作用
- 一般我们在C语言中通过指针,在知道变量在内存中占用的字节数情况下,就可以通过指针加偏移量的操作,直接在地址中,修改,访问变量的值。在 Go 语言中不支持指针运算,那怎么办呢?其实通过unsafe包,我们可以完成类似的操作。
- golang是一种静态的强类型的语言,所有的类型都是不能随意转换的,Go语言是不允许两个指针类型进行转换的。
- go官方是不推荐使用unsafe的操作因为它是不安全的,它绕过了golang的内存安全原则,容易使你的程序出现莫名其妙的问题,不利于程序的扩展与维护。但是在很多地方却是很实用。在一些go底层的包中unsafe包被很频繁的使用。
unsafe 定义
在unsafe包中,只提供了3个函数,两个类型。就这么少的量,却有着超级强悍的功能。
1 | package unsafe |
其它的
unsafe包的go代码去哪里了?答案很简单:当你import到你程序里的时候,Go编译器实现了这个unsafe库。许多系统库,例如
runtime,syscall和os会经常使用到usafe库
官方中定义了四个描述:
- 任何类型的指针都可以被转化为Pointer
- Pointer可以被转化为任何类型的指针
- uintptr可以被转化为Pointer
- Pointer可以被转化为uintptr
unsafe中,通过ArbitraryType 、Pointer 这两个类型,可以将其他类型都转换过来,然后通过这三个函数,分别能取长度,偏移量,对齐字节数,就可以在内存地址映射中,来回游走。
事实上,一般在GO里使用的指针的完整称呼应该为类型安全指针。 虽然类型安全指针有助于我们轻松写出安全的代码,但是有时候施加在类型安全指针上的限制也确实导致我们不能写出最高效的代码。
1 | type Pointer *ArbitraryType |
这里的ArbitraryType仅仅是暗示**unsafe.Pointer类型值可以被转换为任意类型安全指针(反之亦然)**。
换句话说,unsafe.Pointer类似于C语言中的void*。
非类型安全指针是指底层类型为unsafe.Pointer的类型。非类型安全指针的零值也使用预声明的nil标识符来表示。
unsafe.Sizeof函数
Sizeof函数返回操作数在内存中的字节大小(返回该类型所占用的内存大小),参数可以是任意类型的表达式,但是它并不会对表达式进行求值。
一个 Sizeof 函数调用是一个对应 uintptr 类型的常量表达式,因此返回的结果可以用作数组类型的长度大小,或者用作计算其他的常量。
Sizeof函数可以返回一个类型所占用的内存大小,这个大小只有类型有关,和类型对应的变量存储的内容大小无关,比如bool型占用一个字节、int8也占用一个字节。
1 | import "unsafe" |
对于整型来说,占用的字节数意味着这个类型存储数字范围的大小,比如int8占用一个字节,也就是8bit,所以它可以存储的大小范围是-128~~127,也就是−2^(n-1)到2^(n-1)−1,n表示bit,int8表示8bit,int16表示16bit,其他以此类推。
对于和平台有关的int类型,这个要看平台是32位还是64位,会取最大的。比如我自己测试,以上输出,会发现int和int64的大小是一样的,因为我的是64位平台的电脑。
1 | func Sizeof(x ArbitraryType) uintptr |
以上是Sizeof的函数定义,它接收一个ArbitraryType类型的参数,返回一个uintptr类型的值。这里的ArbitraryType不用关心,他只是一个占位符,为了文档的考虑导出了该类型,但是一般不会使用它,我们只需要知道它表示任何类型,也就是我们这个函数可以接收任意类型的数据。
1 | // ArbitraryType is here for the purposes of documentation only and is not actually |
Alignof 函数
Alignof返回一个类型的对齐值,也可以叫做对齐系数或者对齐倍数。对齐值是一个和内存对齐有关的值,合理的内存对齐可以提高内存读写的性能。
1 | func main() { |
