https://blog.csdn.net/weixin_39408343/article/details/95984062
https://blog.csdn.net/huangpb123/article/details/84799198
入门 AST
AST 是什么
抽象语法树 (Abstract Syntax Tree),简称 AST,它是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
AST 有什么用
AST 运用广泛,比如:
- 编辑器的错误提示、代码格式化、代码高亮、代码自动补全;
elint、pretiier对代码错误或风格的检查;webpack通过babel转译javascript语法;
并且如果你想了解 js 编译执行的原理,那么你就得了解 AST。
AST 如何生成
js 执行的第一步是读取 js 文件中的字符流,然后通过词法分析生成 token,之后再通过语法分析( Parser )生成 AST,最后生成机器码执行。
整个解析过程主要分为以下两个步骤:
- 分词:将整个代码字符串分割成最小语法单元数组
- 语法分析:在分词基础上建立分析语法单元之间的关系
JS Parser 是 js 语法解析器,它可以将 js 源码转成 AST,常见的 Parser 有 esprima、traceur、acorn、shift 等。
词法分析
词法分析,也称之为扫描(scanner),简单来说就是调用 next() 方法,一个一个字母的来读取字符,然后与定义好的 JavaScript 关键字符做比较,生成对应的Token。Token 是一个不可分割的最小单元:
例如 var 这三个字符,它只能作为一个整体,语义上不能再被分解,因此它是一个 Token。
词法分析器里,每个关键字是一个 Token ,每个标识符是一个 Token,每个操作符是一个 Token,每个标点符号也都是一个 Token。除此之外,还会过滤掉源程序中的注释和空白字符(换行符、空格、制表符等。
最终,整个代码将被分割进一个tokens列表(或者说一维数组)。
语法分析
语法分析会将词法分析出来的 Token 转化成有语法含义的抽象语法树结构。同时,验证语法,语法如果有错的话,抛出语法错误。
说了这么多我们来看下 javaScript 代码片段转成 AST 之后是什么样的我们拿一行简单的代码来展示
1 | const fn = a => a; |

如图从这个 AST 语法树我们就能够很清楚的看出一个代码他的具体含义,并且使用的是什么语法,方法等。
用人话翻译这个图就是:
用类型 const 声明变量 fn 指向一个箭头函数表达式,它的参数是 a 函数体也是 a。
浅谈 AST
第一部分:AST的作用
首先来一个比较形象的,转载自:AST-抽象语法树,讲述了为什么需要讲源代码转化为AST,总结就是:AST不依赖于具体的文法,不依赖于语言的细节,我们将源代码转化为AST后,可以对AST做很多的操作,包括一些你想不到的操作,这些操作实现了各种各样形形色色的功能,给你带进一个不一样的世界。
原文为:
抽象语法树简介
(一)简介
