第四章
代码规范问题:
1 | # 错误写法 |
1 | # 当导入的内容过多时,使用括号换行 |
1 | # 错误写法 |
顶级的类或者方法周围(上下)应该各有两个空行.
类内部的方法周围(上下)需要各有一个空行。
1 | # 错误写法: |
import语句需要放到文件的顶部,在模块注释和文档注释之后,且在模块级全局变量和常量定义之前。
1 | ''' |
import的顺序:
- future
- 标准库
- 第三方库
- 本项目的其他模块
各组引用之间要用空行分隔,每一组引用中按照 import在from上面的顺序,并且需要根据字母排序。
eg:
1 | import time |
对于Django来说:
- future
- 标准库
- 第三方库
- Django库
- 本项目的其他模块
模板风格
1 | {# 错误写法 #} |
模型风格:
使用下划线而不是驼峰.
模型类型顺序:
- 字段定义
- 自定义managers属性
- class Meta定义
- def __str__
- def save
- def get_absolute_url
- 其他方法
choices字段的用法:
如果用到了带有 choices参数的字段,choices的定义需要大写
1 | SEX_TIMES = [ |
第五章:Model
Django中每个App应该是一个自组织的应用
(所谓自组织,是指应用内部的所有逻辑都是相关联的,可以理解为是紧耦合的).
我们既可以把所有模型放到一个App中,也可以根据 Model的业务性质来分别处理.
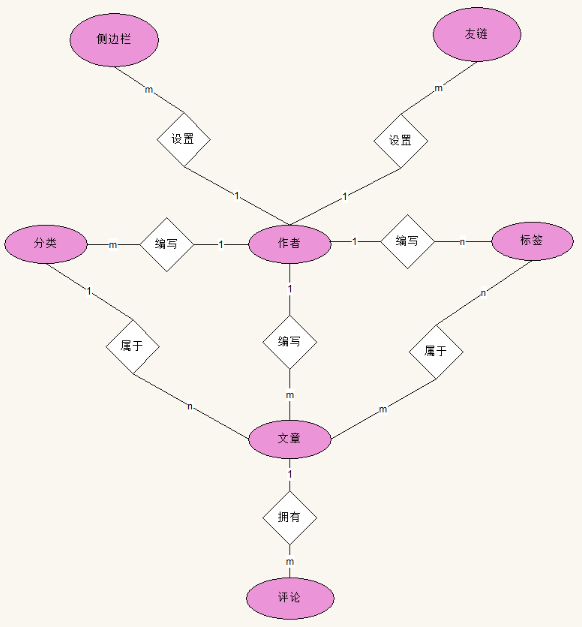
我们将这个ER图拆分成三个APP来做:
1 | # blogapp.py |
1 | # configapp.py |
1 | # commentapp.py |
可以看出:
- ForeignKey写在
多方. - PositiveIntegerField:
同 IntergerField,只包含正整数
INSTALLED_APPS:
Django是根据这些App的顺序来查找对应资源的。比如static和 templates这些模块,Django会根据顺序挨个去这些App下查找对应资源,如果资源路径和名称相同的话,前面的会覆盖掉后面的。
这同时也有好处:
如果你想覆盖自带的Admin,你就可以自己写一个,然后排在自带你Admin的前面,这样Django就会加载你写的Admin,同时又不用修改自带的Admin
迁移文件(migration):
就是把我们的 Model定义迁移到数据库中来具体操作。
DML:
数据库数据操作语言,
CRUD:
增、查、改、删
model类参数:
- null:
可以同blank对比考虑,其中null用于设定在数据库层面是否允许为空. - blank:
针对业务层面,该值是否允许为空. - choices:
配置字段的 choices后,==在 admin页面上就可以看到对应的可选项展示==. - db_column:
默认情况下,我们定义的 Field就是对应数据库中的字段名称,通过这个参数可以==指定Model中的某个字段对应数据库中的哪个字段==. - db_index:
索引配置.对于业务上需要经常作为查询条件的字段,应该配置此项. - default:
默认值配置 - editable:
是否可编辑,默认是True.==如果不想将这个字段展示到页面上,可以配置为False== - error_messages:
用来自定义字段值校验失败时的异常提示,它是字典格式.
key的可选项为null、blank、invalid、invalid_choice、unique和 unique_for_ate. - help_text.
