消息队列的引入
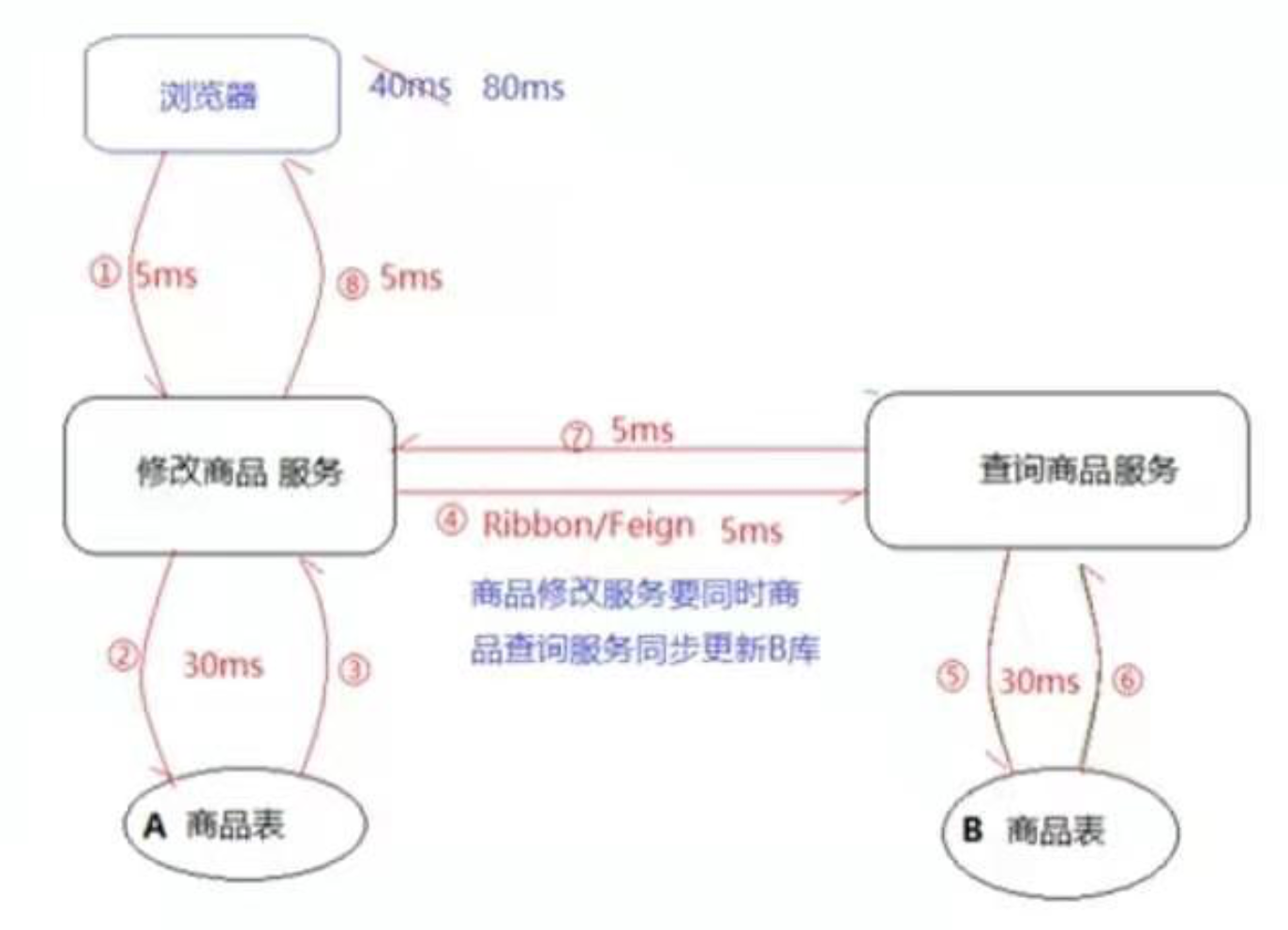
对于这个微服务框架,如下【修改商品服务】和【查询商品服务】。这两个服务都有自己的数据库。
- A商品表和B商品表一定是一致的。
- 下图使用的是同步方式,【修改商品服务】修改为数据表,要等待【查询商品服务】进行修改完毕后才能返回。速度很慢。
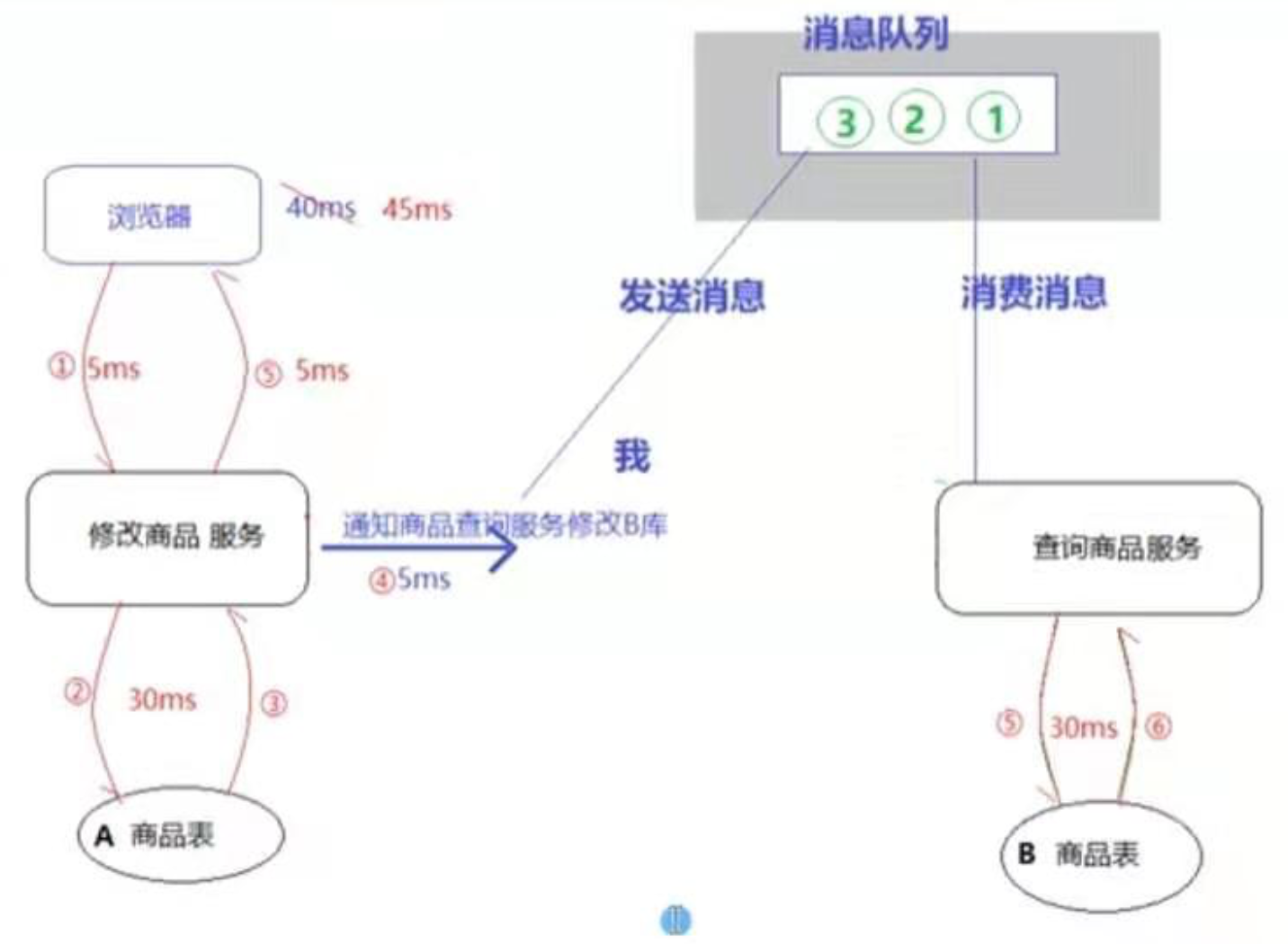
- 如果使用的是异步方式,就可以使用消息队列异步修改【查询商品服务】的数据表,达到数据表的最终一致。
RabbitMQ 简介
RabbitMQ是一个在AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。
AMQP
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
消息队列
MQ 全称为Message Queue, 消息队列。是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
消息队列的使用场景是怎样的?小红和小明读书的例子:
小红是小明的姐姐。小红希望小明多读书,常寻找好书给小明看,之前的方式是这样:小红问小明什么时候有空,把书给小明送去,并亲眼监督小明读完书才走。久而久之,两人都觉得麻烦。后来的方式改成了:小红对小明说「我放到书架上的书你都要看」,然后小红每次发现不错的书都放到书架上,小明则看到书架上有书就拿下来看。
书架就是一个消息队列,小红是生产者,小明是消费者。
这带来的好处有:
小红想给小明书的时候,不必问小明什么时候有空,亲手把书交给他了,小红只把书放到书架上就行了。这样小红小明的时间都更自由。
小红相信小明的读书自觉和读书能力,不必亲眼观察小明的读书过程,小红只要做一个放书的动作,很节省时间。
