入,让每一个事务在集群事务的海洋中有了秩序,使得 DBA 在运维中做集群变迁时更加方便
缺点
主从库的表存储引擎必须是一致的。
主从库的表存储引擎不一致,就会导致数据不一致。如果主从库的存储引擎不一致,例如一个是事务存储引擎,一个是非事务存储引擎,则会导致事务和 GTID 之间一对一的关系被破坏,结果就会导致基于 GTID 的复制不能正确运行;
- master:对一个 innodb 表做一个多 sql 更新的事物,效果是产生一个 GTID。
- slave:假设对应的表是 MYISAM 引擎,执行这个 GTID 的第一个语句后就会报错,因为非事务引擎一个 sql 就是一个事务。
当从库报错时简单的
stop slave; start slave;就能够忽略错误。但是这个时候主从的一致性已经出现问题,需要手工的把 slave 差的数据补上,这里要将引擎调整为一样的,slave 也改为事务引擎。不允许一个 SQL 同时更新一个事务引擎和非事务引擎的表。
事务中混合多个存储引擎,就会产生多个 GTID。当使用 GTID 时,如果在同一个事务中,更新包括了非事务引擎(如 MyISAM)和事务引擎(如 InnoDB)表的操作,就会导致多个 GTID 分配给了同一个事务。
在一个复制组中,必须要求统一开启 GTID 或是关闭 GTID;
不支持 create table….select 语句复制(主库直接报错);
create table xxx as select 的语句,其实会被拆分为两部分,create 语句和 insert 语句,但是如果想一次搞定,MySQL 会抛出如下的错误。
1
ERROR 1786 (HY000): Statement violates GTID consistency: CREATE TABLE ... SELECT.
create table xxx as select 的方式可以拆分成两部分,如下。
1
2create table xxxx like data_mgr;
insert into xxxx select *from data_mgr;对于 create temporary table 和 drop temporary table 语句不支持;
使用 GTID 复制模式时,不支持 create temporary table 和 drop temporary table。但是在 autocommit=1 的情况下可以创建临时表,Master 端创建临时表不产生 GTID 信息,所以不会同步到 slave,但是在删除临时表的时候会产生 GTID 会导致,主从中断.
不支持 sal_slave_skip_counter
mysql 在主从复制时如果要跳过报错,可以采取以下方式跳过 SQL(event)组成的事务,但 GTID 不支持以下方式。
1
2set global SQL_SLAVE_SKIP_COUNTER=1;