字段提示语,配置这一项后,在页面对应字段的下方会展示此配置. - primary_key.
主键,一个Model只允许设置一个字段为 primary_key - unique.
唯一约束,当需要配置唯一值时,设置 unique=True,设置此项后,不需要设置 db_index. - unique_for_date.
针对date(日期)的联合约束,比如我们需要一天只能有一篇名为《学习Django实战》的文章,那么可以在定义tittle字段时配置参数:uniquefordate=”created_time” - unique_for month.
针对月份的联合约束. - unique_for year.
针对年份的联合约束 - verbose name.
==字段对应的展示文案.== - validators.
自定义校验逻辑,同form类似
在 Model层中,Django通过给 Model增加一个objects属性来提供数据操作的接口.
懒加载:代码执行后,都不会产生数据库查询操作,只是会返回一个QuerySet对象
1 | # 返回一个QuerySet对象并赋位给 posts |
objects的各种接口
支持链式调用的借口:
- all接口.
相当于 SELECT * FROM table_name语句,用于查询所有数据. - filter接口.
顾名思义,根据条件过滤数据,常用的条件基本上是字段等于、不等于、大于、小于.
当然还有其他的,比如能改成产生LIKE查询的:Model.objects.filter(content__contains=”条件”) - exclude接口.
同 filter,只是相反的逻辑. - reverse接口.
把QuerySet中的结果倒序排列. - distinct接口.
用来进行去重查询,产生 SELECT DISTINCT这样的SQL查询 - none接口.
返回空的 QuerySet
不支持链式调用的接口
get 接口:
get接口的一般使用方法:1
2
3
4try :
post = Post.objects.get(id=l)
except Post.DoesNotExist:
...create 接口:
直接创建一个 Model 对象get_or_create接口.
根据条件查找,如果没查找到,就调用 create创建.update_or_create接口.
同get_or_create,只是用来做更新操作.count接口.
用于返回 QuerySet有多少条记录,相当于 SELECT COUNT(*) FROM tablename.latest接口.
用于返回最新的一条记录,但是需要在 Model的Meta中定义:get_latest_by= <用来排序的字段>earliest接口.
同上,返回最早的一条记录.first接口.
从当前 Queryset记录中获取第一条.last接口.
同上,获取最后一条.exists接口.
返回True或者False,在数据库层面执行SELECT (1) As "a" FROM table_name LIMIT 1的查询,如果只是需要判断Queryset是否有数据,用这个接口是最合适的方式.不要用 count或者len(queryset)这样的操作来判断是否存在.
相反,如果可以预期接下来会用到 QuerySet中的数据,可以考虑使用len(queryset)的方式来做判断,这样可以减少一次DB查询请求.bulk_create接口.
同create,用来批量创建记录. (bulk:大量的)in_bulk接口.
批量查询,接收两个参数id_list和field_name.
可以通过Post.objects.in_bulk([1,2,3])查询出id为1、2、3的数据,返回结果是字典类型,字典类型的key为查询条件.返回结果示例:{1:<Post 实例1>,2:<Post 实例2>,3:<Post 实例3>}.update接口.
用来根据条件批量更新记录,比如:Post.objects.filter(owner__name='hyl').update(title='测试更新)delete接口.
同 update,这个接口是用来根据条件批量删除记录.需要注意的是,update和 delete都会触发 Django的 signalvalues接口.