当明天有另一个爱读书的小伙伴小强加入,小红仍旧只需要把书放到书架上,小明和小强从书架上取书即可(唔,姑且设定成多个人取一本书可以每人取走一本吧,可能是拷贝电子书或复印,暂不考虑版权问题)。
书架上的书放在那里,小明阅读速度快就早点看完,阅读速度慢就晚点看完,没关系,比起小红把书递给小明并监督小明读完的方式,小明的压力会小一些。
这就是消息队列的四大好处:
解耦:
每个成员不必受其他成员影响,可以更独立自主,只通过一个简单的容器来联系。小红甚至可以不知道从书架上取书的是谁,小明也可以不知道往书架上放书的人是谁,在他们眼里,都只有书架,没有对方。毫无疑问,与一个简单的容器打交道,比与复杂的人打交道容易一万倍,小红小明可以自由自在地追求各自的人生。
提速:
小红选择相信「把书放到书架上,别的我不问」,为自己节省了大量时间。小红很忙,只能抽出五分钟时间,但这时间足够把书放到书架上了。
广播:
小红只需要劳动一次,就可以让多个小伙伴有书可读,这大大地节省了她的时间,也让新的小伙伴的加入成本很低。
削峰:
假设小明读书很慢,如果采用小红每给一本书都监督小明读完的方式,小明有压力,小红也不耐烦。反正小红给书的频率也不稳定,如果今明两天连给了五本,之后隔三个月才又给一本,那小明只要在三个月内从书架上陆续取走五本书读完就行了,压力就不那么大了。
当然,使用消息队列也有其成本:
引入复杂度
毫无疑问,「书架」这东西是多出来的,需要地方放它,还需要防盗。
暂时的不一致性
假如妈妈问小红「小明最近读了什么书」,在以前的方式里,小红因为亲眼监督小明读完书了,可以底气十足地告诉妈妈,但新的方式里,小红回答妈妈之后会心想「小明应该会很快看完吧……」这中间存在着一段「妈妈认为小明看了某书,而小明其实还没看」的时期,当然,小明最终的阅读状态与妈妈的认知会是一致的,这就是所谓的「最终一致性」。
