bufio — 缓存IO
bufio 包实现了缓存IO。使用这个包可以大幅提高文件读写的效率。
它包装了 io.Reader 和 io.Writer 对象,创建了另外的Reader和Writer对象,它们也实现了 io.Reader 和 io.Writer 接口,不过它们是有缓存的。该包同时为文本I/O提供了一些便利操作。
bufio包原理
- bufio 是通过缓冲来提高效率。
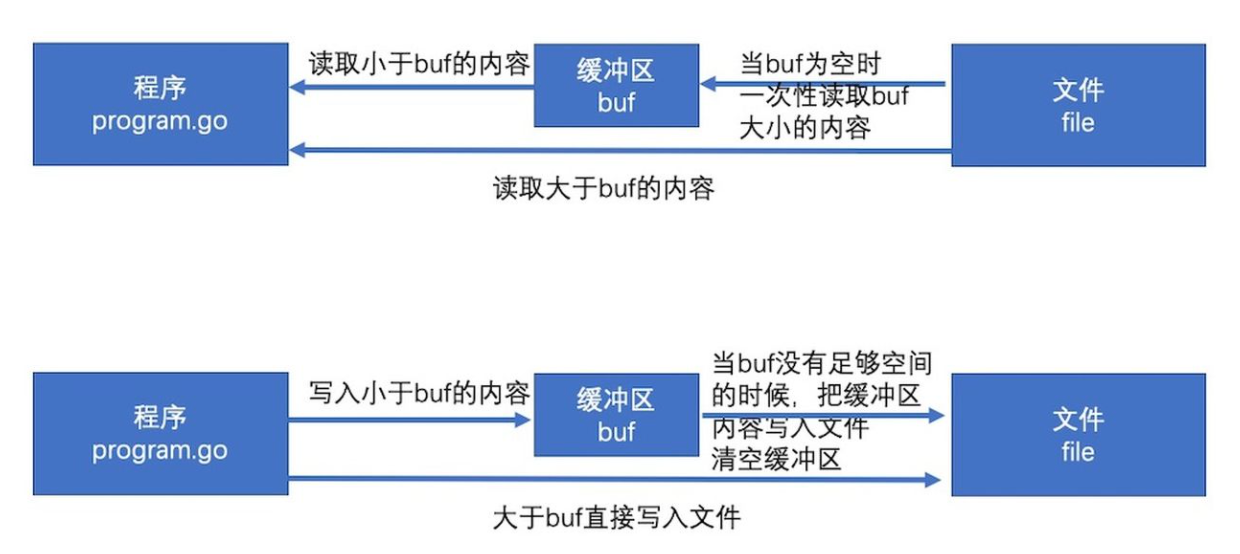
- io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
- 简单的说就是:把文件读取进缓冲(内存),之后再读取的时候就可以避免文件系统的io从而提高速度。同理,在进行写操作时,先把文件写入缓冲(内存),然后由缓冲写入文件系统。
- 看完以上解释有人可能会表示困惑了,直接把
内容->文件和内容->缓冲->文件相比, 缓冲区好像没有起到作用嘛。其实缓冲区的设计是为了存储多次的写入,最后一口气把缓冲区内容写入文件。
Reader 类型和方法
bufio.Reader 结构包装了一个 io.Reader 对象,提供缓存功能,同时实现了 io.Reader 接口。
Reader 结构没有任何导出的字段,结构定义如下:
1 | type Reader struct { |
bufio.Read(p []byte) 相当于读取大小len(p)的内容,思路如下:
- 当缓存区有内容的时,将缓存区内容全部填入p并清空缓存区
- 当缓存区没有内容的时候且len(p)>len(buf),即要读取的内容比缓存区还要大,直接去文件读取即可
- 当缓存区没有内容的时候且len(p)<len(buf),即要读取的内容比缓存区小,缓存区从文件读取内容充满缓存区,并将p填满(此时缓存区有剩余内容)
- 以后再次读取时缓存区有内容,将缓存区内容全部填入p并清空缓存区(此时和情况1一样)
1 | // Read reads data into p. |
reader内部通过维护一个r, w 即读入和写入的位置索引来判断是否缓存区内容被全部读出。
bufio.Reader 实现接口
1 | // NewReaderSize 将 rd 封装成一个带缓存的 bufio.Reader 对象, |
实例化
bufio 包提供了两个实例化 bufio.Reader 对象的函数:NewReader 和 NewReaderSize。其中,NewReader 函数是调用 NewReaderSize 函数实现的:
1 | func NewReader(rd io.Reader) *Reader { |
我们看一下NewReaderSize的源码:
1 | func NewReaderSize(rd io.Reader, size int) *Reader { |
ReadSlice、ReadBytes、ReadString 和 ReadLine 方法
之所以将这几个方法放在一起,是因为他们有着类似的行为。事实上,后三个方法最终都是调用ReadSlice来实现的。所以,我们先来看看ReadSlice方法。(感觉这一段直接看源码较好)
ReadSlice方法签名如下:
1 | func (b *Reader) ReadSlice(delim byte) (line []byte, err error) |