从以上例子的输出,可以看到,对齐值一般是2^n,最大不会超过8(原因见下面的内存对齐规则)。Alignof的函数定义和Sizeof基本上一样。这里需要注意的是每个人的电脑运行的结果可能不一样,大同小异。
1 | func Alignof(x ArbitraryType) uintptr |
获取对齐值还可以使用反射包的函数,也就是说:unsafe.Alignof(x)等价于reflect.TypeOf(x).Align()。
Offsetof 函数
Offsetof函数只适用于struct结构体中的字段相对于结构体的内存位置偏移量。结构体的第一个字段的偏移量都是0。
1 | func main() { |
字段的偏移量,就是该字段在struct结构体内存布局中的起始位置(内存位置索引从0开始)。
根据字段的偏移量,我们可以定位结构体的字段,进而可以读写该结构体的字段,哪怕他们是私有的。这里可以直接用汇编获取对应偏移量的字段值。
同样也可以用反射表示:
unsafe.Offsetof(u1.i) 等价于 reflect.TypeOf(u1).Field(i).Offset
unsafe的使用
类型转换
使用unsafe可以实现类型的转换,下面的例子可以看到i是一个int类型,使用unsafe.Pointer转换成float64并且还修改了指针对应的值。
1 | func main() { |
但是使用起来要十分的小心,如果使用不当会引发错误。可以举一个例子:
1 | func main() { |
上面的误操作就是把int类型转成了string,并且修改了值导致结果出现了错误,并且这种错误
根据位移获取、修改对象的字段
利用unsafe的Pointer和Offsetof函数,可以获取对象的属性,并且可以修改对象的属性
1 | type Student struct { |
获取私有变量
可以通过unsafe获取私有变量的值,也可以修改值。这个操作跟上面的获取值是一样的简单的例子如下:
1 | type Teacher struct { |
根据sizeof函数获取、修改
利用unsafe中的sizeof函数获取数组的值
1 | func main() { |
- 首先,
pointer变量指向array[0]的地址,array[0]是整型数组的第一个元素。 - 接下来指向整数值的
pointer变量会传入unsafe.Pointer()方法,然后传入uintptr。最后结果存到了memoryAddress里。 unsafe.Sizeof(array[0])是为了去访问下一个数组元素,这个值是每个元素占的内存大小。每次for循环遍历,都会把这个值加到memoryAddress上,这样就能获取到下一个数组元素的地址。*pointer的*符号对指针进行解引用,然后返回了所存的整数值。
内存对齐详解
struct 字段顺序不同,最终大小可能不同
1 | type Part1 struct { |
来看一下 Part1 共占用的大小是多少呢?
1 | func main() { |
然后你也许就会得出这个结果:
Part1 这一个结构体的占用内存大小为 1+4+1+8+1 = 15 个字节。相信有的小伙伴是这么算的,看上去也没什么毛病
但是实际答案却是:
1 | type Part1 struct { |
输出结果:
1 | part1 size: 32, align: 8 |
最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。这充分地说明了先前的计算方式是错误的。为什么呢?
在这里要提到 “内存对齐” 这一概念,才能够用正确的姿势去计算,接下来我们详细的讲讲它是什么
内存对齐
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放

上图表示一个坑一个萝卜的内存读取方式。但实际上 CPU 并不会以一个一个字节去读取和写入内存。
相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度。如下图:
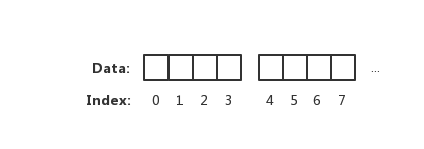
在样例中,假设访问粒度为 4。 CPU 是以每 4 个字节大小的访问粒度去读取和写入内存的。这才是正确的姿势
为什么要关心对齐?