那么,该使用消息队列的情况需要满足什么条件呢?
生产者不需要从消费者处获得反馈
引入消息队列之前的直接调用,其接口的返回值应该为空,这才让明明下层的动作还没做,上层却当成动作做完了继续往后走——即所谓异步成为了可能。
小红放完书之后小明到底看了没有,小红根本不问,她默认他是看了,否则就只能用原来的方法监督到看完了。
容许短暂的不一致性
妈妈可能会发现「有时候据说小明看了某书,但事实上他还没看」,只要妈妈满意于「反正他最后看了就行」,异步处理就没问题。如果妈妈对这情况不能容忍,对小红大发雷霆,小红也就不敢用书架方式了。
确实是用了有效果
即解耦、提速、广播、削峰这些方面的收益,超过放置书架、监控书架这些成本。否则如果是盲目照搬,「听说老赵家买了书架,咱们家也买一个」,买回来却没什么用,只是让步骤变多了,还不如直接把书递给对方呢,那就不对了。
RabbitMQ 应用场景
对于一个大型的软件系统来说,它会有很多的组件或者说模块或者说子系统或者子模块(subsystem or Component or submodule)。
那么这些模块的如何通信?这和传统的IPC有很大的区别。传统的IPC很多都是在单一系统上的,模块耦合性很大,不适合扩展(Scalability);
如果使用socket那么不同的模块的确可以部署到不同的机器上,但是还是有很多问题需要解决。比如:
- 信息的发送者和接收者如何维持这个连接,如果一方的连接中断,这期间的数据如何方式丢失?
- 如何降低发送者和接收者的耦合度?
- 如何让Priority高的接收者先接到数据?
- 如何做到load balance?有效均衡接收者的负载?
- 如何有效的将数据发送到相关的接收者?也就是说将接收者订阅了不同的数据,如何做有效的filter。
- 如何做到可扩展,甚至将这个通信模块发到集群上?
- 如何保证接收者接收到了完整,正确的数据?