ReadSlice 从输入中读取,直到遇到第一个界定符(delim)为止,返回一个指向缓存中字节的 slice,在下次调用读操作(read)时,这些字节会无效。举例说明:
1 | reader := bufio.NewReader(strings.NewReader("http://studygolang.com. \nIt is the home of gophers")) |
输出:
1 | the line:http://studygolang.com. |
从结果可以看出,第一次ReadSlice的结果(line),在第二次调用读操作后,内容发生了变化。也就是说,ReadSlice 返回的 []byte 是指向 Reader 中的 buffer ,而不是 copy 一份返回。正因为ReadSlice 返回的数据会被下次的 I/O 操作重写,因此许多的客户端会选择使用 ReadBytes 或者 ReadString 来代替。读者可以将上面代码中的 ReadSlice 改为 ReadBytes 或 ReadString ,看看结果有什么不同。
注意,这里的界定符可以是任意的字符,可以将上面代码中的’\n’改为’m’试试。同时,返回的结果是包含界定符本身的,上例中,输出结果有一空行就是’\n’本身(line携带一个’\n’,printf又追加了一个’\n’)。
如果 ReadSlice 在找到界定符之前遇到了 error ,它就会返回缓存中所有的数据和错误本身(经常是 io.EOF)。如果在找到界定符之前缓存已经满了,ReadSlice 会返回 bufio.ErrBufferFull 错误。当且仅当返回的结果(line)没有以界定符结束的时候,ReadSlice 返回err != nil,也就是说,如果ReadSlice 返回的结果 line 不是以界定符 delim 结尾,那么返回的 er r也一定不等于 nil(可能是bufio.ErrBufferFull或io.EOF)。 例子代码:
1 | reader := bufio.NewReaderSize(strings.NewReader("http://studygolang.com"),16) |
输出:
1 | line:http://studygola error:bufio: buffer full |
ReadBytes方法签名如下:
1 | func (b *Reader) ReadBytes(delim byte) (line []byte, err error) |
该方法的参数和返回值类型与 ReadSlice 都一样。 ReadBytes 从输入中读取直到遇到界定符(delim)为止,返回的 slice 包含了从当前到界定符的内容 (包括界定符)。如果 ReadBytes 在遇到界定符之前就捕获到一个错误,它会返回遇到错误之前已经读取的数据,和这个捕获到的错误(经常是 io.EOF)。跟 ReadSlice 一样,如果 ReadBytes 返回的结果 line 不是以界定符 delim 结尾,那么返回的 err 也一定不等于 nil(可能是bufio.ErrBufferFull 或 io.EOF)。
从这个说明可以看出,ReadBytes和ReadSlice功能和用法都很像,那他们有什么不同呢?