抽象语法树(abstract syntax code,AST)是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这所以说是抽象的,是因为抽象语法树并不会表示出真实语法出现的每一个细节,比如说,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。抽象语法树并不依赖于源语言的语法,也就是说语法分析阶段所采用的上下文无文文法,因为在写文法时,经常会对文法进行等价的转换(消除左递归,回溯,二义性等),这样会给文法分析引入一些多余的成分,对后续阶段造成不利影响,甚至会使合个阶段变得混乱。因些,很多编译器经常要独立地构造语法分析树,为前端,后端建立一个清晰的接口。
抽象语法树在很多领域有广泛的应用,比如浏览器,智能编辑器,编译器。
(二)抽象语法树实例
(1)四则运算表达式
表达式: 1+3*(4-1)+2
抽象语法树为:
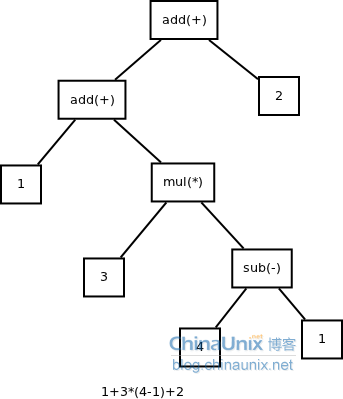
(2)xml
代码2.1:
1 | <letter> |
抽象语法树如下
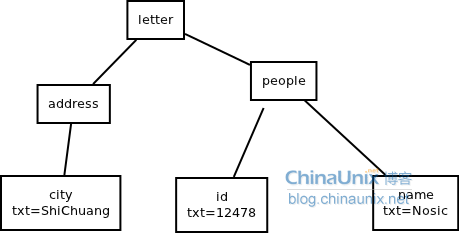
(3)程序1
代码2.2
1 | while b != 0 |
抽象语法树
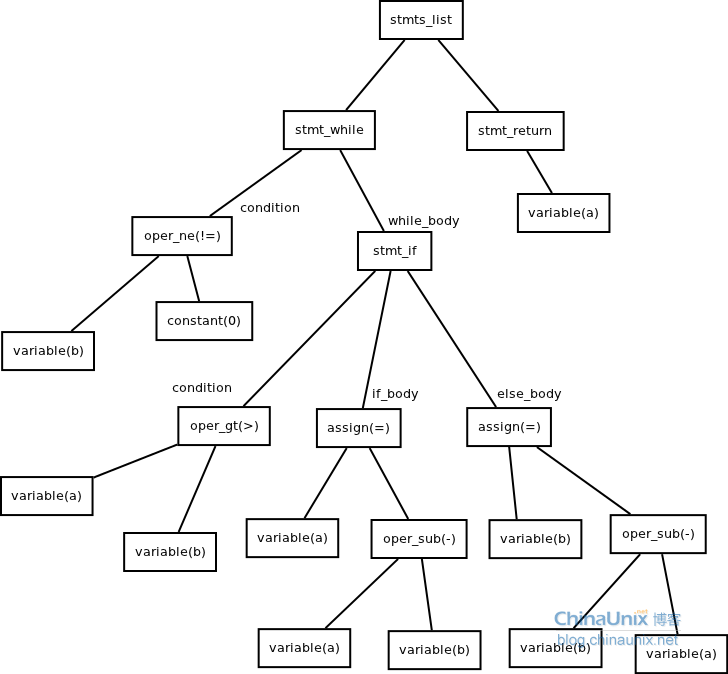
(4)程序2
代码2.3
1 | sum=0 |
抽象语法树
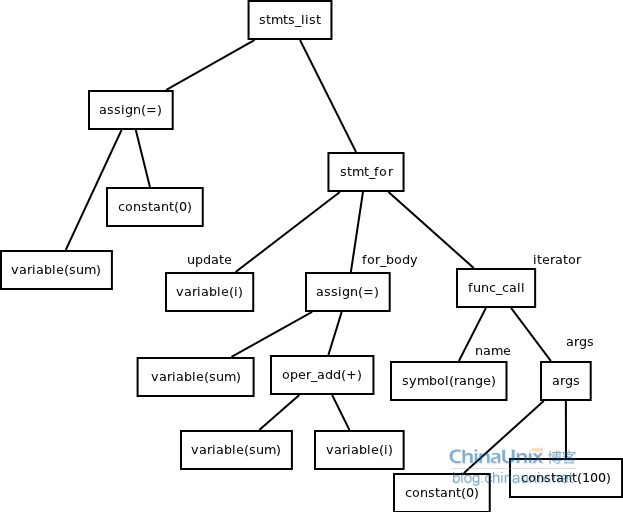
(三)为什么需要抽象语法树
当在源程序语法分析工作时,是在相应程序设计语言的语法规则指导下进行的。语法规则描述了该语言的各种语法成分的组成结构,通常可以用所谓的前后文无关文法或与之等价的Backus-Naur范式(BNF)将一个程序设计语言的语法规则确切的描述出来。前后文无关文法有分为这么几类:LL(1),LR(0),LR(1), LR(k) ,LALR(1)等。每一种文法都有不同的要求,如LL(1)要求文法无二义性和不存在左递归。当把一个文法改为LL(1)文法时,需要引入一些隔外的文法符号与产生式。
例如,四则运算表达式的文法为:
文法1.1
- E->T|EAT
- T->F|TMF
- F->(E)|i
- A->+|-
- M->*|/
改为LL(1)后为:
文法1.2
- E->TE’
- E’->ATE’|e_symbol
- T->FT’
- T’->MFT’|e_symbol
- F->(E)|i
- A->+|-
- M->*|/
例如,当在开发语言时,可能在开始的时候,选择LL(1)文法来描述语言的语法规则,编译器前端生成LL(1)语法树,编译器后端对LL(1)语法树进行处理,生成字节码或者是汇编代码。但是随着工程的开发,在语言中加入了更多的特性,用LL(1)文法描述时,感觉限制很大,并且编写文法时很吃力,所以这个时候决定采用LR(1)文法来描述语言的语法规则,把编译器前端改生成LR(1)语法树,但在这个时候,你会发现很糟糕,因为以前编译器后端是对LL(1)语树进行处理,不得不同时也修改后端的代码。
抽象语法树的第一个特点为:不依赖于具体的文法。无论是LL(1)文法,还是LR(1),或者还是其它的方法,都要求在语法分析时候,构造出相同的语法树,这样可以给编译器后端提供了清晰,统一的接口。即使是前端采用了不同的文法,都只需要改变前端代码,而不用连累到后端。即减少了工作量,也提高的编译器的可维护性。