start slave sql_thread;
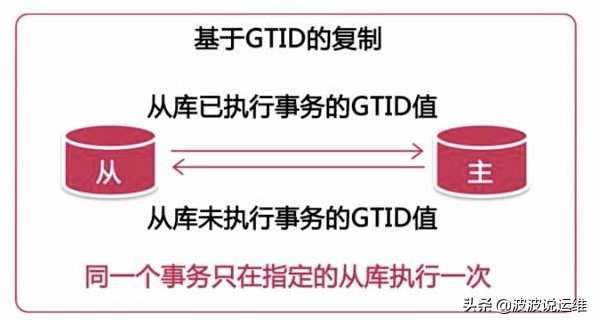
GTID 主从复制原理
一般在主从复制的场景下,如果只有单台就没必要使用 GTID 了。
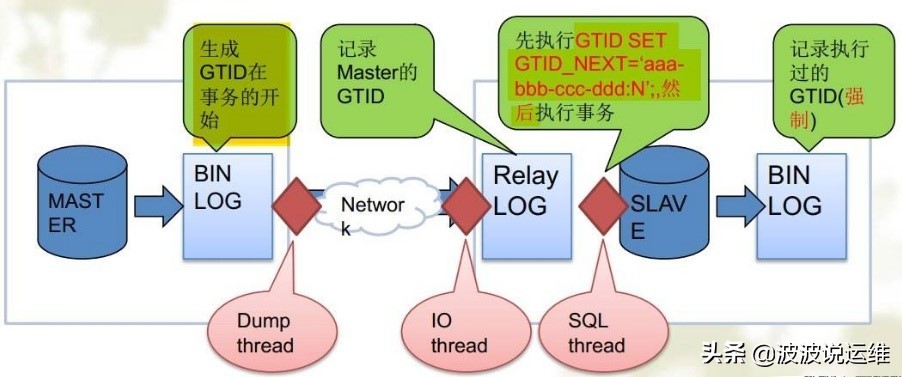
- 当一个事务在主库端执行并提交时,产生 GTID,一同记录到 binlog 日志中。
- binlog 传输到 slave, 并存储到 slave 的 relaylog 后,读取这个 GTID 的这个值设置 gtid_next 变量,即告诉 Slave,下一个要执行的 GTID 值。
- sql 线程从 relay log 中获取 GTID,然后对比 slave 端的 binlog 是否有该 GTID。
- 如果有记录,说明该 GTID 的事务已经执行,slave 会忽略。
- 如果没有记录,slave 就会执行该 GTID 事务,并记录该 GTID 到自身的 binlog;
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。
GTID 生命周期
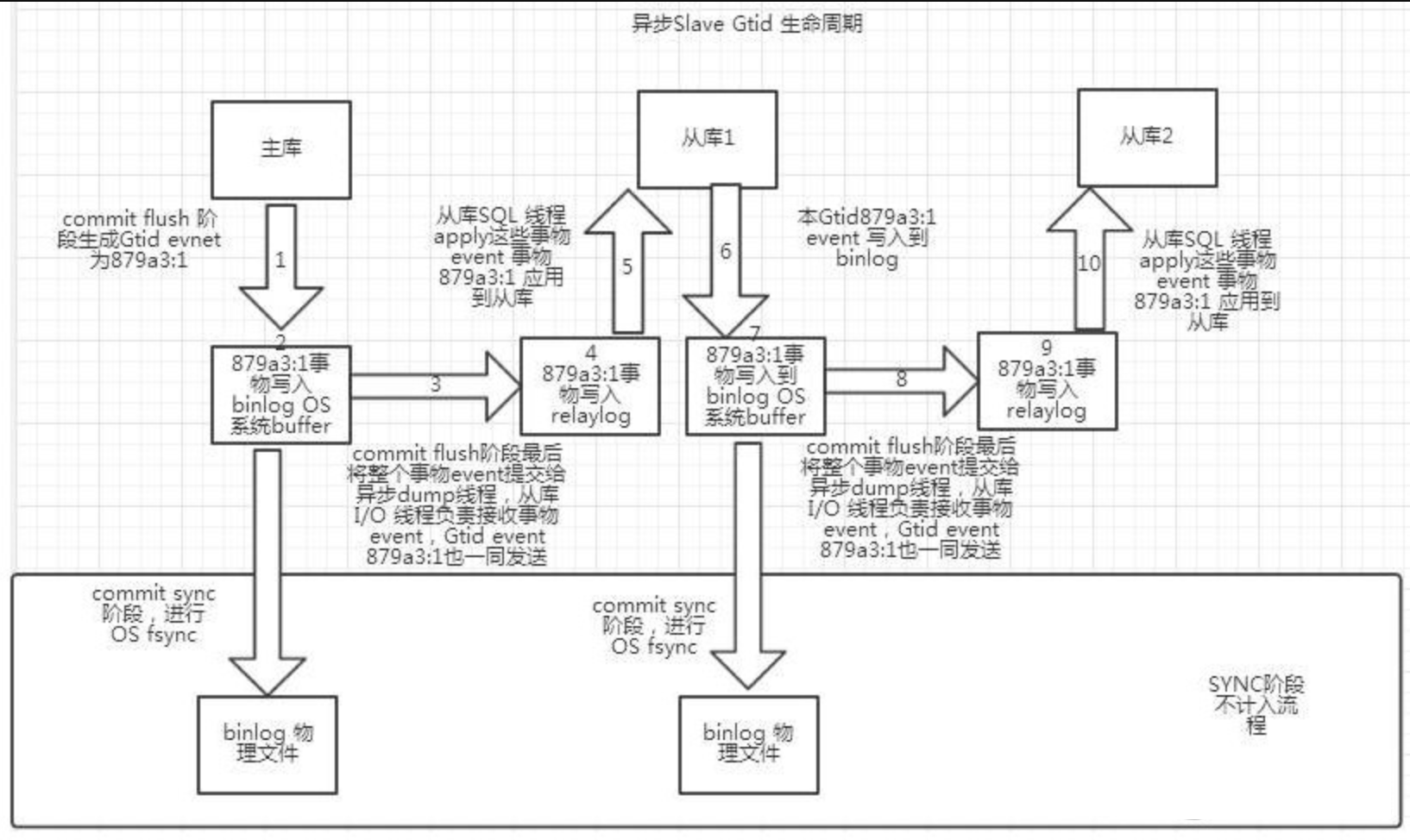
当事务于主库执行时,系统会为事务分配一个由 server uuid 加序列号组成的 GTID(当然读事务或者被主动过滤掉的事务不会被分配 GTID),写 binlog 日志时此 GTID 标志着一个事务的开始。
binlog 中写 GTID 的 event 被称作 Gtid_log_event,当 binlog 切换或者 mysql 服务关闭时,之前 binlog 中的所有 gtid 都会被加入 mysql.gtid_executed 表中。此表内容如下(slave 中此表记录数会有多条,取决于主从个数):
1
mysql> select * from mysql.gtid_executed;
当 GTID 被分配且事务被提交后,他会被迅速的以一种外部的、非原子性的方式加入 @@GLOBAL.gtid_executed 参数中,这个参数包含了所有被提交的 GTID 事务(其实它是一个 GTID 范围值,例如 71cf4b9d-8343-11e8-97f1-a0d3c1f25190:1-10),@@GLOBAL.gtid_executed 也被用于主从复制,表示数据库当前已经执行到了哪个事务。相比之下 mysql.gtid_executed 不能用于标识主库当前事务进度,因为有部分 gtid 还在 binlog 中,需要等到 binlog 轮转或者 MySQL Server 关闭时才会写入到 mysql.gtid_executed 表中。
在主从首次同步时(master_auto_position=1),slave 会通过 gtid 协议将自己已经执行的 gtid set(@@global.gtid_executed)发给 master,master 比较后从首个未被执行的 GTID 事务开始主从同步。