在讲解ReadSlice时说到,它返回的 []byte 是指向 Reader 中的 buffer,而不是 copy 一份返回,也正因为如此,通常我们会使用 ReadBytes 或 ReadString。很显然,ReadBytes 返回的 []byte 不会是指向 Reader 中的 buffer,通过查看源码可以证实这一点。
还是上面的例子,我们将 ReadSlice 改为 ReadBytes:
1 | reader := bufio.NewReader(strings.NewReader("http://studygolang.com. \nIt is the home of gophers")) |
输出:
1 | the line:http://studygolang.com. |
ReadString方法
看一下该方法的源码:
1 | func (b *Reader) ReadString(delim byte) (line string, err error) { |
它调用了 ReadBytes 方法,并将结果的 []byte 转为 string 类型。
ReadLine方法签名如下
1 | func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) |
ReadLine 是一个底层的原始行读取命令。许多调用者或许会使用 ReadBytes(‘\n’) 或者 ReadString(‘\n’) 来代替这个方法。
ReadLine 尝试返回单独的行,不包括行尾的换行符。
- 如果一行大于缓存,isPrefix 会被设置为 true,同时返回该行的开始部分(等于缓存大小的部分)。该行剩余的部分就会在下次调用的时候返回。
- 当下次调用返回该行剩余部分时,isPrefix 将会是 false 。跟 ReadSlice 一样,返回的 line 只是 buffer 的引用,在下次执行IO操作时,line 会无效。可以将 ReadSlice 中的例子该为 ReadLine 试试。
注意,返回值中,要么 line 不是 nil,要么 err 非 nil,两者不会同时非 nil。
ReadLine 返回的文本不会包含行结尾(”\r\n”或者”\n”)。如果输入中没有行尾标识符,不会返回任何指示或者错误。
从上面的讲解中,我们知道,读取一行,通常会选择 ReadBytes 或 ReadString。不过,正常人的思维,应该用 ReadLine,只是不明白为啥 ReadLine 的实现不是通过 ReadBytes,然后清除掉行尾的\n(或\r\n),它现在的实现,用不好会出现意想不到的问题,比如丢数据。个人建议可以这么实现读取一行:
1 | line, err := reader.ReadBytes('\n') |
这样既读取了一行,也去掉了行尾结束符(当然,如果你希望留下行尾结束符,只用ReadBytes即可)。
Peek 方法
从方法的名称可以猜到,该方法只是“窥探”一下 Reader 中没有读取的 n 个字节。好比栈数据结构中的取栈顶元素,但不出栈。
方法的签名如下:
1 | func (b *Reader) Peek(n int) ([]byte, error) |
同上面介绍的 ReadSlice一样,返回的 []byte 只是 buffer 中的引用,在下次IO操作后会无效,可见该方法(以及ReadSlice这样的,返回buffer引用的方法)对多 goroutine 是不安全的,也就是在多并发环境下,不能依赖其结果。
我们通过例子来证明一下:
1 | package main |
输出:
1 | http://studygo |
输出结果和预期的一致。然而,这是由于目前的 goroutine 调度方式导致的结果。如果我们将例子中注释掉的 time.Sleep(1) 取消注释(这样调度其他 goroutine 执行),再次运行,得到的结果为:
1 | http://studygo |
另外,Reader 的 Peek 方法如果返回的 []byte 长度小于 n,这时返回的 err != nil ,用于解释为啥会小于 n。如果 n 大于 reader 的 buffer 长度,err 会是 ErrBufferFull。
其他方法
Reader 的其他方法都是实现了 io 包中的接口,它们的使用方法在io包中都有介绍,在此不赘述。
这些方法包括:
1 | func (b *Reader) Read(p []byte) (n int, err error) |
你应该知道它们都是哪个接口的方法吧。
示例
1 | package main |
Scanner 类型和方法
对于简单的读取一行,在 Reader 类型中,感觉没有让人特别满意的方法。于是,Go1.1增加了一个类型:Scanner。官方关于Go1.1增加该类型的说明如下:
在 bufio 包中有多种方式获取文本输入,ReadBytes、ReadString 和独特的 ReadLine,对于简单的目的这些都有些过于复杂了。在 Go 1.1 中,添加了一个新类型,Scanner,以便更容易的处理如按行读取输入序列或空格分隔单词等,这类简单的任务。
它终结了如输入一个很长的有问题的行这样的输入错误,并且提供了简单的默认行为:基于行的输入,每行都剔除分隔标识。这里的代码展示一次输入一行:
2
3
4
5
6
7
for scanner.Scan() {
fmt.Println(scanner.Text()) // Println will add back the final '\n'