AMDQ协议解决了以上的问题,而RabbitMQ实现了AMQP。
概念介绍
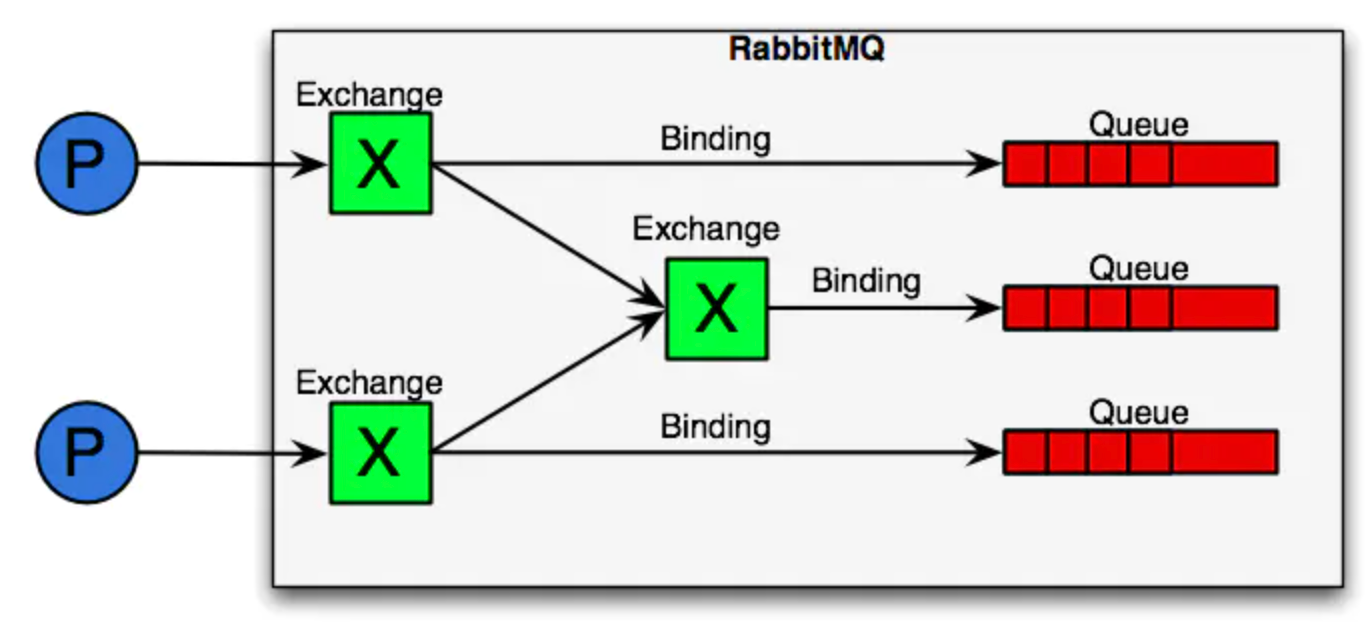
Broker:简单来说就是消息队列服务器实体。Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。Queue:消息队列载体,每个消息都会被投入到一个或多个队列。Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。Routing Key:路由关键字,exchange根据这个关键字进行消息投递。vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。producer:消息生产者,就是投递消息的程序。consumer:消息消费者,就是接受消息的程序。channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
virtual host
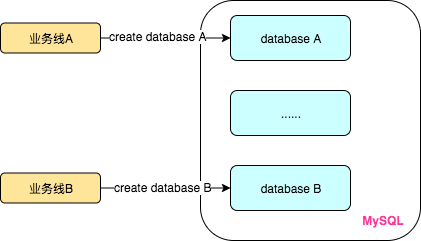
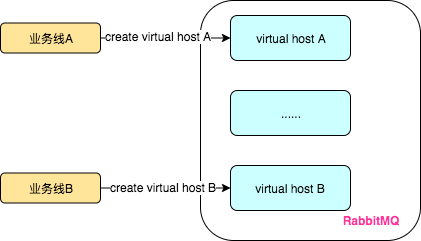
可以通过MySQL和MySQL中的数据库来理解RabbitMQ和virtual host的关系。
MySQL经常会出现多个业务线混用一个MySQL数据库的情况,就像下图这样,每个业务线都在MySQL中创建自己的数据库,使用时各自往各自的数据库中存储数据,彼此相互不干涉。
RabbitMQ和virtual host的关系也差不多,可以让多个业务线同时使用一个RabbitMQ,只要为业务线各个业务线绑定上不同的virtual host即可:
ConnectionFactory、Connection、Channel
ConnectionFactory、Connection、Channel都是RabbitMQ对外提供的API中最基本的对象。
- Connection是RabbitMQ的socket链接,它封装了socket协议相关部分逻辑。
- ConnectionFactory为Connection的制造工厂。
- Channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。
Queue
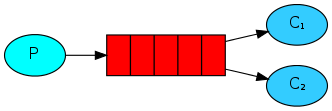
Queue(队列)是RabbitMQ的内部对象,用于存储消息,用下图表示。

RabbitMQ中的消息都只能存储在Queue中,生产者(下图中的P)生产消息并最终投递到Queue中,消费者(下图中的C)可以从Queue中获取消息并消费。

多个消费者可以订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。
Message acknowledgment
- 在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。
- 为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。
注意:这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。
- 这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑
- 另外pub message是没有ack的。