- 你正在编写的代码在性能(CPU、Memory)方面有一定的要求
- 你正在处理向量方面的指令
- 某些硬件平台(ARM)体系不支持未对齐的内存访问
为什么要做对齐
- 平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
- 性能原因:若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作
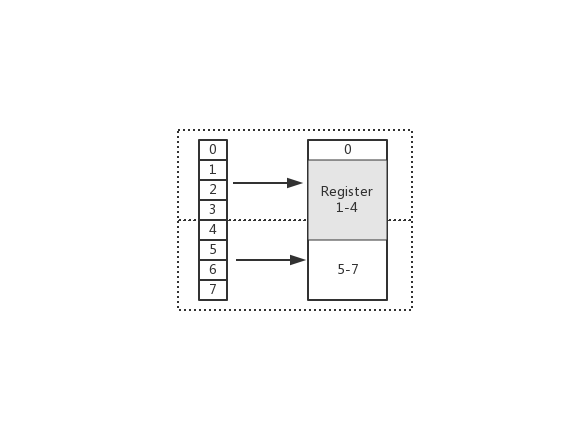
在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下:
- CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
- CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
- 合并 1-4 字节的数据
- 合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 “麻烦” 的事。因为它会增加许多耗费时间的动作
而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。这显然高效很多,是标准的空间换时间做法。
CPU看待内存是以block为单位的,就像是linux下文件大小的单位IO block为4096一样,是一种牺牲空间换取时间的做法.
默认对齐系数
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令 #pragma pack(n) 进行变更,n 就是代指 “对齐系数”。一般来讲,我们常用的平台的系数如下:
- 32 位:4
- 64 位:8
另外要注意,不同硬件平台占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,调试的时候需按本机的实际情况考虑
成员对齐
1 | func main() { |
关于 unsafe.Alignof 是用来来返回相应类型的对齐系数,上面已经说了。
通过观察输出结果,可得知基本都是 2^n,最大也不会超过 8。这是因为我本机(64 位)编译器默认对齐系数是 8,因此最大值不会超过这个数
整体对齐 (结构体本身也要对齐)
上面提到了结构体中的成员变量要做字节对齐。那么想当然身为最终结果的结构体,也是需要做字节对齐的。
对齐规则
- 结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(#pragma pack(n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍
- 结构体本身,对齐值必须为编译器默认对齐长度(#pragma pack(n))或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值
- 结合以上两点,可得知若编译器默认对齐长度(#pragma pack(n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
换个说法就是:
- 对于具体类型来说,对齐值=
min(编译器默认对齐值,类型大小Sizeof长度)。也就是在默认设置的对齐值和类型的内存占用大小之间,取最小值为该类型的对齐值。我的电脑默认是8,所以最大值不会超过8. - struct在每个字段都内存对齐之后,其本身也要进行对齐,对齐值=