当我们明确知道只需要返回某个字段的值,不需要 Model实例时,可以使用它,用法如下:1
2title_list= Post.objects.filter(category_id=l).values(' title ')
# 返回的结果是包含dict的QuerySet,类似这样:<Queryset[{'title':xxx},]>注意:values实际上是返回一个queryset,而不是真正意义的字典,不可以用它来返回JsonResponse
要想用它来返回字典列表还是乖乖的使用列表解析:
1
2
3result = [{'create_time': datetime.datetime.strftime(each.create_time,'%Y-%m-%d'),
'title': each.title,'pk':each.pk}
for each in articles]values_list接口.
同values,但是直接返回的是包含tuple的 QuerySet:
(values() 类似,只是在迭代时返回的是元组而不是字典)1
2title_list= Post.objects.filter(category_id=l).values_list(' title ')
# 返回的结果是包含tuple的QuerySet,类似这样:<Queryset[('标题',)]>如果只是一个字段的话,可以通过增加flat=True参数,便于我们后续处理
1
2
3
4title_list= Post.objects.filter(category_id=l).values_list(' title ',flat=True)
for title in title_list:
print(title)
进阶接口:
用来提高性能的接口
defer接口.
把不需要展示的字段做延迟加载.
比如说,需要获取到文章中除正文外的其他字段,就可以通过posts = Post.objects.all().defer("content"),这样拿到的记录中就不会包含 content部分.但是当我们需要用到这个字段时,在使用时会去加载.下面还是通过代码演示:1
2
3
4
5posts = Post.objects.all().defer('content')
# 此时会执行数据库查询
for post in posts:
# 此时会执行数据查询,获取到 content
print(post.content)当不想加载某个过大的字段时(如text类型的字段),会使用 defer,但是上面的演示代码会产生N+1的查询问题,在实际使用时千万要注意!
- 上面的代码是一个不太典型的N+1查询的问题.
- 一般情况下由外键查询产生的N+1问题比较多,即一条查询请求返回N条数据,当我们操作数据时,又会产生额外的请求。这就是N+1问题,所有的ORM框架都存在这样的问题
1
2
3
4
5
6
7
8
9
10# 获取所有的文章数据,注意此时不会执行sql语句
posts = Post.objects.all()
result = []
# 此时会执行select * from post的查询
for post in posts:
result.append({
'title': post.title,
# 此时会执行select * from post的查询
'owner': post.owner.name,
})查看上面代码我们得知:每次循环都要查一下user表
only接口
同 defer接口刚好相反,如果只想获取到所有的title记录,就可以使用only,只获取title的内容,其他值在获取时会产生额外的查询.select_related接口.
这就是用来解决外键产生的N+1问题的方案.1
2
3
4
5posts = Post.objects.all()('category')
# 产生数据库查询
for post in posts:
# 产生额外的数据查询
print(post.owner)使用select_related外键不会产生的N+1问题
1
2
3
4post = Post.objects.all().select_related('category')
# 产生数据库查询,category数据也会一次性查询出来
for post in posts:
print(post.category)当然 ,这个接口只能用来解决一对多的关联关系,对于 对多的关系还得使用下面的接口
prefetch_related接口:
针对多对多关系的数据,可以通过这个接口来避免N+1查询。
比如,post和tag的关系可以通过这种方式来避免:1
2
3
4posts = Post.objects.all().prefetch_related('tag')
# 产生两条查询语句,分别查询post和tag
for post in posts:
print (post.tag.all())
常用的字段查询:
- contains:
包含,用来进行相似查询. - icontains:
同 contains,只是忽略大小写. - exact:
精确匹配 - iexact:
同 exact,忽略大小写. - in:
指定某个集合,比如Post.objects.filter(id__in=[1,2,3])相当于SELECT * FROM blog_post WHERE IN(1,2,3) - gt:
大于某个值. - gte:
大于等于某个值. - lt:
小于某个值. - lte:
小于等于某个值. - startswith:
以某个字符串开头,与 contains类似,只是会产生LKE'<关键词>%'这样的SQL. - istartswith:
同 startswith,忽略大小写. - endswith:
以某个字符串结尾. - iendswith:
同 endswith,忽略大小写. - range:
范围查询,多用于时间范围,如Post.objects.filter(created_time__range('2018-05-01','2018-06-01'))会产生这样的查询:SELECT ... WHERE created_time BETWEEN '2018-05-01' AND '2018-06-01';.
