路由
1 |
|
上面两段的区别:
- app.route(‘/test/‘) : 在浏览器中输入http://127.0.0.1:5000/test/ 和http://127.0.0.1:5000/test都能访问
- app.route(‘/test’) : 在浏览器中输入http://127.0.0.1:5000/test 能正常访问, 输入http://127.0.0.1:5000/test/ 报错Not found
总结:当我们设计路由时,如果后面加了‘/’ ,当用户输入的url末尾没有”/“ ,Flask会自动响应一个重定向,转向路由末端带有‘/’的url
converter类型:
- string接收任何没有斜杠的文件(默认)
- int 接收整型
- float 接收浮点型
- path 接收路径,可接收斜线
- uid 只接受uuid字符串,唯一码,一种生成规则
- any 可以同时指定多种路径,进行限定
模板
四个内置对象,一个方法
- request
- config
- g
- current_user
- get_flashed_message
四个重要的结构标签
- block
- extends
- include
- macro
{{ super() }}
在使用{% extends 'xx' %}继承后,能保留块中的内容
{% include 'xxx' %}
包含,将其他html包含进来 , 体现的是由零到一的概念
marco
宏定义 , 可以在模板中定义函数 , 在其他地方调用
1 | {# hyl.html #} |
宏定义可以导入
1 | {% from 'hyl.html' import hello %} |
{% for %}
- loop.first
- loop.last
- loop.index
- loop.reindex
- loop.index()
- loop.reindex()
过滤器
{{ 变量 | 过滤器 | 过滤器 | ... }}
- captitalize
- lower
- upper
- title
- trim
- reverse
- format
- safe
- default
- last
- first
- length
- sum
- sort
- striptags : 渲染之前,将值中标签去掉
- …
模型
常用的SQLAlchemy字段类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
常用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
常用的SQLAlchemy关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
常用的SQLAlchemy查询过滤器
- 用来过滤数据,返回查询的结果集
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
常用的SQLAlchemy查询执行器
- 用来执行结果集,得到具体数据
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回404 |
| get() | 返回指定主键对应的行,如不存在,返回None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回404 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个Paginate对象,它包含指定范围内的结果 |
migrate找不到的问题
我们在Model.py里新建了Model,执行python manager.py db migrate 却返回No changes in schema detected.
原因 : 没人知道我们新建了一个Model . 所以只要在View.py里面import就可以了
get_or_404的代码其实超级简单
1 | def get_or_404(self,ident): |
常用约束
- primary_key
- autonimcrement
- unque
- index
- nullable
- default
- ForeignKey
Model的继承问题
1 | class Animal(db.Model): |
将上面migrate后,发现
就只有Aniaml表,Dog,cat都没有
Aniaml表拥有字段id,a_name,d_legs,c_eat
当我们执行
1
2
3
4
5
6cat = Cat()
cat.a_name = '加菲猫'
car.c_eat = '花鱼'
db.session.add(cat)
db.session.commit()之后 , Anmail表就会多一行 . 同理也可以添加一行Dog
- 就是说 , 将所有的字段都揉进了Animal表中
- Django的做法是创建三个表 , 并且以外键的形式链接
要想实现Django的做法只需将Animal改为抽象表:
1
2
3
4class Animal(db.Model):
__abstract__ = True
id = db.Column(db.Integer,primary_key=True,autonicrement=True)
a_name = db.Column(db.String(16))这样 , 当我们再执行上面插入的操作的使用就会创建一张Cat表和一张Dog表
总结 :
- 默认继承并不会报错,它会将多个模型的数据映射到一张表中,导致数据混乱,不能满足基本使用
- 抽象的模型是不会在数据库中产生映射的 :
__abstract__ = True
SQlalchemy的连接池
- Django和Flask默认都是有数据库连接池的
数据查询汇总
获取单个对象
- first
- get
- get_or_404
获取结果集
- all : 返回列表
- filter :
- 返回BaseQuery对象
__str__输出的是这个对象数据的SQL- 方法1 :
类名.属性名.魔术方法(临界值)(eg :Cat.query.filter(Dog.id.__eq__(2)).all()) - 方法2 :
类名.属性名 比较运算符 临界值(eg :Cat.qeury.filter(Cat.id==2)) - 方法3 :
Cat.qeury.filter_by(id=2)
- 不同于DJango , 在flask-sqlalchemy中,all必须放在最后
运算符
- contains
- startswith
- endswith
- in_
- like
- __gt__
- __ge__
- __lt__
- __le__
使用:
1 | cats = Cat.query.filter(Dog.id.__eq__(2)).all() |
筛选
- filter_by()
- offest()
- limit()
- order_by()
- get()
- first()
- paginate()
使用 :
1 | # 编写时offset和limit顺序无所谓 , 最后都是先执行offset |
使用offset和limit模拟分页
1 | def get_dog(): |
之后访问http://127.0.0.1:5000/user?page=2&per_page=3即可
使用paginate分页
1 | def get_with_page(): |
此时paginate()方法会自动处理url中的page参数和per_page参数
paginate()的部分源码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
if page is None:
try:
page = int(request.args.get('page', 1))
except (TypeError, ValueError):
if error_out:
abort(404)
page = 1
if per_page is None:
try:
per_page = int(request.args.get('per_page', 20))
except (TypeError, ValueError):
if error_out:
abort(404)
per_page = 20
else:
if page is None:
page = 1
if per_page is None:
per_page = 20
常用分页手法
1 |
|
1 | <ul> |
iter_pages源码:
2
3
4
5
6
7
8
9
10
11
12
right_current=5, right_edge=2):
last = 0
for num in xrange(1, self.pages + 1):
if num <= left_edge or \
(num > self.page - left_current - 1 and
num < self.page + right_current) or \
num > self.pages - right_edge:
if last + 1 != num:
yield None
yield num
last = num
Pagination对象的属性和方法:
- items
- page
- pages
- prev
- has_prev
- perv_num
- next
- has_next
- next_num
模板
如果我们想获取APP外的template怎么办?