min(默认对齐值,字段最大类型长度)。这条也很好理解,struct的所有字段中,最大的那个类型的长度以及默认对齐值之间,取最小的那个。
分析流程
1 | type Part1 struct { |
| 成员变量 | 类型 | 偏移量 | 自身占用 |
|---|---|---|---|
| a | bool | 0 | 1 |
| 字节对齐 | 无 | 1 | 3 |
| b | int32 | 4 | 4 |
| c | int8 | 8 | 1 |
| 字节对齐 | 无 | 9 | 7 |
| d | int64 | 16 | 8 |
| e | byte | 24 | 1 |
| 字节对齐 | 无 | 25 | 7 |
| 总占用大小 | - | - | 32 |
- 第一个成员 a
- 类型为 bool
- 对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 第二个成员 b
- 类型为 int32
- 大小/对齐值为 4 字节
- 根据规则 1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此 2-4 位为 Padding。而当前数值从第 5 位开始填充,到第 8 位。如下:axxx|bbbb
- 第三个成员 c
- 类型为 int8
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 8。不需要额外对齐,填充 1 个字节到第 9 位。如下:axxx|bbbb|c…
- 第四个成员 d
- 类型为 int64
- 大小/对齐值为 8 字节
- 根据规则 1,其偏移量必须为 8 的整数倍。确定偏移量为 16,因此 9-16 位为 Padding。而当前数值从第 17 位开始写入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd
- 第五个成员 e
- 类型为 byte
- 大小/对齐值为 1 字节
- 根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 24。不需要额外对齐,填充 1 个字节到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e…
整体对齐:
在每个成员变量进行对齐后,根据规则 2,整个结构体本身也要进行字节对齐,因为可发现它可能并不是 2^n,不是偶数倍。显然不符合对齐的规则
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐
结果:
Part1 内存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
其中xxx表示为 “内存空洞”。
内存空洞可能会存在一些随机数据,可能会对用unsafe包直接操作内存的处理产生影响
推论字段顺序可改变结构体大小
1 | type Part1 struct { |
分析过程和上面完全一样。
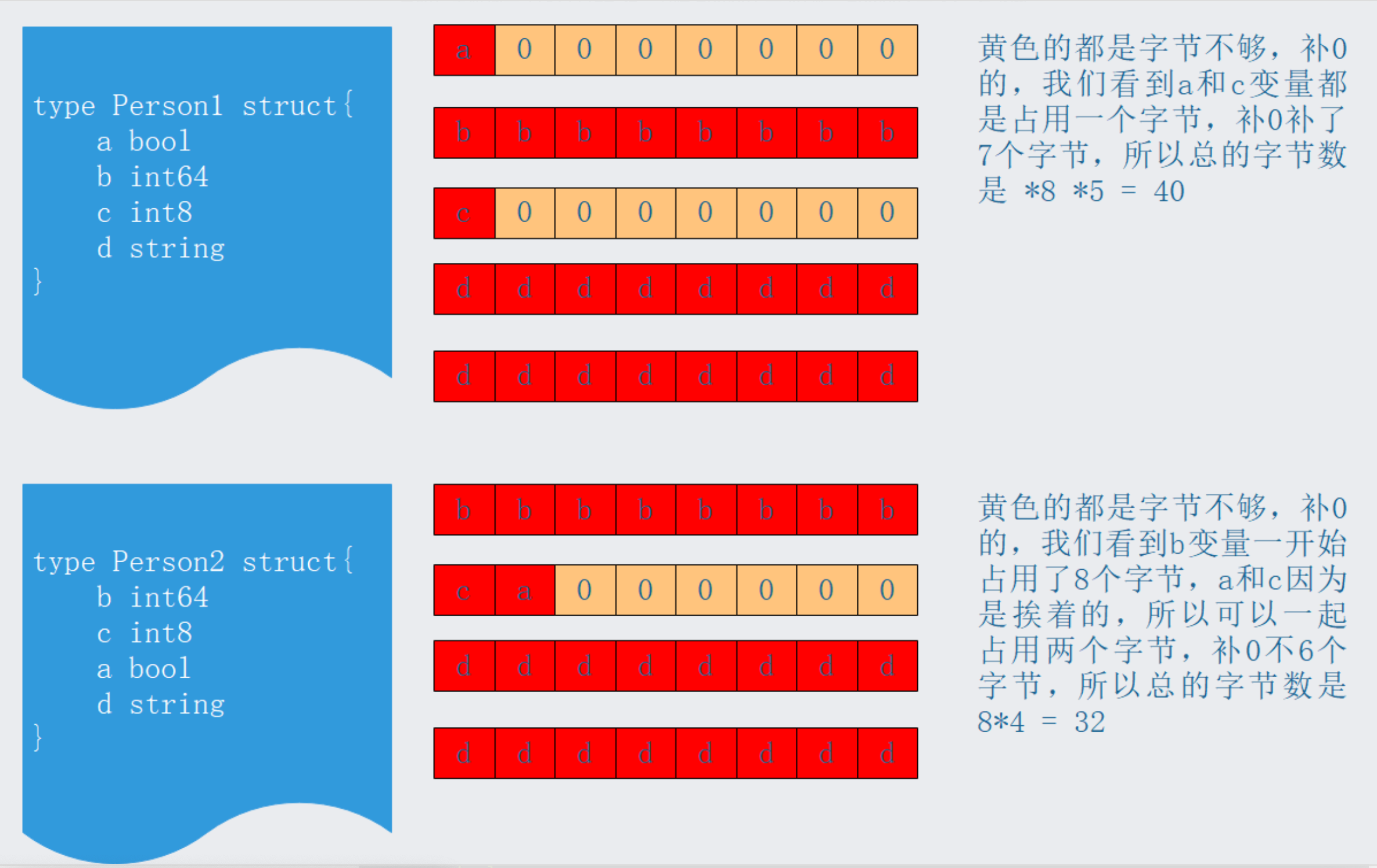
根据上图,我们就明白了,在结构体编写中存在内存对齐的概念,而且我们应该小心,尽可能的避免因内存对齐导致结构体大小增大,在书写过程中应该让小字节的变量挨着。
示例:修改struct成员
1 | package main |
- 要修改struct字段的值,需要提前知道结构体V的成员布局,然后根据字段计算偏移量,以及考虑对齐值,最后通过指针运算得到成员指针,利用指针达到修改成员值得目的。