进阶查询:
F.
F表达式常用来执行数据库层面的计算,从而避免出现竞争状态.
比如需要处理每篇文章的访问量,假设存在post.pv这样的字段,当有用户访问时,我们对其加11
2
3post = Post.objects.get(id=1)
post.pv = post.pv + 1
pos.save()这在多线程的情况下会出现问题,其执行逻辑是先获取到当前的 pv 值,然后将其加1后赋值给 post.pv,最后保存.如果多个线程同时执行了
post=Post.objects.get(id=1)那么每个线程里的post.pv值都是一样的,执行完加1和保存之后,相当于只执行了个加1,而不是多个.其原因在于我们把数据拿到 Python中转了一圈,然后再保存到数据库中。这时通过F表达式就可以方便地解决这个问题
1
2
3
4
5from django.db.models import F
post = Post.objects.get(id=1)
post.pv = F('pv') + 1
post.save()这种方式最终会产生类似这样的SQL语句:
UPDATE blog_post SET pv=pv+1 WHERE ID=1.它在数据库层面执行原子性操作.简单来说:
F()对象代表一个模型字段的值或注释列。使用它可以直接引用模型字段的值并执行数据库操作而不用把它们导入到python的内存中。Q.
Q表达式就是用来解决OR查询的,可以这么用:1
2from django.db.models import Q
Post.objects.filter(Q(id=1) | Q(id=2))或者 进行AND查询:
1
Post.objects.filter(Q(id=1) & Q(id=2))
Count
用来做聚合查询,比如想要得到某个分类下有多少篇文章,怎么做呢?简单的做法就是1
2category = Category.objects.get(id=1)
posts_count = category.post_set.count()但是如果想要把这个结果放到 category 上呢?通过 category.post_count 可以访问到
1
2
3from django.db.mdoels import Count
categories = Category.objects.annotate(posts_count = Count('post'))
print(categories[O].posts_count)这相当于给category动态增加了属性posts_count ,而这个属性的值来源于
Count('post')Sum.
同 Count类似,只是它是用来做合计的.比如想要统计目前所有文章加起来的访问量有多少,可以这么做:1
2
3from django.db.models import Sum
Post.objects.aggregate(all_pv = Sum('pv'))
# 输出类似结果:{'all_pv':487}
ORM的使用必定会产生损耗.因此,Django还提供了原生SQL的接口Post.objects.raw('SELECT * FROM blog_post'),它除了可以解决 Queryset无法满足查询的情况外,还可以提高执行效率.不过,我们需要严格把控使用场景,因为过多地使用原生SQL会提高维护成本.
第六章:开发管理后台
本章来配置 Django 自带的admin.
Model定义好了字段类型,上层可以据这些字段类型定义Fom中需要呈现以及编辑的字段类型,这样就形成了表单。有了表单之后,基本上就有了增、删、改的页面。而基于Queryset这个数据集合以及它所提供的查询操作,就有了列表的数据以及列表页的操作。
制作用户CategoryAdmin,TagAdmin页面:
这里需要注意:
owner有非空约束,但是我们不可以在Admin页面来选择用户.如果这么做,岂不是任何作者都可以随意把自己创建的内容改为作者的吗?这就是bug了.
此时可以这么做:
把owner这个字段自动设定为当前的登录用户。
这个时候就需要重写 ModelAdmin的save_model方法,其作用是==保存数据到数据库中==。
1 | from django.contrib import admin |
save_model()参数说明:
- request是当前的请求,reqeust.user就是当前已经登录的用户.
(如果是未登录情况,reqeust.user拿到的就是匿名用户对象) - obj就是当前要保存的对象
- form是页面提交过来的表单之后的对象,
- change用于标志本次保存的数据是新增的还是更新的
制作用户PostAdmin页面:
还是在刚才的文件blogapp/admin.py中增加代码
1 |
|
- list_display:
用来配置列表页面展示哪些字段.