抽象语法树的第二个特点为:不依赖于语言的细节。在编译器家族中,大名鼎鼎的gcc算得上是一个老大哥了,它可以编译多种语言,例如c,c++,java,ADA,Object C, FORTRAN, PASCAL, COBOL等等。在前端gcc对不同的语言进行词法,语法分析和语义分析后,产生抽象语法树形成中间代码作为输出,供后端处理。要做到这一点,就必须在构造语法树时,不依赖于语言的细节,例如在不同的语言中,类似于if-condition-then这样的语句有不同的表示方法
在c中为:
- if(condition)
- {
- do_something();
- }
在fortran中为:
- If condition then
- do_somthing()
- end if
在构造if-condition-then语句的抽象语法树时,只需要用两个分支节点来表于,一个为condition,一个为if_body。如下图:
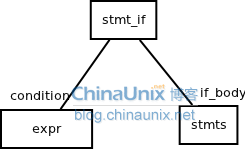
在源程序中出现的括号,或者是关键字,都会被丢掉。
第二部分:AST的流程
此部分让你了解到从源代码到词法分析生成tokens到语法分析生成AST的整个结构,让你对整个流程有一个了解,此部分转载自:详解AST抽象语法树
来看一下把一个简单的函数转换成AST之后的样子。
1 | // 简单函数 |
从纯文本转换成树形结构的数据,每个条目和树中的节点一一对应。
纯文本转AST的实现
当下的编译器都做了纯文本转AST的事情。
一款编译器的编译流程是很复杂的,但我们只需要关注词法分析和语法分析,这两步是从代码生成AST的关键所在。
第一步:词法分析,也叫扫描scanner
它读取我们的代码,然后把它们按照预定的规则合并成一个个的标识 tokens。同时,它会移除空白符、注释等。最后,整个代码将被分割进一个 tokens 列表(或者说一维数组)。
1 | const a = 5; |
当词法分析源代码的时候,它会一个一个字母地读取代码,所以很形象地称之为扫描 - scans。当它遇到空格、操作符,或者特殊符号的时候,它会认为一个话已经完成了。
第二步:语法分析,也称解析器
它会将词法分析出来的数组转换成树形的形式,同时,验证语法。语法如果有错的话,抛出语法错误。
1 | [{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...] |
当生成树的时候,解析器会删除一些没必要的标识 tokens(比如:不完整的括号),因此 AST 不是 100% 与源码匹配的。
解析器100%覆盖所有代码结构生成树叫做CST(具体语法树)。
用例:代码转换之babel
babel 是一个 JavaScript 编译器。宏观来说,它分3个阶段运行代码:
- 解析(parsing) — 将代码字符串转换成 AST抽象语法树,
- 转译(transforming) — 对抽象语法树进行变换操作,
- 生成(generation) — 根据变换后的抽象语法树生成新的代码字符串。
我们给 babel 一段 js 代码,它修改代码然后生成新的代码返回。它是怎么修改代码的呢?没错,它创建了 AST,遍历树,修改 tokens,最后从 AST中生成新的代码。
详解 AST
本文将带大家从底层了解AST,并且通过发布一个小型前端工具,来带大家了解AST的强大功能
Javascript就像一台精妙运作的机器,我们可以用它来完成一切天马行空的构思。我们对javascript生态了如指掌,却常忽视javascript本身。这台机器,究竟是哪些零部件在支持着它运行?