主库上的 binlog 通过主从复制协议传送到从库,并写入到从库的 relay log,从库读取 relay log 中的 gtid 和对应的事务信息,把 gtid_next 设置为该 gtid 值,使得从库使用该 gtid 值应用其对应的事务。
需要注意的是这里的 gtid_next 是在复制进程的 session context 中自动设置的(由 binlog 提供的语句),不同于 show variables like ‘gtid_next’; 这里看到的结果默认为 AUTOMATIC,是当前会话本身的 gtid_next,这是个 session 级别的参数。
当开启并行复制时,slave 会读取并检查事务的 GTID 确保当前 GTID 事务未被在 slave 执行过,且没有并行进程在读取并执行此事务,如果有并行复制进程正在应用此事务那么 slave server 只会允许一个进程继续执行,@@GLOBAL.gtid_owned 参数展示了当前哪个并行复制进程在执行什么事务。
同样的,在 slave 上如果开启了 binlog,GTID 也会以 Gtid_log_event 事件写入 binlog,同时 binlog 切换或者 mysql 服务关闭时,当前 binlog 中的所有 gtid 都会被加入 mysql.gtid_executed 表中。
在备库上如果未开启 binlog,那么 GTID 会被直接持久化到 mysql.gtid_executed 表中,在这种情况下 slave 的 mysql.gtid_executed 表包含了所有已经被执行的事务。需要注意的是在 mysql5.7 中,向 mysql.gtid_executed 表插入 GTID 的操作与 DML 操作是原子性的,对于 DDL 操作则不是,因此如果 slave 在执行 DDL 操作的过程中异常中断那么 GTID 机制可能会失效。在 mysql8.0 中这个问题已经得到解决,DDL 操作的 GTID 插入也是原子性的。
同第 3 条中所说的一样,slave 上的事务被执行后 GTID 也会被迅速的以一种外部的、非原子性的方式加入 @@GLOBAL.gtid_executed 参数中,在 slave 的 binlog 未开启时 mysql.gtid_executed 中记载的已提交事务事实上与 @@GLOBAL.gtid_executed 记载的是一致的,如果 slave 的 binlog 已开启那么 mysql.gtid_executed 的 GTID 事务集就没有 @@GLOBAL.gtid_executed 全了。
如果多个线程并发地应用同一个事务,比如多个线程设置 gtid_next 为同一个值,MySQL Server 只允许其中一个线程执行,gtid_owned 系统变量记录着谁拥有该 GTID。