- list_display_links:
用来配置哪些字段可以作为链接,点击它们,可以进入编辑页面 - list_filter:
配置页面过滤器,需要通过哪些字段来过滤列表页.上面我们配置了category,这意味着可以通过 category中的值来对数据进行过滤. - search_fields:
配置搜索字段.
- actions_on_top:
动作相关的配置,是否展示在顶部.
- ctions_on bottom:
动作相关的配置,是否展示在底部 - save_on _top:
保存、编辑、编辑并新建按钮是否在顶部展示
- operator.short_description:
指定表头的展示文案。
自定义方法:
在list_display中,如果想要展示自定义字段,如何处理呢?上面的operator就是一个示例。
自定义函数的参数是固定的,就是当前行的对象。列表页中的每一行数据都对应数据表中的条数据,也对应Model的一个实例。
自定义函数可以返回HTML,但是需要通过format _html函数处理,reverse是根据名称解析出URL地址。
1 | # 自定义展示文章数量 |
在上面代码中,分类都是Category object.
这是因为没有定义Category类的__str__的缘故.
1 | class Category(models.Model): |
对于每个 Model,都需要增加这个方法
接下来在设置configapp/admin.py和commentapp/admin.py
1 | # configapp/admin.py |
1 | # commentapp/admin.py |