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading standard input:", err)
}输入的行为可以通过一个函数控制,来控制输入的每个部分(参阅 SplitFunc 的文档),但是对于复杂的问题或持续传递错误的,可能还是需要原有接口。
Scanner 类型和 Reader 类型一样,没有任何导出的字段,同时它也包装了一个 io.Reader 对象,但它没有实现 io.Reader 接口。
Scanner 的结构定义如下:
1 | type Scanner struct { |
这里 split、maxTokenSize 和 token 需要讲解一下。
然而,在讲解之前,需要先讲解 split 字段的类型 SplitFunc。
SplitFunc 类型和实例
1 | type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error) |
SplitFunc 定义了 用于对输入进行分词的 split 函数的签名。参数 data 是还未处理的数据,atEOF 标识 Reader 是否还有更多数据(是否到了EOF)。返回值 advance 表示从输入中读取的字节数,token 表示下一个结果数据,err 则代表可能的错误。
举例说明一下这里的 token 代表的意思:
- 有数据 “studygolang\tpolaris\tgolangchina”,通过”\t”进行分词,那么会得到三个token,它们的内容分别是:studygolang、polaris 和 golangchina。
- 而 SplitFunc 的功能是:进行分词,并返回未处理的数据中第一个 token。对于这个数据,就是返回 studygolang。
如果 data 中没有一个完整的 token,例如,在扫描行(scanning lines)时没有换行符,SplitFunc 会返回(0,nil,nil)通知 Scanner 读取更多数据到 slice 中,然后在这个更大的 slice 中同样的读取点处,从输入中重试读取。如下面要讲解的 split 函数的源码中有这样的代码:
1 | // Request more data. |
如果 err != nil,扫描停止,同时该错误会返回。
如果参数 data 为空的 slice,除非 atEOF 为 true,否则该函数永远不会被调用。如果 atEOF 为 true,这时 data 可以非空,这时的数据是没有处理的。
当返回的值分别是
0, nil, nil的时候,扫描器会尝试读取更多的数据,如果缓冲区已满,那么缓冲区会在任何读取操作前自动扩容为原来的两倍
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import (
"bufio"
"fmt"
"strings"
)
func main() {
input := "abcdefghijkl"
scanner := bufio.NewScanner(strings.NewReader(input))
split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {
fmt.Printf("%t\t%d\t%s\n", atEOF, len(data), data)
return 0, nil, nil
}
scanner.Split(split)
buf := make([]byte, 2)
scanner.Buffer(buf, bufio.MaxScanTokenSize)
for scanner.Scan() {
fmt.Printf("%s\n", scanner.Text())
}
}输出结果:
2
3
4
5
false 4 abcd
false 8 abcdefgh
false 12 abcdefghijkl
true 12 abcdefghijkl上例中的
split函数可以说是简单且极其贪婪的 – 总是请求更多的数据,Scanner尝试读取更多的数据的同时会保证缓冲区拥有足够的空间来存放这些数据。在上面的例子中,我们将缓冲区的大小设置为 2。
2
scanner.Buffer(buf, bufio.MaxScanTokenSize)在
split函数第一次被调用后,scanner会倍增缓冲区的容量,读取更多的数据,然后再次调用split函数。在第二次调用之后增长倍数仍然保持不变,通过观察输出结果可以发现第一次调用split得到大小为 2 的切片,然后是 4、8,最后到 12,因为没有更多的数据了。
atEOF 这个参数,通过这个参数我们能够在 split 函数中判断是否还有数据可供使用,它能够在达到数据末尾 (EOF) 或者是读取出错的时候触发为真,一旦任何上述情况发生, scanner 将拒绝读取任何东西,
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import (
"bufio"
"errors"
"fmt"
"strings"
)
func main() {
input := "abcdefghijkl"
scanner := bufio.NewScanner(strings.NewReader(input))
split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {
fmt.Printf("%t\t%d\t%s\n", atEOF, len(data), data)
if atEOF {