Message durability
- 如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。
- 但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务。由于这里仅为RabbitMQ的简单介绍,所以这里将不讲解RabbitMQ相关的事务。
Prefetch count
消费者在开启acknowledge的情况下,对接收到的消息可以根据业务的需要异步对消息进行确认。然而在实际使用过程中,由于消费者自身处理能力有限,从rabbitmq获取一定数量的消息后,希望rabbitmq不再将队列中的消息推送过来,当对消息处理完后(即对消息进行了ack,并且有能力处理更多的消息)再接收来自队列的消息。在这种场景下,我们可以通过设置basic.qos信令中的prefetch_count来达到这种效果。
如果有多个消费者同时订阅同一个Queue中的消息,Queue中的消息会被平摊给多个消费者。这时如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。
我们可以通过设置prefetchCount来限制Queue每次发送给每个消费者的消息数,比如我们设置prefetchCount=1,则Queue每次给每个消费者发送一条消息;消费者处理完这条消息后Queue会再给该消费者发送一条消息。
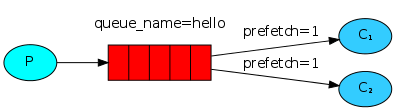
prefetch_count设置测试:两个消费者都订阅同一队列,开启acknowledge机制,第一个消费者prefetch_count设置为1,另一个消费者未设置prefetch_count,同样向队列发布5条消息
结果:rabbitmq向第一个消费者投递了一条消息后,消费者未对该消息进行ack,rabbitmq不会再向该消费者投递消息,剩下的四条消息均投递给了第二个消费者
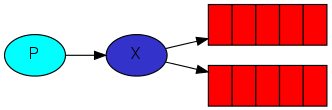
Exchange
生产者将消息发送到Exchange(交换器,下图中的X),由Exchange将消息路由到一个或多个Queue中(或者丢弃)。
routing key
- 生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则,而这个routing key需要与Exchange Type及binding key联合使用才能最终生效。
- 在Exchange Type与binding key固定的情况下(在正常使用时一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,通过指定routing key来决定消息流向哪里。
- RabbitMQ为routing key设定的长度限制为255 bytes。
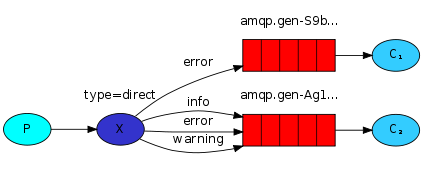
以上图的配置为例,
- 我们以routingKey=”error”发送消息到Exchange,则消息会路由到Queue1(amqp.gen-S9b…,这是由RabbitMQ自动生成的Queue名称)和Queue2(amqp.gen-Agl…);
- 如果我们以routingKey=”info”或routingKey=”warning”来发送消息,则消息只会路由到Queue2。
- 如果我们以其他routingKey发送消息,则消息不会路由到这两个Queue中。