AST在日常业务中也许很难涉及到,但当你不止于想做一个工程师,而想做工程师的工程师,写出vue、react之类的大型框架,或类似webpack、vue-cli前端自动化的工具,或者有批量修改源码的工程需求,那你必须懂得AST。AST的能力十分强大,且能帮你真正吃透javascript的语言精髓。
事实上,在javascript世界中,你可以认为抽象语法树(AST)是最底层。 再往下,就是关于转换和编译的“黑魔法”领域了。
人生第一次拆解Javascript
小时候,当我们拿到一个螺丝刀和一台机器,人生中最令人怀念的梦幻时刻便开始了:我们把机器,拆成一个一个小零件,一个个齿轮与螺钉,用巧妙的机械原理衔接在一起…当我们把它重新照不同的方式组装起来,这时,机器重新又跑动了起来——世界在你眼中如获新生。
通过抽象语法树解析,我们可以像童年时拆解玩具一样,透视Javascript这台机器的运转,并且重新按着你的意愿来组装。
现在,我们拆解一个简单的add函数
1 | function add(a, b) { |
首先,我们拿到的这个语法块,是一个FunctionDeclaration(函数定义)对象。
用力拆开,它成了三块:
- 一个id,就是它的名字,即add
- 两个params,就是它的参数,即[a, b]
- 一块body,也就是大括号内的一堆东西
add没办法继续拆下去了,它是一个最基础Identifier(标志)对象,用来作为函数的唯一标志,就像人的姓名一样。
1 | { |
params继续拆下去,其实是两个Identifier组成的数组。之后也没办法拆下去了。
1 | [ |
接下来,我们继续拆开body
我们发现,body其实是一个BlockStatement(块状域)对象,用来表示是{return a + b}
打开Blockstatement,里面藏着一个ReturnStatement(Return域)对象,用来表示return a + b
继续打开ReturnStatement,里面是一个BinaryExpression(二项式)对象,用来表示a + b
继续打开BinaryExpression,它成了三部分,left,operator,right
- operator 即+
- left 里面装的,是Identifier对象 a
- right 里面装的,是Identifer对象 b
就这样,我们把一个简单的add函数拆解完毕,用图表示就是
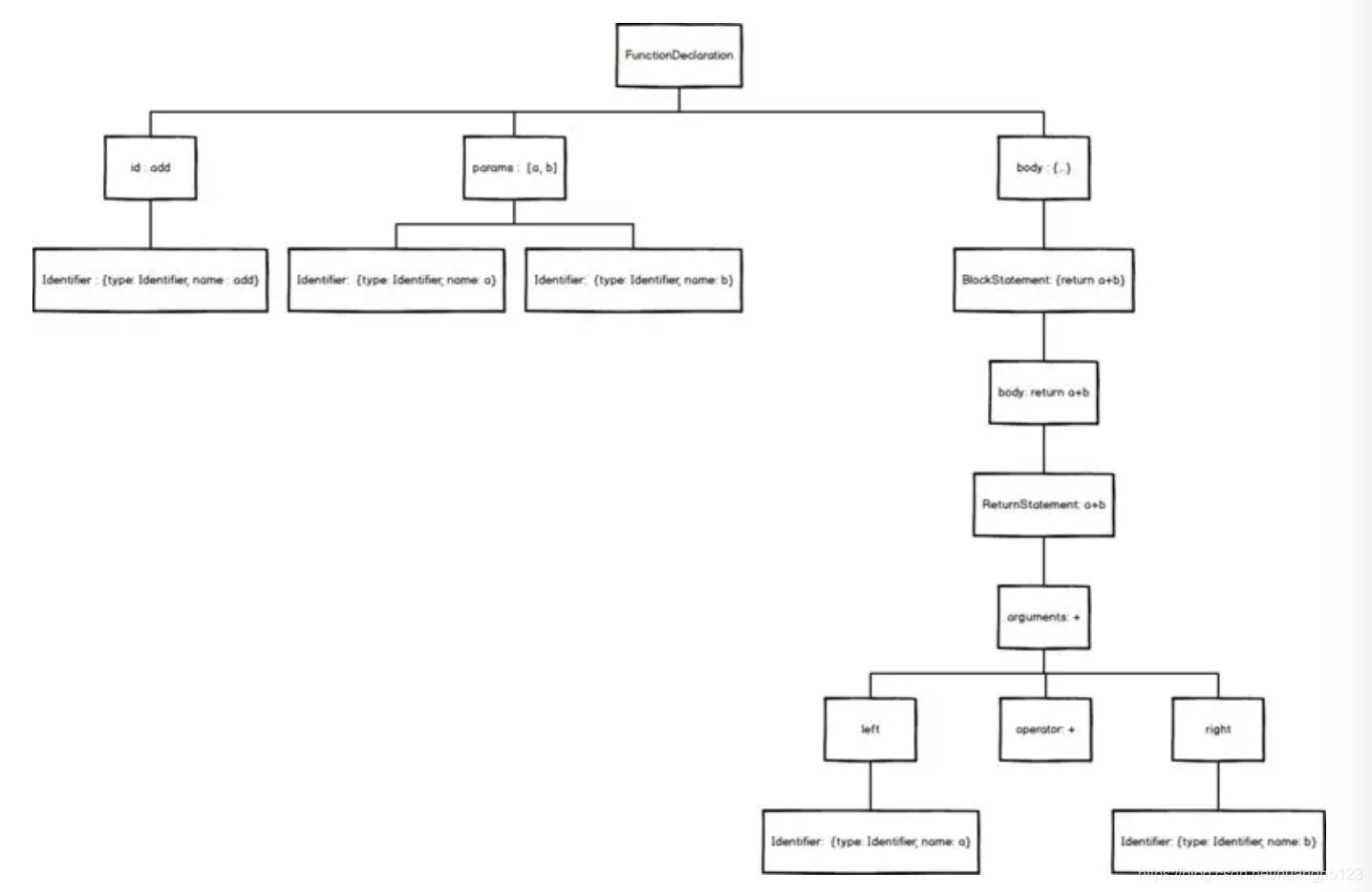
看!抽象语法树(Abstract Syntax Tree),的确是一种标准的树结构。
那么,上面我们提到的Identifier、Blockstatement、ReturnStatement、BinaryExpression, 这一个个小部件的说明书去哪查?