然后,站点管理就会变成这样: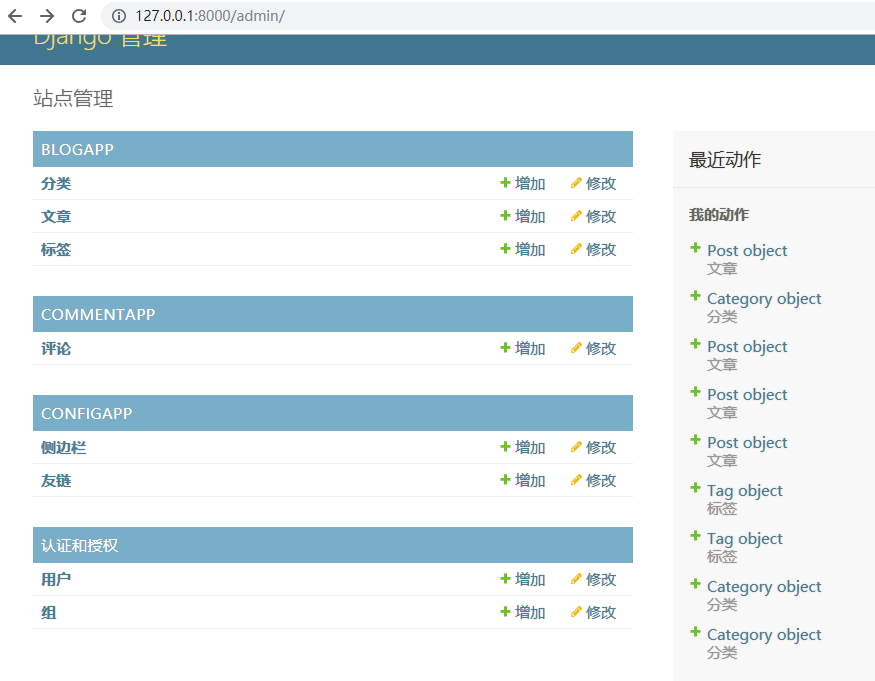
定制Admin页面
通过__(双下划线)的方式指定搜索关联Model。
这种用法可以用于list_display和list_filter。
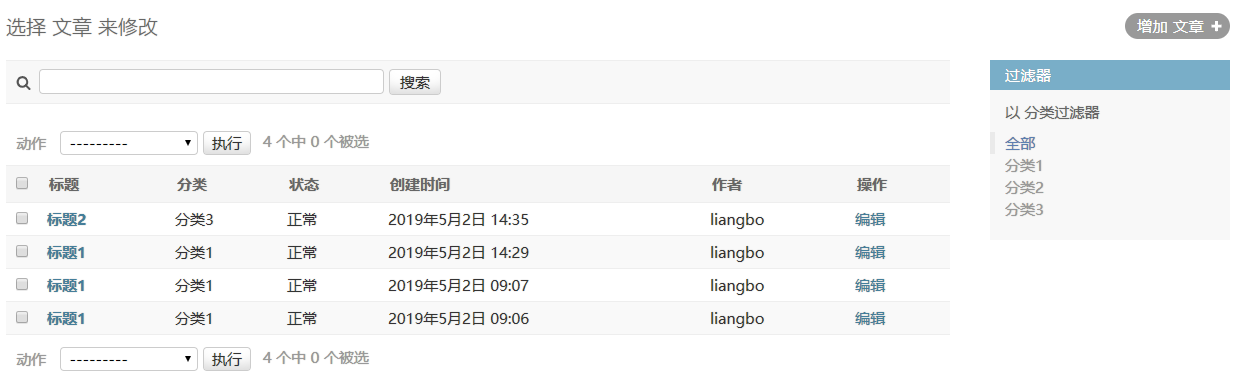
下图,我们可以发现当前用户可以查看其它用户的文章,过滤器也可以查看全部的分类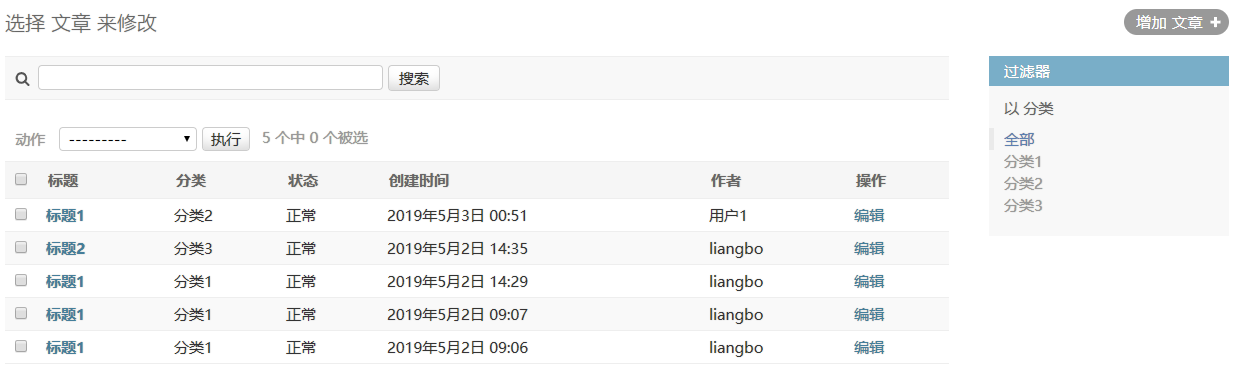
让当前用户只能看到自己的分类
1 | class CategoryOwnerFilter(admin.SimpleListFilter): |
simpleListFilter类提供了两个属性和两个方法来供我们重写.
两个属性的作用顾名思义,
- title
用于展示标题 - parameter_name
查询时URL参数的名字,比如查询分类id为1的内容时,URL后面的Query部分是?owner_category=1,此时就可以通过我们的过滤器拿到这个id,从而进行过滤.
两个方法的作用如下:
- lookups:
返回要展示的内容和查询用的id(就是上面Query用的) - queryset:
根据 URL Query的内容返回列表页数据.比如如果URL最后的 Query是?owner category=1,那么这里拿到的self.value()就是1,此时就会根据1来过滤Queryset.这里的 Queryset是列表页所有展示数据的合集,即post的数据集.
让当前登录的用户在列表页中只能看到自己创建的文章.