return 0, nil, errors.New("bad luck")
}
return 0, nil, nil
}
scanner.Split(split)
buf := make([]byte, 12)
scanner.Buffer(buf, bufio.MaxScanTokenSize)
for scanner.Scan() {
fmt.Printf("%s\n", scanner.Text())
}
if scanner.Err() != nil {
fmt.Printf("error: %s\n", scanner.Err())
}
}输出结果:
2
3
true 12 abcdefghijkl
error: bad luck
bufio 包定义的 split 函数,即 SplitFunc 的实例
在 bufio 包中预定义了一些 split 函数,也就是说,在 Scanner 结构中的 split 字段,可以通过这些预定义的 split 赋值,同时 Scanner 类型的 Split 方法也可以接收这些预定义函数作为参数。所以,我们可以说,这些预定义 split 函数都是 SplitFunc 类型的实例。这些函数包括:ScanBytes、ScanRunes、ScanWords 和 ScanLines。(由于都是 SplitFunc 的实例,自然这些函数的签名都和 SplitFunc 一样)
- ScanBytes 返回单个字节作为一个 token。
- ScanRunes 返回单个 UTF-8 编码的 rune 作为一个 token。返回的 rune 序列(token)和 range string类型 返回的序列是等价的,也就是说,对于无效的 UTF-8 编码会解释为 U+FFFD = “\xef\xbf\xbd”。
- ScanWords 返回通过“空格”分词的单词。如:study golang,调用会返回study。注意,这里的“空格”是
unicode.IsSpace(),即包括:’\t’, ‘\n’, ‘\v’, ‘\f’, ‘\r’, ‘ ‘, U+0085 (NEL), U+00A0 (NBSP)。 - ScanLines 返回一行文本,不包括行尾的换行符。这里的换行包括了Windows下的”\r\n”和Unix下的”\n”。
一般地,我们不会单独使用这些函数,而是提供给 Scanner 实例使用。
现在我们回到 Scanner 的 split、maxTokenSize 和 token 字段上来。
- split 字段(SplitFunc 类型实例),很显然,代表了当前 Scanner 使用的分词策略,可以使用上面介绍的预定义 SplitFunc 实例赋值,也可以自定义 SplitFunc 实例。(当然,要给 split 字段赋值,必须调用 Scanner 的 Split 方法)
- maxTokenSize 字段 表示通过 split 分词后的一个 token 允许的最大长度。在该包中定义了一个常量 MaxScanTokenSize = 64 * 1024,这是允许的最大 token 长度(64k)。
- token 字段 上文已经解释了这个是什么意思。
Scanner 的实例化
Scanner 没有导出任何字段,而它需要有外部的 io.Reader 对象,因此,我们不能直接实例化 Scanner 对象,必须通过 bufio 包提供的实例化函数来实例化。实例化函数签名以及内部实现:
1 | func NewScanner(r io.Reader) *Scanner { |
可见,返回的 Scanner 实例默认的 split 函数是 ScanLines。
Scanner 的方法
Split 方法 前面我们提到过可以通过 Split 方法为 Scanner 实例设置分词行为。由于 Scanner 实例的默认 split 总是 ScanLines,如果我们想要用其他的 split,可以通过 Split 方法做到。
比如,我们想要统计一段英文有多少个单词(不排除重复),我们可以这么做:
1 | const input = "This is The Golang Standard Library.\nWelcome you!" |
我们实例化 Scanner 后,通过调用 scanner.Split(bufio.ScanWords) 来更改 split 函数。注意,我们应该在调用 Scan 方法之前调用 Split 方法。
Scan 方法 该方法好比 iterator 中的 Next 方法,它用于将 Scanner 获取下一个 token,以便 Bytes 和 Text 方法可用。当扫描停止时,它返回false,这时候,要么是到了输入的末尾要么是遇到了一个错误。注意,当 Scan 返回 false 时,通过 Err 方法可以获取第一个遇到的错误(但如果错误是 io.EOF,Err 方法会返回 nil)。
Bytes 和 Text 方法 这两个方法的行为一致,都是返回最近的 token,无非 Bytes 返回的是 []byte,Text 返回的是 string。该方法应该在 Scan 调用后调用,而且,下次调用 Scan 会覆盖这次的 token。比如:
1 | scanner := bufio.NewScanner(strings.NewReader("http://studygolang.com. \nIt is the home of gophers")) |
返回的是:It is the home of gophers 而不是 http://studygolang.com.