- 由于结构体的成员在内存中的分配是一段连续的内存,因此结构体中第一个成员的地址就是这个结构体的地址,我们也可以认为是相对于这个结构体偏移了0。相同的,这个结构体中的任一成员都可以相对于这个结构体的偏移来计算出它在内存中的绝对地址。
具体来讲解下main方法的实现:
1 | var v *V = &V{199, 299} |
通过&来分配一段内存(并按类型初始化),返回一个指针。所以v就是类型为V的一个指针。和new函数的作用类似。
1 | var i *int32 = (*int32)(unsafe.Pointer(v)) |
将指针v转成通用指针,再转成int32指针类型。这里就看到了unsafe.Pointer的作用了,您不能直接将v转成int32类型的指针,那样将会panic,但是unsafe.Pointer是可以转为任何指针。
刚才说了v的地址其实就是它的第一个成员的地址,所以这个i就很显然指向了v的成员i,通过给i赋值就相当于给v.i赋值了,但是别忘了i只是个指针,要赋值得解引用。
1 | *i = int32(98) |
现在已经成功的改变了v的私有成员i的值。
但是对于v.j来说,怎么来得到它在内存中的地址呢?其实我们可以获取它相对于v的偏移量(unsafe.Sizeof可以为我们做这个事),但上面的代码并没有这样去实现。各位别急,一步步来。
1 | var j *int64 = (*int64)( |
其实我们已经知道v是有两个成员的,包括i和j,并且在定义中,i位于j的前面,而i是int32类型,也就是说i占4个字节。所以j是相对于v偏移了4个字节。您可以用uintptr(4)或uintptr(unsafe.Sizeof(int64(0)))来做这个事。unsafe.Sizeof方法用来得到一个值应该占用多少个字节空间。注意这里跟C的用法不一样,C是直接传入类型,而Go 语言是传入值。
之所以转成uintptr类型是因为需要做指针运算。v的地址加上j相对于v的偏移地址,也就得到了v.j在内存中的绝对地址,然后通过unsafe.Pointer转为指针,别忘了j的类型是int64,所以现在的j就是一个指向v.j的指针,接下来给它赋值:
1 | *j = int64(763) |
另外,我们可以看到两种地址表示上的差异:
1 | 指针地址: 0xc00000c180 |
示例:修改struct成员2
1 | package main |
示例:struct对齐值
1 | package main |
新结构体的长度为size=16,好像跟我们想像的不一致。我们计算一下:b是byte类型,占1个字节;i是int32类型,占4个字节;j是int64类型,占8个字节,1+4+8=13。这是怎么回事呢?
这是因为发生了对齐。在struct中,它的对齐值是它的成员中的最大对齐值。
每个成员类型都有它的对齐值,可以用unsafe.Alignof方法来计算,比如unsafe.Alignof(v.b)就可以得到b的对齐值为1 。但这个对齐值是其值类型的长度或引用的地址长度(32位或者64位),和其在结构体中的size不是简单相加的问题。经过在64位机器上测试,发现地址(uintptr)如下:
1 | unsafe.Pointer(b): %s 824634048640 |
可以初步推断,也经过测试验证,取i值使用uintptr(4*unsafe.Sizeof(byte(0)))是准确的。至于size其实也和对齐值有关,也不是简单相加每个字段的长度。
unsafe.Offsetof 可以在实际中使用,如果改变私有的字段,需要程序员认真考虑后,按照上面的方法仔细确认好对齐值再进行操作。
示例:配合reflect
1 | package main |