1 |
|
使用fieldsets
1 | fieldsets = ( |
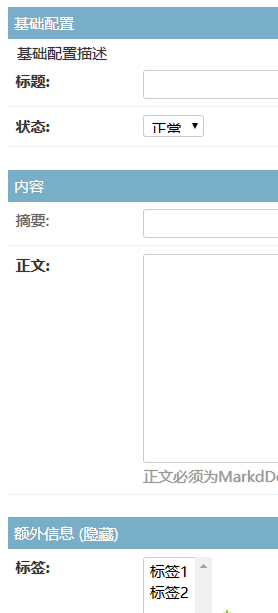
基本语法就是:
1 | fieldsets = ( |
第一个元素是 string,第二个元素是dict,而dict的key可以是fields、description和classes。
- fields:
可以控制展示哪些元素,也可以给元素排序井组合元素的位置 - description:
描述信息 - classes:
给要配置的版块加上一些CSS属性,Django admin默认支持的是collapse和wide.当然,你也可以写其他属性,然后自己来处理样式.
针对多对多字段展示的配置 filter_horizontal和 filter_vertical:
它们用来控制多对多字段的展示效果
1 | filter_horizontal = ('tags',) |
导入静态文件
我们之前介绍的是设置文件夹给普通网页导入静态文件,那么如何给Admin页面导入?
我们可以使用Media类:
1 |
|
自定义 Form
现在我们自定义的Admin界面都是用Django的组件,我们还可以使用Model Form自定义
先在 blogapp 目录下新增一个文件adminfoms.py,
通过Fom来定制 status这个字段的展示:
1 | # adminfoms.py |
将这个PostAdminForm配置到admin.py中
1 | # blogapp/admin.py |
刷新一下页面,就能看到文章描述字段已经改为 Textarea 组件了
在同一页面编辑关联数据
在分类页面直接编辑文章
1 | class PostInline(admin.TabularInline): |
效果
现在我们登录一下admin页面
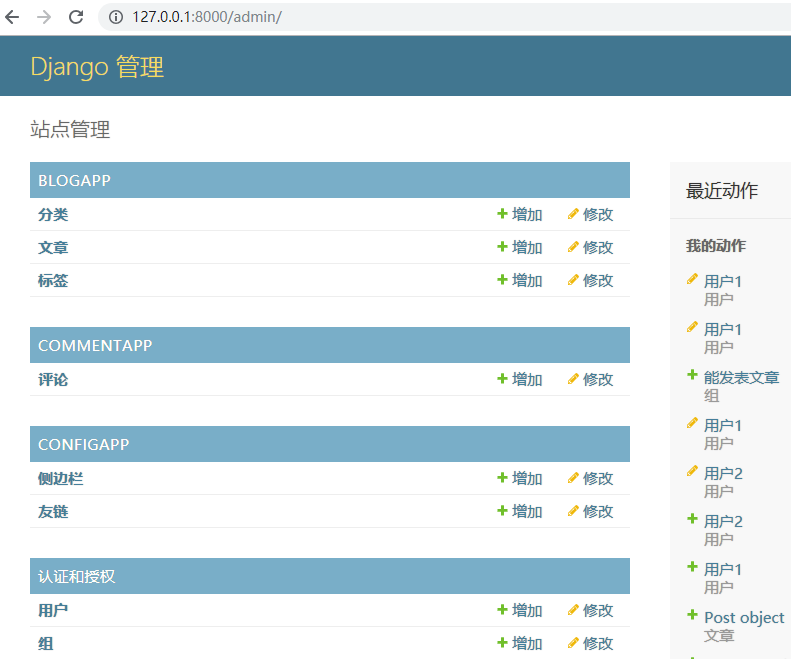
现在后台名称是“Django管理”,这看起来有点奇怪。
新建一个custom_site.py文件:
1
2
3
4
5
6
7
8
9
10# custom_site.py
from django.contrib.admin import AdminSite
class CustomeSite(AdminSite):
site_header = 'Typeidea'
site_title = 'Typeidea 管理后台'
index_title = '首页'
custom_site = CustomeSite(name='cus_site')在blogapp.py中导入:
1
2
3
4
5
6
7from custom_site import custom_site
# 修改装饰器:
# 原先装饰器admin.register(Category)
class CategoryAdmin(admin.ModelAdmin):
...需要注意的是,上面用 reverse方式来获取后台地址时,我们用到了 admin这个名称,因此需要调整 blogapp/admin.py的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13# 原先
def operator(self,obj):
return format_html(
'<a href="{}">编辑</a>',
reverse('admin:blogapp_post_change',args=(obj.id,))
)
# 改为
def operator(self,obj):
return format_html(
'<a href="{}">编辑</a>',
reverse('cus_admin:blogapp_post_change',args=(obj.id,))
)在project/urls.py添加路由:
1
url(r'^super_admin/',admin.site.urls),
这样就有两套后台地址,一套用来管理用户,另外一套用来管理业务。
需要理解的是,这两套系统都是基于一套逻辑的用户系统,只是我们在URL上进行了划分。
admin 的权限逻辑以及 sso 登录
SSO ( Single Sign-On ):单点登录系统
SSO是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
ModelAdmin的配置就对应一个 Model的数据管理页面(列表页、新增页、编辑页、删除页),所以 Modelaamin的配置中包含了这些权限的方法。
- has_add_permission
- has_change _permission
- has_delete_permission
- has_module_permission
如果需要自己实现不同 Model 对应管理功能上的权限逻辑,可以通过重写上面的方法来实现.比如需要判断某个用户是否有添加文章的权限,而权限的管理是在另外的系统上,只提供了一个接口:http://permission.sso.com/has_perm?user=<用户标识>&perm_code=<权限编号>如果有权限,那么响应状态为200;如果没有权限,则为403。
1 | import request |
抽取 Admin 基类:
我们整理一下 admin 的代码, 来保证代码整洁
之前我们在 PostAdmin中重写了save_model方法和 get_queryset方法,
1 | # save_model,其作用是保存数据到数据库中 |
目的是设置文章作者以及当前用户只能看到自己的文章.除了文章管理之外,还有其他模块也需要这么处理.因此,需要做一定程度的抽象
抽象BaseOwnerAdmin基类:
这个类帮我们完成两件事:
- 重写 save_model 方法,此时需要自动设置对象的 owner;
- 重写 get_queryset 方法,让列表页在展示文章或者分类时只能展示当前用户的数据.
首先,在manage.py目录下新创建一个base_admin.py文件
(之所以放这里是因为所有的App都需要用到):
1 | from django.contrib import admin |
接下来只要让管理类继承这个BaseOwnerAdmin即可:
1 | # 原先 |
定制ModelAdmin
ModelAdmin内部提供了两个方法,分别是log_addition和log_change。在官方文档上是看不到这个介绍的,因为它们是内部使用的函数。其功能如命名一样,一个是记录新增日志,一个是记录变更日志。
1 | def log_addition(self, request, object, message): |
参数说明:
- user_id:
当前用户id - content_type_id:
要保存内容的类型,上面的代码中使用的是 get_typefor_model方法拿到对应 Model的类型id.这可以简单理解为 Content Type为每个Mode定义了一个类型id. - object_id:
记录变更实例的id,比如 PostAdmin中它就是post.id - object_repr:
实例的展示名称,可以简单理解为我们定义的__str__所返回的内容. - action_flag:
操作标记.admin的 Model里面定义了几种基础的标记:ADDITION、CHANGE和 DELETTON.它用来标记当前参数是数据变更、新增,还是删除. - change_message:
这是记录的消息,可以自行定义.我们可以把新添加的内容放进去必要时可以通过这里来恢复),也可以把新旧内容的区别放进去.
查询某个对象的变更
如何查询已经记录的变更呢?
其实这是简单的 Model查询问题。假设我们记录的对象是post的操作,现在来获取Post中id为1的所有变更日志,大概代码如下:
1 | from django.contrib.admin.models import LogEntry,CHANGE |
在admin 页面上查看操作日志
我们既知道如何记录变更日志,也知道如何获取变更日志,那么如何才能够在 admin后台方便地查看操作日志呢?
1 | # blogapp/admin.py |