Err 方法 前面已经提到,通过 Err 方法可以获取第一个遇到的错误(但如果错误是 io.EOF,Err 方法会返回 nil)。
示例
我们经常会有这样的需求:读取文件中的数据,一次读取一行。在学习了 Reader 类型,我们可以使用它的 ReadBytes 或 ReadString来实现,甚至使用 ReadLine 来实现。然而,在 Go1.1 中,我们可以使用 Scanner 来做这件事,而且更简单好用。
1 | file, err := os.Create("scanner.txt") |
输出结果:
1 | http://studygolang.com. |
Writer 类型和方法
bufio.Writer 结构包装了一个 io.Writer 对象,提供缓存功能,同时实现了 io.Writer 接口。
Writer 结构没有任何导出的字段,结构定义如下:
1 | type Writer struct { |
相比 bufio.Reader, bufio.Writer 结构定义简单很多。
注意:如果在写数据到 Writer 的时候出现了一个错误,不会再允许有数据被写进来了,并且所有随后的写操作都会返回该错误。
bufio.Write(p []byte) 的思路如下
- 判断buf中可用容量是否可以放下 p
- 如果能放下,直接把p拼接到buf后面,即把内容放到缓冲区
- 如果缓冲区的可用容量不足以放下,且此时缓冲区是空的,直接把p写入文件即可
- 如果缓冲区的可用容量不足以放下,且此时缓冲区有内容,则用p把缓冲区填满,把缓冲区所有内容写入文件,并清空缓冲区。判断p的剩余内容大小能否放到缓冲区,如果能放下(此时和步骤1情况一样)则把内容放到缓冲区,如果p的剩余内容依旧大于缓冲区,(注意此时缓冲区是空的,情况和步骤3一样)则把p的剩余内容直接写入文件。
1 | // Write writes the contents of p into the buffer. |
- b.wr 存储的是一个io.writer对象,实现了Write()的接口,所以可以使用b.wr.Write(p) 将p的内容写入文件。
- b.flush() 会将缓存区内容写入文件,当所有写入完成后,因为缓存区会存储内容,所以需要手动flush()到文件。
- b.Available() 为buf可用容量,等于len(buf) - n。
bufio.Writer 实现接口
1 | // NewWriterSize 将 wr 封装成一个带缓存的 bufio.Writer 对象, |
实例化
和 Reader 类型一样,bufio 包提供了两个实例化 bufio.Writer 对象的函数:NewWriter 和 NewWriterSize。其中,NewWriter 函数是调用 NewWriterSize 函数实现的:
1 | func NewWriter(wr io.Writer) *Writer { |
我们看一下 NewWriterSize 的源码:
1 | func NewWriterSize(wr io.Writer, size int) *Writer { |
Available 和 Buffered 方法
Available 方法获取缓存中还未使用的字节数(缓存大小 - 字段 n 的值);Buffered 方法获取写入当前缓存中的字节数(字段 n 的值)
Flush 方法
该方法将缓存中的所有数据写入底层的 io.Writer 对象中。使用 bufio.Writer 时,在所有的 Write 操作完成之后,应该调用 Flush 方法使得缓存都写入 io.Writer 对象中。
其他方法
Writer 类型其他方法是一些实际的写方法:
1 | // 实现了 io.ReaderFrom 接口 |
这些写方法在缓存满了时会调用 Flush 方法。另外,这些写方法源码开始处,有这样的代码:
1 | if b.err != nil { |
也就是说,只要写的过程中遇到了错误,再次调用写操作会直接返回该错误。
示例
1 | package main |
ReadWriter 类型和实例化
ReadWriter 结构存储了 bufio.Reader 和 bufio.Writer 类型的指针(内嵌),它实现了 io.ReadWriter 结构。
1 | type ReadWriter struct { |
ReadWriter 的实例化可以跟普通结构类型一样,也可以通过调用 bufio.NewReadWriter 函数来实现:只是简单的实例化 ReadWriter
1 | func NewReadWriter(r *Reader, w *Writer) *ReadWriter { |