ES系列之利用filter让你的查询效率飞起来
bool查询简介
Elasticsearch中的bool查询在业务中使用也是比较多的。在一些非实时的分页查询,导出的场景,我们经常使用bool查询组合各种查询条件。
Bool查询包括四种子句,
- must
- filter
- should
- must_not
我这里只介绍下must和filter两种子句,因为是我们今天要讲的重点。其它的可以自行查询官方文档。
- must, 返回的文档必须满足must子句的条件,并且参与计算分值
- filter, 返回的文档必须满足filter子句的条件。但是跟Must不一样的是,不会计算分值, 并且可以使用缓存.
从上面的描述来看,你应该已经知道,如果只看查询的结果,must和filter是一样的。区别是场景不一样。如果结果需要算分就使用must,否则可以考虑使用filter。
光说比较抽象,看个例子,下面两个语句,查询的结果是一样的。
使用filter过滤时间范围,
1 | GET kibana_sample_data_ecommerce/_search |
使用must过滤时间范围,
1 | { |
查询的结果都是,
1 | { |
filter比较高效的原理
简单来讲,如果你的业务场景不需要算分,使用filter可以真的让你的查询效率飞起来。
为了说明filter查询高效的原因,我们需要引入ES的一个概念query context和filter context。
query context
query context关注的是,文档到底有多匹配查询的条件,这个匹配的程度是由相关性分数决定的,分数越高自然就越匹配。所以这种查询除了关注文档是否满足查询条件,还需要额外的计算相关性分数.
filter context
filter context关注的是,文档是否匹配查询条件,结果只有两个,是和否。没有其它额外的计算。它常用的一个场景就是过滤时间范围。
并且filter context会自动被ES缓存结果,效率进一步提高。
对于bool查询,must使用的就是query context,而filter使用的就是filter context。
我们可以通过一个示例验证下。继续使用第一节的例子,我们通过kibana自带的search profiler来看看ES的查询的详细过程。
使用must查询的执行过程是这样的:
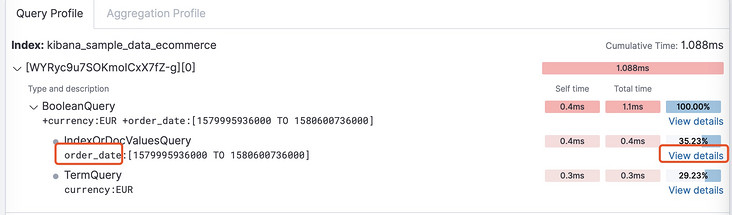
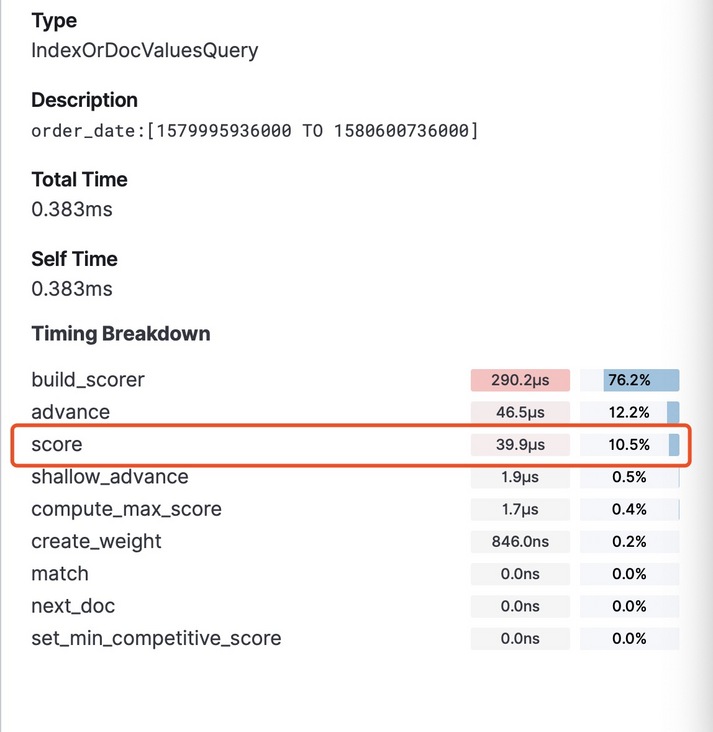
可以明显看到,此次查询计算了相关性分数,而且score的部分占据了查询时间的10分之一左右。
filter的查询我就不截图了,区别就是score这部分是0,也就是不计算相关性分数。
除了是否计算相关性算分的差别,经常使用的过滤器将被Elasticsearch自动缓存,以提高性能。
我自己曾经在一个项目中,对一个业务查询场景做了这种优化,当时线上的索引文档数量大概是3000万左右,改成filter之后,查询的速度几乎快了一倍。
我截了几张图,你来感受下。


filter与bool的执行优先级
- 如果一个查询 既有query又有filter。那么会先执行filter,然后执行query。原因就是filter的效率比query高。先用高效率的操作缩小范围,再执行低效率的操作
- 如果有多个filter查询,那么将无法确定那个filter先执行。因此如果同时有一个精确搜索和一个wildCard搜索,不要将wildCard搜索改成regexp,再放入filter。
1 | // bad |
1 | // better |
总结
我们应该根据自己的实际业务场景选择合适的查询语句,在某些不需要相关性算分的查询场景,尽量使用filter context可以让你的查询更加高效。