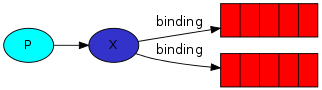
Binding
RabbitMQ中通过Binding将Exchange与Queue关联起来,这样RabbitMQ就知道如何正确地将消息路由到指定的Queue了。
Binding key
在绑定(Binding)Exchange与Queue的同时,一般会指定一个binding key;
消费者将消息发送给Exchange时,一般会指定一个routing key;
当binding key与routing key相匹配时,消息将会被路由到对应的Queue中。
在绑定多个Queue到同一个Exchange的时候,这些Binding允许使用相同的binding key。
binding key 并不是在所有情况下都生效,它依赖于Exchange Type,比如fanout类型的Exchange就会无视binding key,而是将消息路由到所有绑定到该Exchange的Queue。
RPC
MQ本身是基于异步的消息处理,前面的示例中所有的生产者(P)将消息发送到RabbitMQ后不会知道消费者(C)处理成功或者失败(甚至连有没有消费者来处理这条消息都不知道)。
但实际的应用场景中,我们很可能需要一些同步处理,需要同步等待服务端将我的消息处理完成后再进行下一步处理。这相当于RPC(Remote Procedure Call,远程过程调用)。在RabbitMQ中也支持RPC。
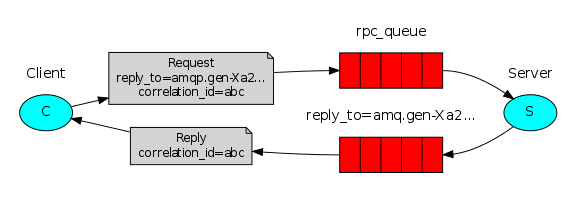
RabbitMQ中实现RPC的机制是:
- 客户端发送请求(消息)时,在消息的属性(MessageProperties,在AMQP协议中定义了14中properties,这些属性会随着消息一起发送)中设置两个值replyTo(一个Queue名称,用于告诉服务器处理完成后将通知我的消息发送到这个Queue中)和correlationId(此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个id了解哪条请求被成功执行了或执行失败);
- 服务器端收到消息并处理;
- 服务器端处理完消息后,将生成一条应答消息到replyTo指定的Queue,同时带上correlationId属性;
- 客户端之前已订阅replyTo指定的Queue,从中收到服务器的应答消息后,根据其中的correlationId属性分析哪条请求被执行了,根据执行结果进行后续业务处理。
RabbitMQ使用流程
AMQP模型中,消息在producer中产生,发送到MQ的exchange上,exchange根据配置的路由方式发到相应的Queue上,Queue又将消息发送给consumer。
消息从queue到consumer有push和pull两种方式。 消息队列的使用过程大概如下:
- 客户端连接到消息队列服务器,打开一个channel。
- 客户端声明一个exchange,并设置相关属性。
- 客户端声明一个queue,并设置相关属性。
- 客户端使用routing key,在exchange和queue之间建立好绑定关系。
- 客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。
rabbitMQ常用的命令
- 启动监控管理器:rabbitmq-plugins enable rabbitmq_management
- 关闭监控管理器:rabbitmq-plugins disable rabbitmq_management