送给你的AST螺丝刀:recast
输入命令:
1 | npm i recast -S |
你即可获得一把操纵语法树的螺丝刀
接下来,你可以在任意js文件下操纵这把螺丝刀,我们新建一个parse.js示意:
1 | // parse.js |
执行node parse.js你可以查看到add函数的结构,与之前所述一致,通过AST对象文档可查到它的具体属性:
1 | FunctionDeclaration{ |
recast.types.builders 制作模具
一个机器,你只会拆开重装,不算本事。拆开了,还能改装,才算上得了台面。
recast.types.builders里面提供了不少“模具”,让你可以轻松地拼接成新的机器。
最简单的例子,我们想把之前的function add(a, b){…}声明,改成匿名函数式声明const add = function(a ,b){…}
如何改装?
- 第一步,我们创建一个VariableDeclaration变量声明对象,声明头为const, 内容为一个即将创建的VariableDeclarator对象。
- 第二步,创建一个VariableDeclarator,放置add.id在左边, 右边是将创建的FunctionDeclaration对象
- 第三步,我们创建一个FunctionDeclaration,如前所述的三个组件,id params body中,因为是匿名函数id设为空,params使用add.params,body使用add.body。
- 这样,就创建好了const add = function(){}的AST对象。
在之前的parse.js代码之后,加入以下代码
1 | // 引入变量声明,变量符号,函数声明三种“模具” |
可以看到,我们打印出了
1 | const add = function(a, b) { |
最后一行
1 | const output = recast.print(ast).code; |
其实是recast.parse的逆向过程,具体公式为
1 | recast.print(recast.parse(source)).code === source |
实战进阶:命令行修改js文件
除了parse/print/builder以外,Recast的三项主要功能:
- run: 通过命令行读取js文件,并转化成ast以供处理。
- tnt: 通过assert()和check(),可以验证ast对象的类型。
- visit: 遍历ast树,获取有效的AST对象并进行更改。
我们通过一个系列小务来学习全部的recast工具库:
创建一个用来示例文件,假设是demo.js
1 | function add(a, b) { |
recast.run —— 命令行文件读取
新建一个名为read.js的文件,写入
1 | recast.run( function(ast, printSource){ |
命令行输入
1 | node read demo.js |
我们查以看到js文件内容打印在了控制台上。
我们可以知道,node read可以读取demo.js文件,并将demo.js内容转化为ast对象。
同时它还提供了一个printSource函数,随时可以将ast的内容转换回源码,以方便调试。
recast.visit —— AST节点遍历
1 |
|
recast.visit将AST对象内的节点进行逐个遍历。
注意
- 你想操作函数声明,就使用visitFunctionDelaration遍历,想操作赋值表达式,就使用visitExpressionStatement。 只要在 AST对象文档中定义的对象,在前面加visit,即可遍历。
- 通过node可以取到AST对象
- 每个遍历函数后必须加上return false,或者选择以下写法,否则报错:
1 |
|
调试时,如果你想输出AST对象,可以console.log(node)
如果你想输出AST对象对应的源码,可以printSource(node)
命令行输入node read demo.js进行测试。
1 | #!/usr/bin/env node |
在所有使用recast.run()的文件顶部都需要加入这一行,它的意义我们最后再讨论。
TNT —— 判断AST对象类型
TNT,即recast.types.namedTypes,就像它的名字一样火爆,它用来判断AST对象是否为指定的类型。
TNT.Node.assert(),就像在机器里埋好的炸药,当机器不能完好运转时(类型不匹配),就炸毁机器(报错退出)
TNT.Node.check(),则可以判断类型是否一致,并输出False和True
上述Node可以替换成任意AST对象,例如TNT.ExpressionStatement.check(),TNT.FunctionDeclaration.assert()
read.js
1 |
|
read.js
1 |
|
命令行输入node read demo.js进行测试。