装饰器复习
函数装饰器有4种,类装饰器有2种
函数装饰器 1.函数装饰函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from time import perf_counterdef time_counter (func ): def wrapper (*args,**kwargs ): start = perf_counter() func(*args,**kwargs) print (perf_counter() - start) return wrapper @time_counter def foo (): [num for num in range (55555 )] foo()
2.函数装饰类方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from time import perf_counterdef time_counter (func ): def wrapper (*args,**kwargs ): start = perf_counter() func(*args,**kwargs) print (perf_counter() - start) return wrapper class A : @time_counter def foo (self ): [num for num in range (55555 )] a = A() a.foo()
上面两个装饰器一模一样 , 也就是说,函数装饰器能无差别的运用于函数和类方法
3.类装饰函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from time import perf_counterclass TimeCounter : def __init__ (self,func ): self.func = func def __call__ (self,*args,**kwargs ): start = perf_counter() self.func(*args,**kwargs) print (perf_counter() - start) @TimeCounter def foo (): [num for num in range (55555 )] foo()
4.类装饰类方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from time import perf_counterclass TimeCounter : def __init__ (self,func ): self.func = func self.cls = self.__class__ def __call__ (self,*args,**kwargs ): start = perf_counter() self.func(self.cls,*args,**kwargs) print (perf_counter() - start) class A : @TimeCounter def foo (self ): [num for num in range (55555 )] a = A() a.foo()
类装饰器 类装饰器要返回另外一个类
1.函数装饰类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def deco (cls ): class Wrapper : def __init__ (self,*args,**kwargs ): self.wrapped = cls(*args,**kwargs) def __getattr__ (self,name ): return getattr (self.wrapped,name) return Wrapper @deco class C : def __init__ (self,x,y ): self.attr = 'spam' c = C(6 ,7 ) print (c.attr)
2.类装饰类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Deco : def __init__ (self,cls ): self.cls = cls def __call__ (self,*args,**kwargs ): self.wrapped = self.cls(*args,**kwargs) return self.wrapped def __getattr__ (self,name ): return getattr (self.wrapped,name) @Deco class C : def __init__ (self,name ): self.name = name c = C('heyingliang' ) print (c.name)
装饰器的嵌套 装饰器的进入顺序 : 由上到下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def deco1 (func ): def wrapper (*args,**kwargs ): print ('deco1' ) func(*args,**kwargs) return wrapper def deco2 (func ): def wrapper (*args,**kwargs ): print ('deco2' ) func(*args,**kwargs) return wrapper @deco1 @deco2 def func (): pass func()
带参数的装饰器 1.函数装饰函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def deco (func_name ): def wrapper (func ): def wrapped (*args,**kwargs ): print (f'--- in deco : {func_name} ---' ) func(*args,**kwargs) print (f'--- end deco: {func_name} ---' ) return wrapped return wrapper @deco('foo' def func (): pass func()
2.类装饰函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def deco (func_name ): class wrapped : def __init__ (self,func ): self.func = func def __call__ (self,*args,**kwargs ): print (f'--- in deco : {func_name} ---' ) self.func(*args,**kwargs) print (f'--- end deco: {func_name} ---' ) return wrapped @deco('foo' def func (): pass func()
正则表达式复习 ?前面字符出现的次数为1或0 ? : 前面字符 出现的次数为1或者为0
注意,是前面字符出现的次数,不是后面字符出现的次数
1 2 3 4 5 6 7 8 import rex = r'\(?0\d{2}[) -]?\d{8}' print (re.search(x,'(010)88886666' ))print (re.search(x,'022-22334455' ))
|是贪婪的 x|y : 匹配x或y。
z|food能匹配 z 或 food。(z|f)ood则匹配 zood 或 food 。
也就是说 : |是贪婪的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import rex = r'0\d{4}-\d{5}|\d{5}' y = r'\d{4}-\d{5}|\d{5}' print (re.search(y,'4444-12345' ))print (re.search(y,'12345' ))print (re.search(x,'4444-12345' ))print (re.search(x,'12345' ))
各个分组 注意 :分组的括号都是加在最前面
(pattern)
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。
(?:pattern)
匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“`(
(?=pattern)
正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“`Windows(?=95
(?!pattern)
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“`Windows(?!95
(?<=pattern)
反向肯定预查,与正向肯定预查类拟,只是方向相反。例如,“`(?<=95
(?<!pattern)
反向否定预查,与正向否定预查类拟,只是方向相反。例如“`(?<!95
Python里的正则
方法
功能
match()
判断一个正则表达式是否从开始处匹配一个字符串
search()
遍历字符串,找到正则表达式匹配的第一个位置
findall()
遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回
finditer()
遍历字符串,找到正则表达式匹配的所有位置,并以迭代器的形式返回
匹配对象的属性方法
方法
功能
group()
返回匹配的字符串
start()
返回匹配的开始位置
end()
返回匹配的结束位置
span()
返回一个元组表示匹配位置(开始,结束)
方法
用途
split()
在正则表达式匹配的地方进行分割,并返回一个列表
sub()
找到所有匹配的子字符串,并替换为新的内容
subn()
跟 sub() 干一样的勾当,但返回新的字符串以及替换的数目
标志符
标志
含义
ASCII,A
使得转义符号如\w,\b,\s和\d只能匹配ASCII字符
DOTALL,S
使得.匹配任何符号,包括换行符
IGNORECASE,I
匹配的时候不区分大小写
LOCALE,L
支持当前的语言(区域)设置
MULTILINE,M
多行匹配,影响^和$
VERBOSE,X(for’extended’)
启用详细的正则表达式
捕获分组(去重处理) 1 2 3 4 5 6 7 8 9 10 11 import res = "我..我我.我.....要..要要要要要.....学..学学学........编..编.编........程.程.程程" ; def regex (s ): s = re.sub(r'\.' ,'' ,s) s = re.sub(r'(.)\1+' ,r'\1' ,s) print (s) regex(s)
(.)匹配一个字符(.)\1匹配两个相同的字符(.)\1+匹配多个相同的字符
Xpath复习
表达式
描述
nodename
选取此节点的所有子节点。
/
从根节点选取。
//
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.
选取当前节点。
..
选取当前节点的父节点。
@
选取属性。
简单来说:**/是直接子节点,//是非直接子节点**。注意,这两个都是子节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 from lxml import etreehtml = ''' <div class='content'> <ul id='haha'> <li class="item-1"><a href="link2.html">first item</a></li> </ul></div> ''' x = etree.HTML(html) result = x.xpath('//div[@class="content"]//li/a/text()' ) print (result)
使用and函数来获取多属性的标签 1 2 3 4 5 6 7 8 9 10 11 12 13 from lxml import etreehtml = ''' <div class='content'> <ul id='haha'> <li class="item-1" name="hyl"><a href="link2.html">first item</a></li> </ul></div> ''' x = etree.HTML(html) result = x.xpath('//div//li[@class="item-1" and @name="hyl"]/a/text()' ) print (result)
多值属性获取 1 2 3 4 5 6 7 8 9 10 11 12 13 from lxml import etreehtml = ''' <div class='content'> <ul id='haha'> <li class="item hyl" ><a href="link2.html">first item</a></li> </ul></div> ''' x = etree.HTML(html) result = x.xpath('//div//li[contains(@class,"item hyl")]/a/text()' ) print (result)
伪类选择器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from lxml import etreehtml = ''' <div class='content'> <ul id='haha'> <li class="item-0" ><a href="link2.html">1</a></li> <li class="item-1" ><a href="link2.html">2</a></li> <li class="item-1" ><a href="link2.html">3</a></li> <li class="item-0" ><a href="link2.html">4</a></li> </ul></div> ''' x = etree.HTML(html) result1 = x.xpath('//div//li' ) result2 = x.xpath('//div//li[1]' ) result3 = x.xpath('//div//li[last()]' ) result4 = x.xpath('//div//li[position()<3]' ) result5 = x.xpath('//div//li[last()-2]' )
关系节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from lxml import etreehtml = ''' <div class='content'> <ul id='haha'> <li class="item-0" ><a href="link2.html">1</a></li> <li class="item-1" ><a href="link2.html">2</a></li> <li class="item-1" ><a href="link2.html">3</a></li> <li class="item-0" ><a href="link2.html">4</a></li> </ul></div> ''' x = etree.HTML(html) result1 = x.xpath('//li/ancestor::*' ) result2 = x.xpath('//li[1]/ancestor::ul' ) result3 = x.xpath('//li[1]/attribute::*' ) result4 = x.xpath('//li[2]/child::a' ) result5 = x.xpath('//li[2]/descendant::a' ) result6 = x.xpath('//li[2]/following::*[2]' ) result7 = x.xpath('//li[2]/following-sibling::*' )
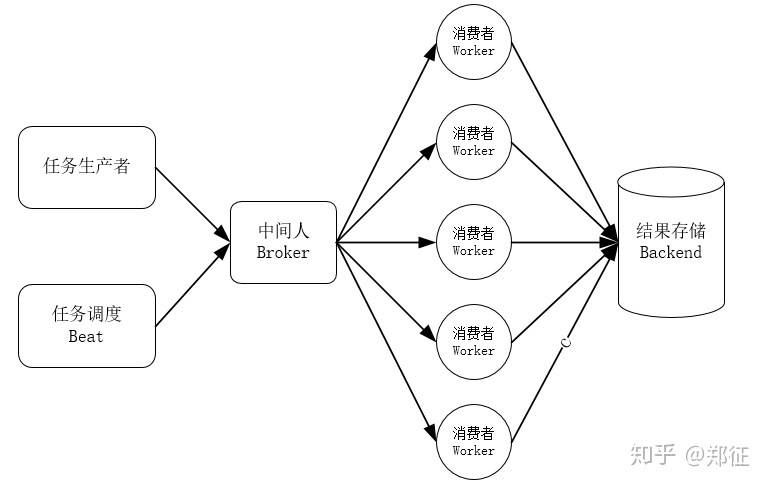
Celery复习 概念
任务生产者 :产生任务并交给任务队列
任务调度 Beat:周期性的产生任务发送给任务队列
中间人(Broker):消息通信
执行单元 worker:worker监控任务队列,当队列中有新地任务时,它便取出来执行
任务结果存储backend:持久存储 Worker 执行任务的结果
使用流程
创建APP
APP加载配置
使用APP去装饰一个函数
使用命令行启动Celery
外部使用delay调用这个函数
使用定时任务只需要修改celery_config.py即可
启动 Celery Beat 进程
示例 1 2 3 4 5 6 celery_demo # 项目根目录 ├── celery_app # 存放 celery 相关文件 │ ├── __init__.py # 创建app,初始化配置 │ ├── celeryconfig.py # 配置文件 │ └── task.py # 任务文件 └── client.py # 应用程序
1 2 3 4 5 from celery import Celeryapp = Celery('demo' ) app.config_from_object('celery_app.celeryconfig' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from datetime import timedeltaBROKER_URL = 'redis://127.0.0.1:6379' CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0' CELERY_TIMEZONE='Asia/Shanghai' CELERY_IMPORTS = ( 'celery_app.task' , ) CELERYBEAT_SCHEDULE = { 'add-every-3-seconds' : { 'task' : 'celery_app.task.printer' , 'schedule' : timedelta(seconds=3 ), 'args' : (5 ,) }, }
1 2 3 4 5 6 7 8 9 10 import timefrom celery_app import app@app.task def printer (num ): time.sleep(2 ) print ('--------------' ,num)
1 2 3 4 5 6 7 8 9 10 import timefrom celery_app.task import printerif __name__ == '__main__' : now = time.time() printer.delay(5 ) print ('----' ,time.time()-now)
启动worker
1 celery -A celery_app worker -l info -P eventlet
启动beat
1 celery beat -A celery_app
设计工作流 签名包装了一个任务的调用参数 和执行参数
signature 当成偏函数使用:
1 2 3 4 5 s1 = add.s(2 , 2 ) res = s1.delay() res.get()
Group group并行地执行一个任务列表,按顺序返回一个特殊的结果实例 (GroupResult对象)(所以可以使用.get()获取值)
1 2 3 4 5 from celery import groupfrom proj.tasks import add group(add.s(i, i) for i in range (10 ))().get()
group(add.s(i, i) for i in range(10) : 返回<class 'celery.canvas.group'>
group(add.s(i, i) for i in range(10)() : 返回<class 'celery.result.GroupResult'>
group(add.s(i, i) for i in range(10))().get() : 返回 [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
Chains 任务可以像使用管道一样连接在一起,前一个执行完成后会执行下一个:
1 2 3 4 5 6 7 from celery import chainfrom proj.tasks import add, mulchain(add.s(4 , 4 ) | mul.s(8 ))().get()
Chords chord是一个带回调函数的group
1 2 3 4 5 from celery import chordfrom proj.tasks import add, xsumchord((add.s(i, i) for i in range (10 )), sum .s())().get()
链式任务 尽量使用异步回调的方式进行链式任务的调用
错误示范
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @app.task def fetch_page (url ): return myhttplib.get(url) @app.task def parse_page (url, page ): return myparser.parse_document(page) @app.task def store_page_info (url, info ): return PageInfo.objects.create(url, info) @app.task def main (url ): page = fetch_page.delay(url).get() info = parse_page.delay(url, page).get() store_page_info.delay(url, info)
正确示范:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @app.task() def fetch_page (url ): return myhttplib.get(url) @app.task() def parse_page (page ): return myparser.parse_document(page) @app.task(ignore_result=True ) def store_page_info (info, url ): PageInfo.objects.create(url=url, info=info) def main (url ): chain = fetch_page.s(url) | parse_page.s() | store_page_info.s(url) chain()
链式任务中前一个任务的返回值默认是下一个任务的输入值之一 不想让返回值做默认参数可以用 si() 或者 s(immutable=True) 的方式调用 。
Django复习 1+N问题
1+N问题是针对于外键的
1+N问题是针对多条数据查找的
1 2 3 4 5 6 7 8 9 posts = Post.objects.all () result = [] for post in posts: result.append({ 'title' : post.title, 'owner' : post.owner.name, })
上面代码中,我们是查找所有文章的作者 ,这样肯定会带来1+N问题,这时候就可以使用select_related
1 Post.objects.select_related('user' ).all ()
但是针对于单个查找,比如说查找文章名为”a”的文章的作者 ,就可以直接使用.外键字段
1 2 Post.objects.filter (title__exact='a' ).owner.name
Post.objects.select_related('user').all()和Post.objects.filter(title__exact='a').owner.name的关系有点像
1 select * from post join user on post.owner = user.user_id
1 2 3 select name from user where user_id in ( select owner from post where post.title='a' )
一对多查找(防止1+N问题) 连接两个表 : User.objects.all().select_related('外键字段')
连接三个表 : User.objects.all().select_related('外键字段__外键字段')
1 2 3 4 5 6 7 8 9 10 articles = Article.objects.all ().select_related('category' ) Life_article = articles.filter (category__name__exact='Life' ).order_by('-create_time' )[:6 ] comments = ArticleComment.objects.select_related('from_user__icon' ).filter (article=art).all ()
多对多查找(防止1+N问题)
对于一张表来说,定义了foreignKey和ManyToManyField其实是一件好事,因为这样就可以使用filter(外键字段__字段__操作符='XXX')很轻易的获取它的值
1 2 Life_article = Article.objects.filter (category__name__exact='Life' ).order_by('-create_time' )[:6 ]
不过如果是大量查找的话会造成1+N问题,
解决方案:
1 2 3 4 articles = (Article.objects.prefetch_related('tags' ).filter (tags__engname__exact='hyl' ))
单个查找所有(已知某个作者,查找该作者的全部出版书籍)
1 2 3 4 5 6 7 8 9 10 from django.db import modelsclass Author (models.Model ): name = models.CharField() email = models.EmailField() class Book (models.Model ): title = models.CharField() authors = models.ManyToManyField(Author)
1 2 3 4 5 6 7 b = Book.objects.get(id =1 ) b.author.all () a = Author.objects.get(id =1 ) a.book_set.all ()
没有的一方调用有的一方,就要使用_set
1+N问题总结 前面的细节部分不用看了,直接看这个
适用范围
1+N问题是针对于外键的
1+N问题是针对多条数据查找的
也就是说:select_related和prefetch_related
一对多单条数据查询:
多对多单条数据查询:
获取
一对多 : 获取某个分类的所有文章:
1 Article.objects.filter (category__name__exact='a' ).all ()
一对多 : 获取某个文章的分类:
1 2 3 Article.objects.filter (id =1 ).category Category.objects.article_set.first()
多对多 : 获取某个文章的所有标签:
1 Article.objects.filter (id =1 ).tags.all ()
多对多 : 获取某个标签的所有文章:
1 2 3 Article.objects.filter (tags__name__exact='a' ).all () Tag.objects.get(id =1 ).article_set.all ()
聚合函数 使用aggregate()函数返回聚合函数的值
1 2 from django.db.models import MaxmaxAge = Students.objects.aggregate(Max('sage' ))
groupby要使用annotate annotate用于添加一列:
先Article.objects.values("category")查取category列
使用Count("category")计算数量
然后添加Count列
1 articles_num = Article.objects.values("category" ).annotate(Count=Count("category" ))
示例 :
Count 接受的参数为需要计数的模型的名称
1 2 Category.objects.annotate(num_posts=Count('post' ))
统计返回的 Category 记录的集合中每条记录下的文章数
代码中的 Count 方法为我们做了这个事,它接收一个和 Categoty 相关联的模型参数名(这里是 Post,通过 ForeignKey 关联的),然后它便会统计 Category 记录的集合中每条记录下的与之关联的 Post 记录的行数,也就是文章数,最后把这个值保存到 num_posts 属性中。
现在在 Category 列表中每一项都新增了一个 num_posts 属性记录该 Category 下的文章数量,我们就可以在模板中引用这个属性来显示分类下的文章数量了。
==只要是两个 model 类通过 ForeignKey 或者 ManyToMany 关联起来,那么就可以使用 annotate 方法来统计数量。==
1 2 3 4 5 6 7 8 9 10 class Post (models.Model ): title = models.CharField(max_length=70 ) body = models.TextField() Tags = models.ManyToManyField('Tag' ) def __str__ (self ): return self.title class Tag (models.Model ): name = models.CharField(max_length=100 )
统计标签下的文章数:
1 2 3 4 5 from django.db.models.aggregates import Countfrom blog.models import Tagtag_list = Tag.objects.annotate(num_posts=Count('post' ))
自定义模型管理器 1 2 3 4 5 6 7 8 9 class IsDeleteManager (models.Manager ): '去除删除Manager' def get_queryset (self ): return super ().get_queryset().filter (isDelete=False ) class Article (models.Model ): '文章' objects = IsDeleteManager()
自定义标签和过滤器
在app中创建templatetags模块(模块名只能是templatetags)
在templatetags里面创建任意 .py 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from django import templatefrom django.utils.safestring import mark_safe register = template.Library() @register.filter def multi (x,y ): return x*y @register.simple_tag def multitag (x,y,z ): return x*y*z @register.simple_tag def my_input (id ,arg result = "<input type='text' id='%s' class='%s' />" %(id ,arg,) return mark_safe(result)
在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py
1 2 3 4 5 {{ var|filter_name:参数 }} {% simple_tag 参数1 参数2 ... %}
定义标签示例 1 2 3 4 5 6 7 8 9 from django import templateregister = template.Library() @register.simple_tag def get_data_age (): age = 10 return age
1 2 3 4 5 6 7 8 9 <body > {% load {% get_data_age as age %} <h1 > 我的第一个HTML页面</h1 > <p > 我的年纪 {{ age }} </p > </body >
{% get_data_age as age %} : 给函数获取的值取名
定义过滤器示例 1 2 3 4 5 6 7 8 9 10 11 from django import templateregister = template.Library() @register.filter(name='truncate_filter' ) def truncate_chars (value ): if value.__len__() > 5 : return '%s......' % value[0 :5 ] else : return value
如果没有使用name参数,django默认会将函数名作为name参数的值,所以下面的代码和上面的代码作用相同。
1 2 3 4 5 6 7 <body > {% load <h1 > 我的第一个HTML页面</h1 > <p > 我的年纪 {{ "123456789"|truncate_chars }} </p > </body >
如果tempaltetags无法调用,很有可能是load放错位置:
1 2 3 4 5 6 7 8 9 10 11 12 13 {% extends {% load {% block 工具 | 凉薄 {% endblock {% block {% load {% install_posts_from_net as msg %} {% endblock
session 设置session过期时间
1 2 3 4 def showmain (request ): username = reqeust.POST.get('username' ) request.sessionn.set_expiry(10 )
清除session
1 2 3 4 5 from django.contrib.auth import logoutdef quit (request ): logout(request) ...
模板 在模板中使用点语法
模板里使用session:{{ request.session.username }} : 取出session里的username
1 2 3 4 5 6 7 {% if 欢迎 <a href ="#" > {{ request.session.username }} </a > <a href ="#" > 注销</a > {% else <a href =" {% url " ></a > <a href =" {% url " ></a > {% endif
del request.session[key]:删除指定的key
静态文件 导入静态文件:
按月归档 1 Post.objects.dates('created_time' , 'month' , order='DESC' )
这里 dates 方法会返回一个列表 ,列表中的元素为每一篇文章(Post)的创建时间,且是 Python 的 date 对象,精确到月份,降序排列。
接受的三个参数值表明了这些含义,一个是 created_time ,即 Post 的创建时间,month 是精度,order='DESC' 表明降序排列(即离当前越近的时间越排在前面)。
例如我们写了 3 篇文章,分别发布于 2017 年 2 月 21 日、2017 年 3 月 25 日、2017 年 3 月 28 日,那么 dates 函数将返回 2017 年 3 月 和 2017 年 2 月这样一个时间列表,且降序排列,从而帮助我们实现按月归档的目的。
AbstractUser 系统默认用户的继承使用:
继承AbstractUser
修改setting.py里的AUTH_USER_MODEL = ‘user.UserProfile’
重新执行迁移同步.
只有继承了abstractuser类的用户模型才能使用logout,login和authenticate .
authenticate和login是一起使用的先验证后登录 :
先使用authenticate进行用户的数据库查询判断,如果有则返回用户对象
login(request,user):类似于request.session,但是不是使用session属性了,而是使用request.user
Django会处理涉及表单的三个不同部分:
准备并重组数据,以便下一步的渲染
为数据创建HTML表单
接收并处理客户端提交的表单及数据
form.is_valid()返回false的原因一般是
form中的每个field默认都是required的,如果没有填,form.is_valid()就会返回false 。html中的form中的各个field的name一定要和对应的form类的各个field的name保持一致,这也是一个易错点。
慎用自定义form的互相继承,很容易造成form.is_valid()返回false
使用 lform.errors 获取 forms.ValidationError
1 2 lform = UserLoginForm(request.POST) content = {'msg' :lform.errors}
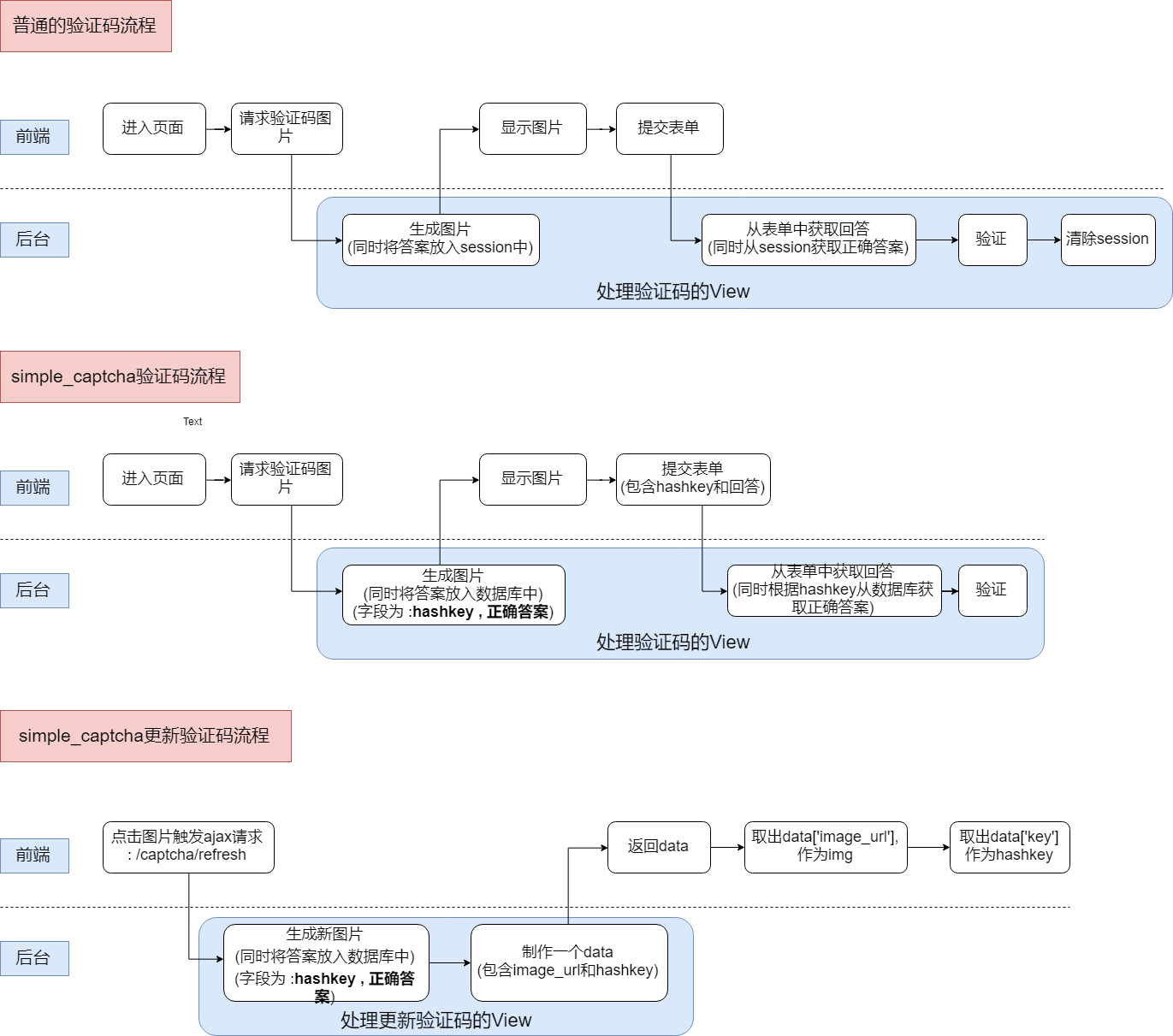
验证码全流程
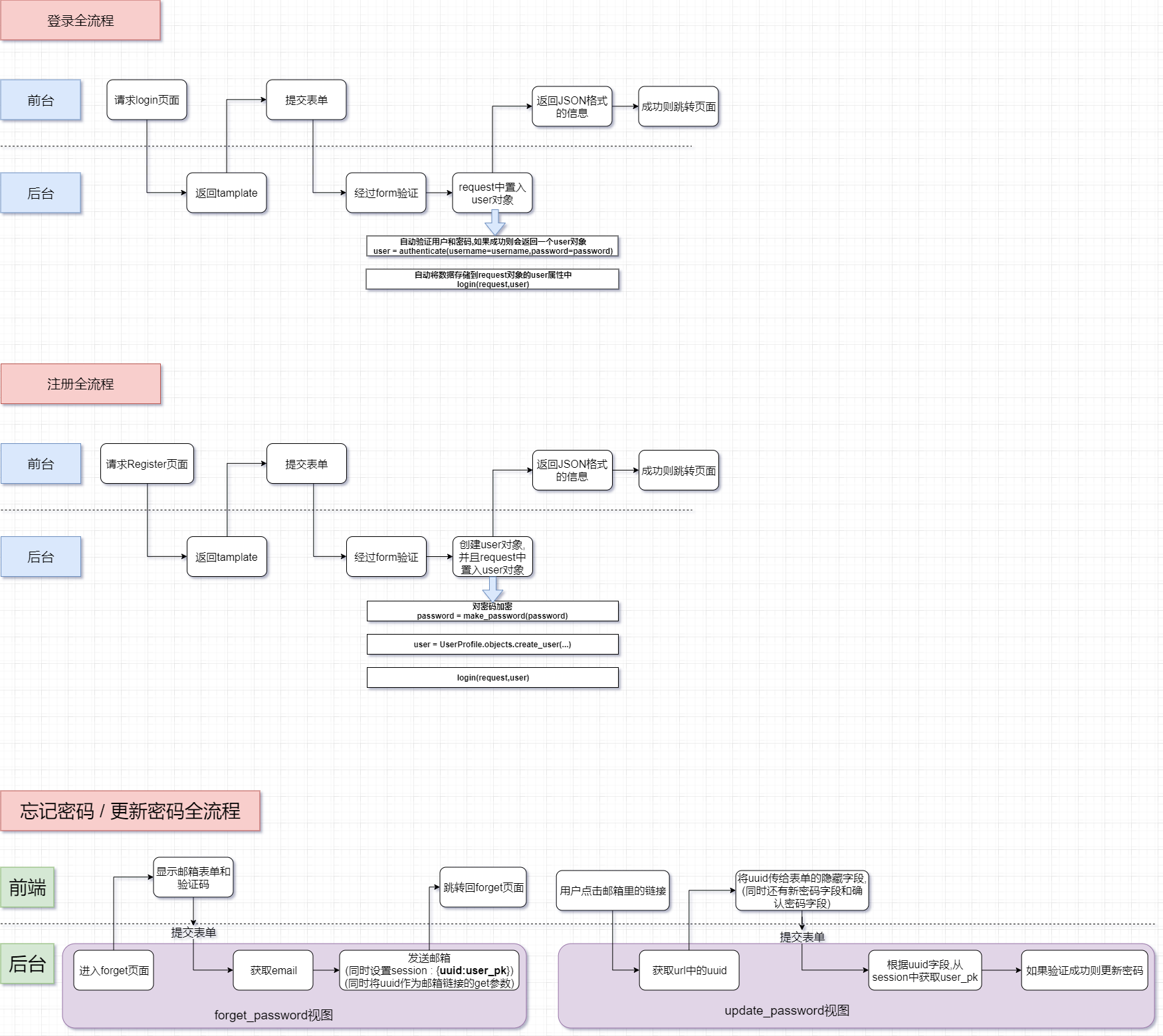
用户全流程
分页 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from django.core.paginator import Paginator, EmptyPage, PageNotAnIntegerfrom django.shortcuts import renderdef listing (request ): contact_list = Contacts.objects.all () paginator = Paginator(contact_list, 25 ) page = request.GET.get('page' ) try : contacts = paginator.page(page) except PageNotAnInteger: contacts = paginator.page(1 ) except EmptyPage: contacts = paginator.page(paginator.num_pages) return render(request, 'list.html' , {'contacts' : contacts})
ListView
ListView : 用来获取某个 model 中的所有数据
DetailView : 从数据库获取模型的一条记录数据
ListView 主要用在获取某个 model 列表中
通过 template_name 属性来指定需要渲染的模板,
复写 get_queryset 方法以增加获取 model 列表的其他逻辑
复写 get_context_data 方法来为上下文对象添加额外的变量 以便在模板中访问
1 2 3 4 5 6 7 8 def index (request ): """ 获取 Article 列表以渲染首页模板 """ article_list = Article.objects.all () category_list = Category.objects.all () context = { 'article_list' : article_list , 'category_list' : category_list } return render_to_response('blog/index.html' ,context)
一个应用中可能会重复书写下面代码:
1 2 3 article_list = Article.objects.all () context = { 'article_list' : article_list } return render_to_response('blog/index.html' ,context)
这些逻辑抽象出来放到一个类里,于是 Django 帮我们写好了一个类,专门用于处理上面的情况,这就是 ListView ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class IndexView (ListView ): model = Post template_name = "blog/index.html" context_object_name = "article_list" def get_queryset (self ): article_list = Article.objects.all () for article in article_list: article.body = markdown2.markdown(article.body, extras=['fenced-code-blocks' ], ) return article_list def get_context_data (self, **kwargs ): kwargs['category_list' ] = Category.objects.all ().order_by('name' ) return super (IndexView, self).get_context_data(**kwargs)
1 2 3 4 5 6 7 8 9 10 class CategoryView (ListView ): model = Post template_name = 'blog/index.html' context_object_name = 'post_list' def get_queryset (self ): cate = get_object_or_404(Category, pk=self.kwargs.get('pk' )) return super ().get_queryset().filter (category=cate)
ListView分页技术
类视图 ListView 已经帮我们写好了上述的分页逻辑,我们只需通过指定 paginate_by 属性来开启分页功能即可
ListView 传递了以下和分页有关的模板变量供我们在模板中使用:
paginator ,即 Paginator 的实例。page_obj ,当前请求页面分页对象。is_paginated,是否已分页。只有当分页后页面超过两页时才算已分页。object_list,请求页面的对象列表,和 post_list 等价。所以在模板中循环文章列表时可以选 post_list ,也可以选 object_list。
1 2 3 4 5 6 7 8 from django.views.generic import ListViewfrom msg_board.models import Msgclass MsgList (ListView ): model = Msg context_object_name = 'msg_list' template_name = 'index.html' paginate_by = 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 {% if <table id = "msgs" > <tr > <th > Title</th > <th > Content</th > <th > Author</th > <th > Ip</th > <th > Time</th > <th > Click</th > </tr > {%for in msg_list %} <tr > <td > {{msg.title}} </td > <td > {{msg.content}} </td > <td > {{msg.user}} </td > <td > {{msg.ip}} </td > <td > {{msg.datetime}} </td > <td > {{msg.click_count}} </td > </tr > {% endfor </table > {% if <div class ="pagination" > <span class ="page-links" > {% if <a href ="/mysite?page= {{ page_obj.previous_page_number }} " ></a > {% endif {% if <a href ="/mysite?page= {{ page_obj.next_page_number }} " ></a > {% endif <span class ="page-current" > 第 {{ page_obj.number }} 页 ,共 {{ page_obj.paginator.num_pages }} 页。 </span > </span > </div > {%endif {% else
DetailView
DetailView主要用在获取某个 model 的单个对象中
通过 template_name 属性来指定需要渲染的模板,通过 context_object_name 属性来指定获取的 model 对象的名字,否则只能通过默认的 object 获取
复写 get_object 方法以增加获取单个 model 对象的其他逻辑
复写 get_context_data 方法来为上下文对象添加额外的变量以便在模板中访问
获取单个 mdoel 对象是很常见的,比如 Blog 里点击某篇文章后进入文章的详情页,这里获取的就是点击这篇文章。
1 2 3 4 def detail (request,article_id ): article = get_object_or_404(Article,pk=article_id) context = { 'article' : article } return render_to_response('blog/detail.html' ,context)
会重复写:
1 article = get_object_or_404(Article,pk=article_id)
Django 通过 DetailView 来把这种逻辑抽象出来,把上面的视图函数转成类视图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class ArticleDetailView (DetailView ): model = Article template_name = "blog/detail.html" context_object_name = "article" pk_url_kwarg = 'article_id' def get_object (self, queryset=None ): obj = super ().get_object() obj.body = markdown2.markdown(obj.body, extras=['fenced-code-blocks' ], ) return obj url(r'^blog/article/(?P<article_id>\d+)$' , views.ArticleDetailView.as_view(), name='detail' )
假设用户点击了第三篇文章,那么该 url 会被解析成:/blog/article/3,其中 3 被传递给了详情页面视图函数。
现在视图函数被调用,它首先根据传给它的参数获自动调用 get_object 方法取到文章的 model,然后根据 context_object_name = “article” 把 article 加入到上下文中
之后渲染 template_name = “blog/detail.html” 指定的模板文件,至此用户就跳转到了文章详情页
Django rest framework 认证
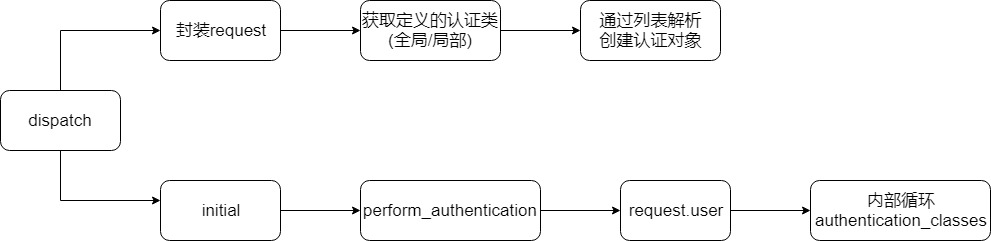
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from rest_framework.views import APIView,exceptionsfrom rest_framework import exceptionsclass Authtication (BaseAuthentication ): def authenticate (self,request ): token = request._request.GET.get('token' ) token_obj = UserToken.objects.filter (token=token).first() if not token_obj: raise exceptions.AuthenticationFailed('用户认证失败' ) return (token_obj.user,token_obj) class OrderView (APIView ): authentication_classes = [Authtication,] def get (self,request,*args,**kwargs ): ret = {'code' :1000 ,'msg' :None ,'date' :None } try : ret['date' ] = ORDER_DICT except Exception as e: pass return JsonResponse(ret)
流程 :
创建类,继承BaseAithentication,实现authenticate()方法
返回值:
None : 不做处理,执行下一个认证
raise exception.AuthenticationFailed(‘用户认证失败’)
(元素1,元素2) : 元素1赋值给request.user , 元素2赋值给request.auth
权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from rest_framework.permissions import BasePermissionclass SVIPPermission (BasePermission ): message = '必须是SVIP才能访问' def has_permission (self,request,view ): if request.user.user_type != 3 : return False return True class OrderView (APIView ): permission_classes = [SVIPPermission,] def get (self,request,*args,**kwargs ): ret = {'code' :1000 ,'msg' :None ,'date' :None } try : ret['date' ] = ORDER_DICT except Exception as e: pass return JsonResponse(ret)
实现流程 :
创建类,继承BasePermission,实现has_permission()方法
返回值:
节流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import timefrom rest_framework.throttling import BaseThrottleVISIT_RECORD = {} class VisitThrottle (BaseThrottle ): def __init__ (self ): self.history = None def allow_request (self,request,view ): remote_addr = request.META.get('REMOTE_ADDR' ) ctime = time.time() if remote_addr not in VISIT_RECORD: VISIT_RECORD[remote_addr] = [ctime,] return True self.history = VISIT_RECORD.get(remote_addr) while self.history and self.history[-1 ] < ctime - 10 : self.history.pop() if len (self.history) < 3 : self.history.insert(0 ,ctime) return True def wait (self ): return 10 - (time.time() - self.history[-1 ]) class OrderView (APIView ): throttle_classes = [VisitThrottle,] def get (self,request,*args,**kwargs ): ret = {'code' :1000 ,'msg' :None ,'date' :None } try : ret['date' ] = ORDER_DICT except Exception as e: pass return JsonResponse(ret)
实现流程
创建类
继承BaseThrottle,实现allow_reques()方法和wait()方法.
继承SimpleRateThrottle,实现get_cache_key()方法和scope类属性(settings.py中哦key)
返回值:
版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 url(r'api/(?P<version>[v1|v2]+)/user/$' ,views.UserView.as_view(),name='user' ), from rest_framework.versioning import BaseVersioningclass ParamVersion (BaseVersioning ): def determine_version (self,request,*args,**kwargs ): version = request.query_params.get('version' ) return version class UserView (APIView ): versioning_class = ParamVersion def get (self,request,*args,**kwargs ): x = request.version y = request.versioning_scheme return HttpResponse(str (x))
一般使用内置类,全局使用:
1 2 3 4 5 6 7 from rest_framework.versioning import QueryParameterVersioningclass UserView (APIView ): def get (self,request,*args,**kwargs ): x = request.version return HttpResponse(str (x))
1 2 3 4 5 6 7 REST_FRAMEWORK = { 'DEFAULT_VERSIONING_CLASS' : 'rest_framework.versioning.URLPathVersioning' , 'DEFAULT_VERSION' : 'v1' , 'ALLOWED_VERSIONS' : ['v1' ,'v2' ], 'VERSION_PARAM' : 'version' , }
实现流程:
使用配置文件 :
1 2 3 4 5 6 REST_FRAMEWORK = { 'DEFAULT_VERSIONING_CLASS' : 'rest_framework.versioning.URLPathVersioning' , 'DEFAULT_VERSION' : 'v1' , 'ALLOWED_VERSIONS' : ['v1' ,'v2' ], 'VERSION_PARAM' : 'version' , }
urls.py :
1 url(r'api/(?P<version>[v1|v2]+)/user/$' ,views.UserView.as_view(),name='user' ),
解析器
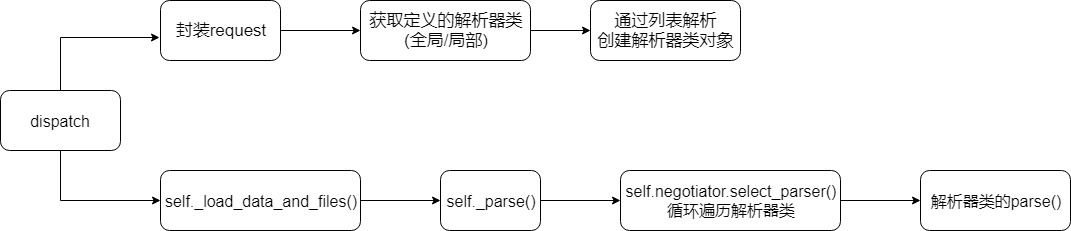
简单来说就是
在dispatch将各种解析器封装到request中
当我们想要使用数据的时候request.data触发self._load_data_and_files(),
然后使用反射找到合适的解析器类,
最后触发解析器类的parse()方法去解析数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 url(r'^api/(?P<version>[v1|v2]+)/user/$' ,views.UserView.as_view(),name='user' ), from rest_framework.parsers import JSONParser,FormParserclass UserView (APIView ): parser_classes = [JSONParser,FormParser,] def post (self,request,*args,**kwargs ): print (request.data) return HttpResponse('hyl' )
一般使用内置类,全局使用:
1 2 3 REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASS' : ['rest_framework.parsers.JSONParser' ,'rest_framework.parsers.FormParser' ] }
序列化
对请求数据进行校验 使用方法和django form一模一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class UserInfoSerializer (serializers.Serializer ): name = serializers.CharField(error_messages={'required' :'标题不能为空' }) age = serializers.IntegerField() def validate_name (self,value ): if value.startswith("w" ): raise serializers.ValidationError('name字段不能以w开头' ) else : return value class UserView (APIView ): def post (self,request,*args,**kwargs ): ser = UserInfoSerializer(data=request.data) if ser.is_valid(): print ('------------' ,ser.validated_data) else : print ('------------' ,ser.errors) return HttpResponse('******' )
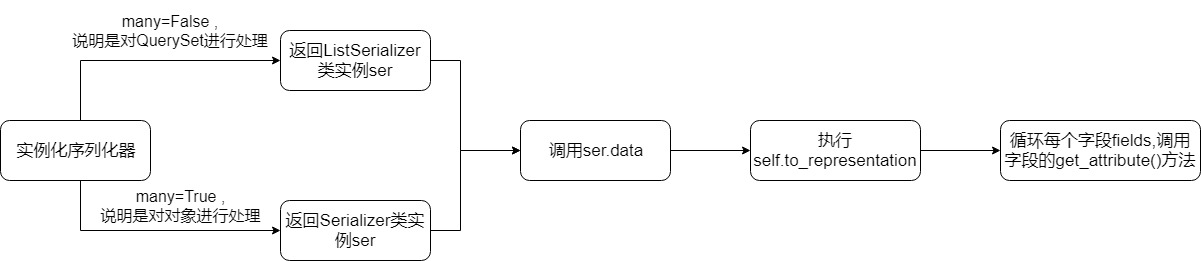
对QuerySet进行序列化 使用方法很像Scrapy中的Item :
先定义字段,然后在实例化的时候传入数据就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from rest_framework import serializersclass RolesSerializer (serializers.Serializer ): id = serializers.IntegerField() title = serializers.CharField() class RoleView (APIView ): def get (self,request,*args,**kwargs ): roles = Role.objects.all ().values('id' ,'title' ) ser = RolesSerializer(instance=roles,many=True ) res = json.dumps(ser.data,ensure_ascii=False ) return HttpResponse(res)
source参数
对于field1 = serializers.IntegerField(source='id'),其实是扫描每一行row,然后执行row.source(这里就是row.id)
如果row.source是一个可执行对象,那么就会执行该对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class UserInfoSerializer (serializers.Serializer ): filed2 = serializers.CharField(source='get_user_type_display' ) group_title = serializers.CharField(source='group.title' ) roles = serializers.CharField(source='roles.all' ) roles2 = serializers.SerializerMethodField() def get_roles (self,row ): role_obj_list = row.roles.all () ret = [{'id' :item.id ,'title' :item.title} for item in role_obj_list] return ret
ModelSerializer
ModelSerializer和Serializer的关系,类似于form和ModelForm的关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class UserInfoSerialier (serializers.ModelSerializer ): field1 = serializers.CharField(source='get_user_type_display' ) rls = serializers.SerializerMethodField() class Meta : model = UserInfo fields = ['id' ,'username' ,'field1' ,'rls' ,'group' ] depth = 1 def get_roles (self,row ): role_obj_list = row.roles.all () ret = [{'id' :item.id ,'title' :item.title} for item in role_obj_list] return ret
depth参数 :
当你获取的字段是外键获取多对多键的时候,depth就是获取外键或多对多键的数据.
分页
看第n页,每页显示n条数据,
在某个位置,向后查看n条数据;
加密分页,只能看上一页和下一页
看第n页,每页显示n条数据, 如果我们想要自定义分页,只需继承PageNumberPagination即可:
page_size : 每页的数据数量(默认)
page_size_query_param : 制定每页的数量(局部)
max_page_size : 每页最多的数据数量
page_query_param : url中表示页数的参数(默认是page)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from rest_framework.pagination import PageNumberPaginationclass MyPageNumberPagination (PageNumberPagination ): page_size = 2 page_size_query_param = 'size' max_page_size = 10 page_query_param = 'page' class UserView (APIView ): def get (self,request,*args,**kwargs ): users = UserInfo.objects.all () pg = MyPageNumberPagination() pager = pg.paginate_queryset(queryset=users,request=request,view=self) ser = UserInfoSerializer(instance=pager,many=True ) return Response(ser.data)
接下来就可以使用page和size控制数据了
在某个位置,向后查看n条数据 使用LimitoffsetPagination
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from rest_framework.pagination import LimitOffsetPaginationclass MyPageNumberPagination2 (LimitOffsetPagination ): default_limit = 2 limit_query_param = 'limit' offset_query_param = 'offset' max_limit = 5 class UserView (APIView ): def get (self,request,*args,**kwargs ): users = UserInfo.objects.all () pg = MyPageNumberPagination2() pager = pg.paginate_queryset(queryset=users,request=request,view=self) ser = UserInfoSerializer(instance=pager,many=True ) return Response(ser.data)
接下来就可以使用limit和offset控制数据了
加密分页,只能看上一页和下一页 使用cursorPagination
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from rest_framework.pagination import cursorPaginationclass MyPageNumberPagination3 (CursorPagination ): cursor_query_param = 'cursor' page_size = 2 ordering = 'id' page_size_query_param = None max_page_size = None class UserView (APIView ): def get (self,request,*args,**kwargs ): users = UserInfo.objects.all () pg = MyPageNumberPagination3() pager = pg.paginate_queryset(queryset=users,request=request,view=self) ser = UserInfoSerializer(instance=pager,many=True ) return pg.get_paginated_response(ser.data)
视图
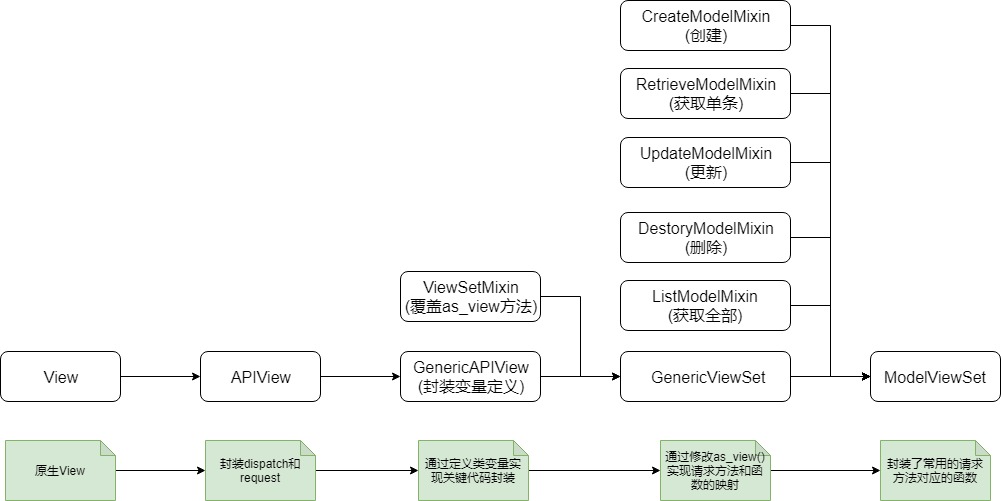
GenericAPIView 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from rest_framework.generics import GenericAPIViewclass UserView (GenericAPIView ): queryset = UserInfo.objects.all () serializer_class = UserInfoSerializer pagination_class = PageNumberPagination def get (self,request,*args,**kwargs ): users = self.get_queryset() pager = self.paginate_queryset(users) ser = self.get_serializer(instance=pager,many=True ) return Response(ser.data)
只是将定义变量提前了而已
GenericViewSet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 url(r'^api/(?P<version>[v1|v2]+)/users/$' ,views.UserView.as_view({'get' :'list' ,'post' :'xxx' }),name='users' ) from rest_framework.viewsets import GenericViewSetclass UserView (GenericViewSet ): serializer_class = UserInfoSerializer queryset = UserInfo.objects.all () pagination_class = PageNumberPagination def list (self,request,*args,**kwargs ): users = self.get_queryset() pager = self.paginate_queryset(users) ser = self.get_serializer(instance=pager,many=True ) return Response(ser.data) def xxx (self,request,*args,**kwargs ): return Response('post' )
GenericViewSet的唯一功能 :as_view({'get':'list','post':'xxx'})
将get请求映射到list方法,让list方法处理.让post请求交给xxx方法处理
ModelViewSet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 urlpatterns = [ url(r'^api/(?P<version>[v1|v2]+)/users/$' ,views.UserView.as_view({'get' :'list' ,'post' :'create' }),name='users' ), url(r'^api/(?P<version>[v1|v2]+)/users/(?P<pk>\d+)/$' ,views.UserView.as_view({'get' :'retrieve' ,'delete' :'destory' ,'put' :'update' ,'patch' :'partical_update' }),name='users' ), ] from rest_framework.viewsets import ModelViewSetclass UserView (ModelViewSet ): serializer_class = UserInfoSerializer queryset = UserInfo.objects.all () pagination_class = PageNumberPagination
get : list(获取全部数据)
get : retrieve (获取单条数据)
post : create
delete : destory
put : update (更新单条数据)
patch : partical_update (更新全部数据)
路由 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from rest_framework import routersfrom django.conf.urls import url,includefrom . import viewsrouter = routers.DefaultRouter() router.register(r'users' ,views.UserView) urlpatterns = [ url(r'api/(?P<version>[v1|v2]+)/' ,include(router.urls)) ]
渲染器
渲染器定义了框架按照content_type来返回不同的响应。
解析器的classes一样,renderer_classes有什么,这个视图就支持怎么样的渲染
1 2 url(r'^api/(?P<version>[v1|v2]+)/role/$' ,views.RoleView.as_view(),name='role' )
1 2 3 4 5 6 7 8 9 10 from rest_framework.renderers import JSONRendererclass RoleView (APIView ): renderer_classes = [JSONRenderer,] def get (self,request,*args,**kwargs ): roles = Role.objects.all ().values('id' ,'title' ) ser = RolesSerializer(instance=roles,many=True ) res = json.dumps(ser.data,ensure_ascii=False ) return Response(res)