- 启动rabbitmq:rabbitmq-service start
- 关闭rabbitmq:rabbitmq-service stop
- 查看所有的队列:rabbitmqctl list_queues
- 清除所有的队列:rabbitmqctl reset
- 关闭应用:rabbitmqctl stop_app
- 启动应用:rabbitmqctl start_app
用户和权限设置
- 添加用户:rabbitmqctl add_user username password
- 分配角色:rabbitmqctl set_user_tags username administrator
- 新增虚拟主机:rabbitmqctl add_vhost vhost_name
- 将新虚拟主机授权给新用户:
rabbitmqctl set_permissions -p vhost_name username “.*” “.*” “.*”(后面三个”*”代表用户拥有配置、写、读全部权限)
角色说明
- 超级管理员(administrator)
可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。 - 监控者(monitoring)
可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等) - 策略制定者(policymaker)
可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。 - 普通管理者(management)
仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理。 - 其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
RabbitMQ的五种消息模型(Exchange Types)
RabbitMQ支持以下五种消息模型,第六种RPC本质上是服务调用,所以不算做服务通信消息模型。
Hello World(简单模式)

P(producer/ publisher):生产者,发送消息的服务
C(consumer):消费者,接收消息的服务
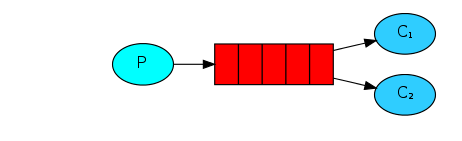
红色区域就是MQ中的Queue,可以把它理解成一个邮箱
- 首先信件来了不强求必须马上去拿
- 其次,它是有最大容量的(受主机和磁盘的限制,是一个缓存区)
- 允许多个消费者监听同一个队列,争抢消息
简单模式:只有一个Q,只有一个C。但是P可以多个
Worker模型(工作模式)
Worker模型中也只有一个工作队列。但它是一种竞争消费模式。可以看到同一个队列我们绑定上了多个消费者,消费者争抢着消费消息,这可以有效的避免消息堆积。
比如对于短信微服务集群来说就可以使用这种消息模型,来了请求大家抢着消费掉。
如何实现这种架构:对于上面的HelloWorld这其实就是相同的服务我们启动了多次罢了,自然就是这种架构。
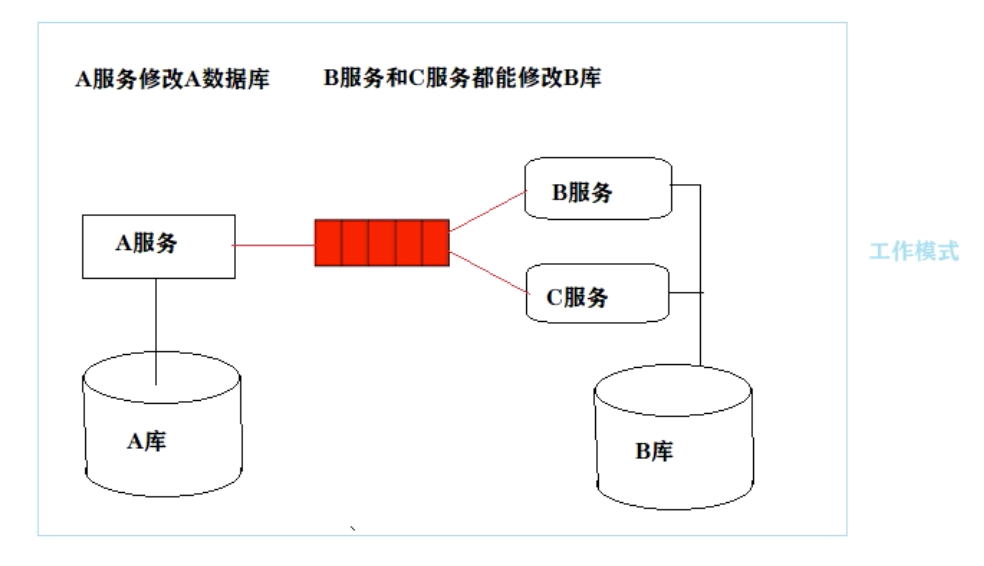
工作模式:多个C监听、竞争同一个Q
举例:需要保持A库和B库的同步。
订阅模型
订阅模型借助一个新的概念:Exchange(交换机)实现,不同的订阅模型本质上是根据交换机(Exchange)的类型划分的。
订阅模型有三种
- Fanout(广播模型): 将消息发送给绑定给交换机的所有队列(因为他们使用的是同一个RoutingKey)。