可以在定义app的时候设置template的位置:
1
app = Flask(__name__,template_folder='../templates')
也可以在蓝图里设置
1
domains_app = Blueprint('domains', __name__, template_folder='templates', static_folder="static")
- 模板路径默认在Flask(app)创建的路径下
- 如果想自己指定模板路径
- 在Flask创建的时候,指定template_folder
- 在蓝图创建的时候,也可以templatefolder
- 蓝图的
url_prefix参数还可以指定此蓝图统一前缀:/xx
静态资源
- 静态资源在Flask中是默认支持的
- 默认路径在和Flask同级别的static中
- 想要自己指定
- 可以Flask创建的时候指定static_folde
- 也可以在蓝图中
- 指定静态资源也是有路由的
- endpoint是static
- 参数有一个filename
{{ url_for('static',filename='xxx') }}
模板特殊的变量
在一个 for 循环块中你可以访问这些特殊的变量:
| 变量 | 描述 |
|---|---|
| loop.index | 当前循环迭代的次数(从 1 开始) |
| loop.index0 | 当前循环迭代的次数(从 0 开始) |
| loop.revindex | 到循环结束需要迭代的次数(从 1 开始) |
| loop.revindex0 | 到循环结束需要迭代的次数(从 0 开始) |
| loop.first | 如果是第一次迭代,为 True 。 |
| loop.last | 如果是最后一次迭代,为 True 。 |
| loop.length | 序列中的项目数。 |
| loop.cycle | 在一串序列间期取值的辅助函数。见下面示例程序。 |
自定义过滤器
过滤器的本质是函数。
1 |
|
1 | <h2>my_array 原内容:{{ my_array }}</h2> |
包含
Jinja2模板中,除了宏和继承,还支持一种代码重用的功能,叫包含(Include)。它的功能是将另一个模板整个加载到当前模板中,并直接渲染。
1 | {% include 'hello.html' %} |
1 | <body> |
提示: ignore missing 加上后如果文件不存在,不会报错
小结
- 宏(Macro)、继承(Block)、包含(include)均能实现代码的复用。
- 继承(Block)的本质是代码替换,一般用来实现多个页面中重复不变的区域。
- 宏(Macro)的功能类似函数,可以传入参数,需要定义、调用。
- 包含(include)是直接将目标模板文件整个渲染出来。
模板中特有的变量和函数
config
从模板中直接访问Flask当前的config对象:
1
{{config.DEBUG}}
request
就是flask中代表当前请求的request对象:
1
{{request.url}}
g
在视图函数中设置g变量的 name 属性的值,然后在模板中直接可以取出
1
{{ g.name }}
url_for()
url_for会根据传入的路由器函数名,返回该路由对应的URL,在模板中始终使用url_for()就可以安全的修改路由绑定的URL,则不比担心模板中渲染出错的链接:
1
{{url_for('home')}}
get_flashed_messages()
- 这个函数会返回之前在flask中通过flask()传入的消息的列表,
- flash函数的作用很简单,可以把由Python字符串表示的消息加入一个消息队列中,再使用get_flashed_message()函数取出它们并消费掉:
1
2
3{%for message in get_flashed_messages()%}
{{message}}
{%endfor%}
视图
Flask加载配置
Flask配置有以下三种方式:
app.config.from_object(): 从配置对象中加载(常用)app.config.from_pyfile(): 从配置文件中加载app.config.from_envvar(): 从环境变量中加载(了解)
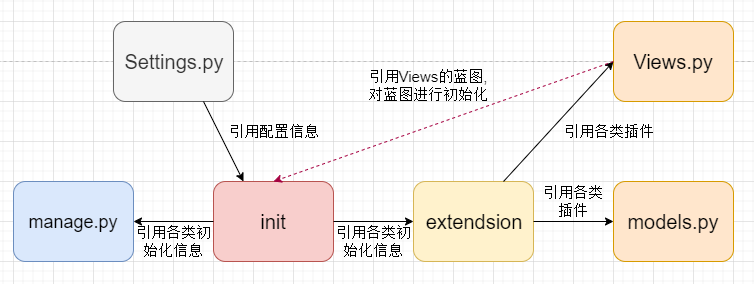
项目拆分
- 目的
- 代码结构更清晰
拆分方案:
- 一拆六
- 以前就有一个manage文件
- manage进行全局控制
- 应用初始化
- 初始化配置
- 初始化路由
- 初始化第三方
- 配置文件
- 配置项目所需各种信息
- 视图函数
- 用来处理业务逻辑,协调模板和模型
- 模型文件
- 定义模型
- 外部扩展
- 统一管理扩展
1 | # manage.py |
1 | # app/__init__.py |
1 | # views.py |
1 | # ext.py |
1 | # settings.py |
1 | # models.py |
blueprint直接使用装饰器 , 用来注册路由