- Direct(定向): 把消息发送给拥有指定Routing Key (路由键)的队列。
- Topic(通配符): 把消息传递给拥有 符合Routing Patten(路由模式)的队列。
订阅之Fanout模型(广播模式)
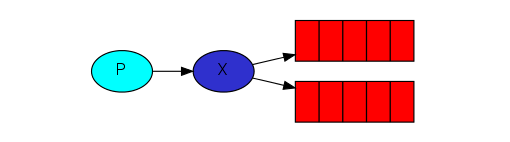
上图中,生产者(P)发送到Exchange(X)的所有消息都会路由到图中的两个Queue,并最终被两个消费者(C1与C2)消费。
这个模型的特点就是它在发送消息的时候,并没有指明Rounting Key , 或者说他指定了Routing Key,但是所有的消费者都知道,大家都能接收到消息,就像听广播。
广播模式:P连接一个交换机,交换机连接多个Q
举例:保持A库,B库和C库同步。
订阅之Direct模型(路由模式)
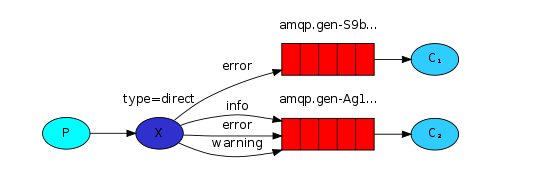
P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
C1:消费者,其所在队列指定了需要routing key 为 error 的消息
C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
拥有不同的RoutingKey的消费者,会收到来自交换机的不同信息,而不是大家都使用同一个Routing Key 和广播模型区分开来。
以上图的配置为例,
- 我们以routingKey=”error”发送消息到Exchange,则消息会路由到Queue1(amqp.gen-S9b…,这是由RabbitMQ自动生成的Queue名称)和Queue2(amqp.gen-Agl…);
- 如果我们以routingKey=”info”或routingKey=”warning”来发送消息,则消息只会路由到Queue2。
- 如果我们以其他routingKey发送消息,则消息不会路由到这两个Queue中。
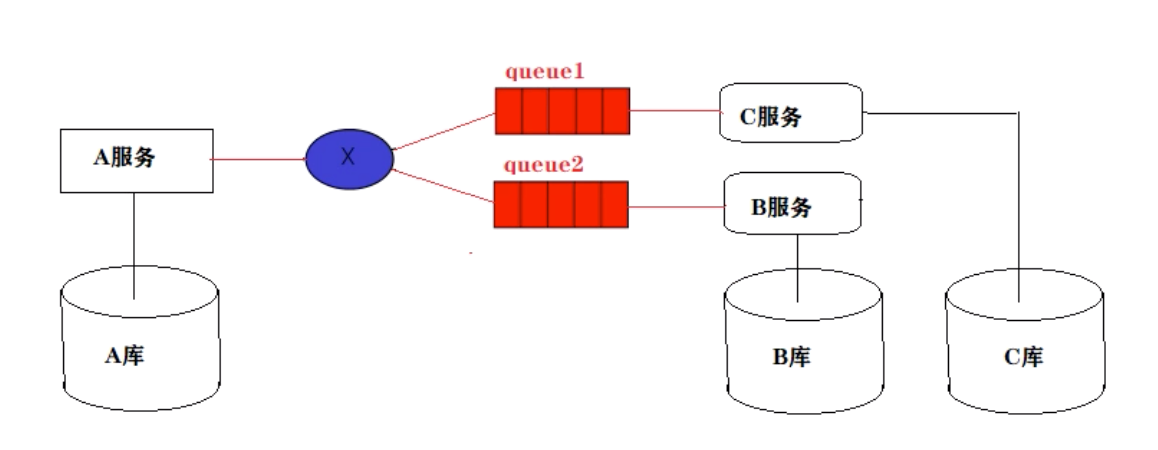
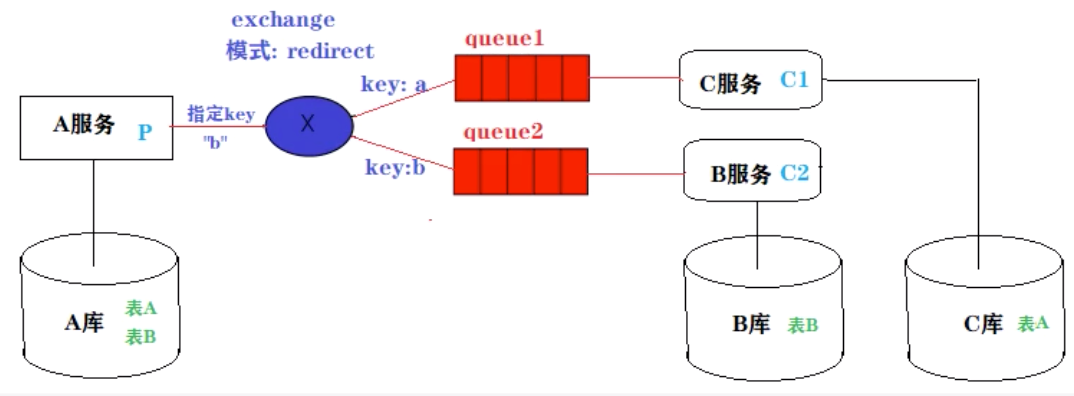
路由模式:一个交换机绑定多个消息队列,每个消息队列都有自己唯一的Key,每个消息队列有一个消费者监听。
举例:要同步A库和B库和C库。但是B库和C库只有A库的部分表。
订阅之Topic模型(通配符模式)
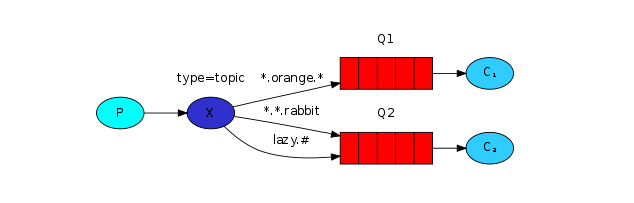
类似于Direct模型。区别是Topic的Routing Key支持通配符。
binding key中可以存在两种特殊字符*与#,用于做模糊匹配,其中*用于匹配一个单词,#用于匹配多个单词(可以是零个)。
以上图中的配置为例,
- routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,
- routingKey=”lazy.orange.fox”的消息会路由到Q1与Q2,
- routingKey=”lazy.brown.fox”的消息会路由到Q2,
- routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);
- routingKey=”quick.brown.fox”、routingKey=”orange”、routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey。