goroutine Go协程的特点
主线程是一个物理线程 ,直接作用在cpu上的。是重量级的,非常耗费cpu资源。
协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func testGoroutine () for i := 1 ; i < 10 ; i++ { fmt.Println("this is goroutine" , i) time.Sleep(time.Second) } } func main () go testGoroutine() for i := 1 ; i < 10 ; i++ { fmt.Println("this is main string" , i) time.Sleep(time.Second) } }
goroutine调用说明
一个线程就是一个栈加堆资源。操作系统一会让cpu跑线程A,一会让cpu跑线程B,靠A和B的栈来保存A和B的执行状态。 每个线程都有他自己的栈。
但是线程又老贵了,花不起那个钱,所以go发明了 goroutine。大致就是说给每个goroutine弄一个分配在资源堆里面的栈来模拟线程栈。
比方说有3个goroutine,A,B,C,就在资源堆上弄三 个栈出来。然后Go让一个单线程的scheduler开始跑他们仨。相当于{ A(); B(); C() },连续的,串行的跑。
和操作系统不太一样的是,操作系统可以随时随地把你线程停掉,切换到另一个线程。这个单线程的 scheduler没那个能力啊,他跑着A的时候控制权是在A的代码里面的. A自己不退出谁也没办法。
所以A跑一小段后需要主动说,老大(scheduler),我不想跑了,帮我把我的所有的状态保存在我自己的栈上面,让我歇一会吧。这时候你可以看做A返回了。
A返回了B就可以跑了,然后B跑一小段说,跑够了,保存状态,返回,然后C再跑。C跑一段也返回了。
这样跑完{ A(); B(); C() }之后,我们发现,好像他们都只跑了一小段啊。所以外面要包一个循环,大致是
1 2 3 4 5 6 goroutine_list = [A,B,C] while (goroutine_list): for goroutine in goroutine_list: r = goroutine() if r.isFinished(): goroutine_list.remove(r)
比如跑完一圈A,B,C之后谁也没执行完,那么就在回到A执行一次。由于我们把A的栈保存在了资源堆里,这时候可以把A的栈复制粘贴回系统栈里,然后再调用A,这时候由于A是跑到一半自己说跳出来的,所以会从刚刚跳出来的地方继续执行。
所以你看出来了,关键就在于每个 goroutine跑一跑就要让一让。一般支持这种玩意(叫做 coroutine)的语言都是让每个coroutine自己说,我跑够了,换人。goroutine比较文艺的地方就在于,他可以来帮你判断啥时候“跑够了”。
比如说python , 就需要使用await关键字表明, 该函数跑够了 , 该暂时让出资源了。
1 2 3 async def do_some_work (x ): await asyncio.sleep(x) return 'Done after {}s' .format (x)
go 是如何做到这一点的呢? go把每一个能异步并发的操作,包成一个同步的“方法” , 但是这个方法里其实会调用“异步并发”的操作.
比如string s = go.file.readFile("/root")其实go偷偷在里面执行了操作系统的API asyncReadFIle。
1 2 3 4 5 6 handler h = OS.asyncReadFile("/root" ) while (!h.finishedAsyncReadFile()): go.scheduler.保存现状() yield go.scheduler.跑够了_换人() string s = h.getResultFromAsyncRead()
然后scheduler就换下一个goroutine跑了。等下次再跑回 刚才那个goroutine的时候,他就看看,说那个asyncReadFile到底执行完没有啊,如果没有,就再换个人吧。如果执行完了,那就把结果拿出来,该干嘛干嘛。所以你看似写了个同步的操作,已经被go替换成异步操作了。
还有另外一种情况是,某个goroutine执行了某个不能异步调用 的 , 会阻塞的系统调用,这个时候goroutine就没法玩那种异步调用的把戏了。他会把你挪到一个真正的线程里让你在那个线程里等着,他接茬去跑别的goroutine。
比如A这么定义
1 2 3 4 def A : print ("do something" ) go.os.调用一些真正复杂的会阻塞的函数() print ("do something 2" )
go会帮你转成
1 2 3 4 5 6 7 8 9 10 def 真实的A : print ("do something" ) Thread t = new Thread( () => { go.os.调用一些真正复杂的会阻塞的函数() }) t.start() while !t.finished(): go.scheduler.保存现状 go.scheduler.跑够了_换人 print ("finished" )
所以真实的A还是不会blocking,还是可以跟别的小伙伴(goroutine)愉快地玩耍(轮流往复的被执行),但他其实已经占了一个真实的系统线程了。
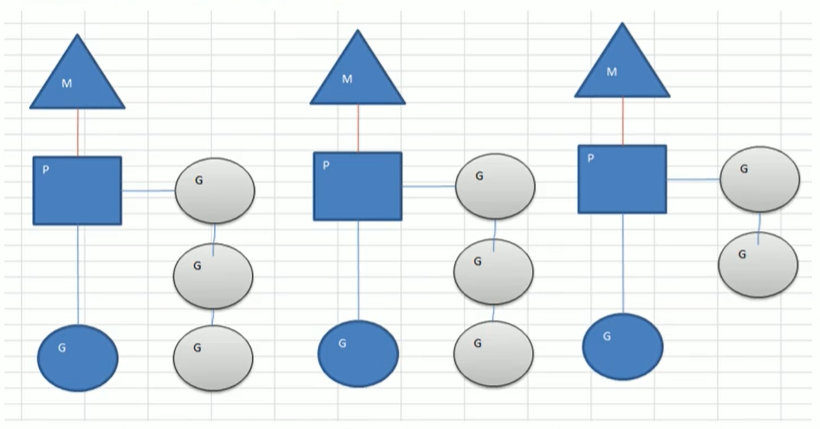
MPG模型
M:操作系统的主线程(是物理线程)
P:代表了M所需的上下文环境,用于协调M和G的执行 ,内核线程只有拿到了P才对 goroutine继续调度执行,一般都是通过限定P的个数来控制 galang的并发度
G:协程
当前程序有三个M,如果三个M都在一个cpu运行,就是并发,如果在不同的cpu运行就是并行
M1 , M2,M3正在执行一个G ,M1的协程队列有3个,M2的协程队列有3个,M3协程队列有2个图中灰色的那些 goroutine并没有运行,而是出于read的就绪态,正在等待被调度。P维护着这个队列(称之为 runqueue)
从上图可以看到:Go的协程是轻量级的线程,是逻辑态 的,Go可以容易的起上万个协程。其它程序c/java的多线程,往往是内核态的,比较重量级。几千个线程可能耗光CPU。
设置golang程序的CPU数量 1 2 3 4 5 6 7 8 import "runtime" func main () num := runtime.NumCPU() runtime.GOMAXPROCS(num) }
goroutine可能出现的两个问题 问题1 : 主线程先于goroutine结束 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var m = make (map [int ]int , 10 )func Factorial (n int ) res := 1 for i := 1 ; i <= n; i++ { res *= i } m[n] = res } func main () for i := 1 ; i <= 10 ; i++ { go Factorial(i) } for i, v := range m { fmt.Printf("map[%d]=%d\n" , i, v) } }
输出不确定 , 有时输出如下 , 有时没有输出
1 2 3 4 5 6 7 8 9 10 map[5]=120 map[7]=5040 map[10]=3628800 map[1]=1 map[3]=6 map[4]=24 map[9]=362880 map[2]=2 map[6]=720 map[8]=40320
原因很简单 : 有可能主线程先于协程结束 , 有可能主线程慢于协程结束
问题2 : goroutine资源争抢 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import ( "fmt" "time" ) var m = make (map [int ]int , 10 )func Factorial (n int ) res := 1 for i := 1 ; i <= n; i++ { res *= i } m[n] = res } func main () for i := 1 ; i <= 200 ; i++ { go Factorial(i) } time.Sleep(time.Second*5 ) for i, v := range m { fmt.Printf("map[%d]=%d\n" , i, v) } }
上面代码 把问题1的代码的10次循环改成200 , 并添加time.Sleep , 保证了主线程慢于协程结束
但是依旧会报错 :
map由多协程同时读和写就会出现fatal error:concurrent map read and map write的错误
多个协程同时写也会出现fatal error: concurrent map writes的错误
原因 :
因为map为引用类型,所以即使函数传值调用,参数副本依然指向映射m, 所以多个goroutine并发写同一个映射m, 对于共享变量,资源,并发读写会产生竞争的, 故共享资源遭到破坏
我们使用go build -race bbb.go , bbb.exe 查看资源竞争情况 , 发现有2个数据发生争抢
1 2 3 4 5 6 7 ... map[19]=121645100408832000 map[80]=0 map[87]=0 map[185]=0 map[197]=0 Found 2 data race(s)
不同goroutine进行通讯 全局变量添加锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import ( "fmt" "sync" "time" ) var m = make (map [int ]int , 10 )var lock sync.Mutexfunc Factorial (n int ) res := 1 for i := 1 ; i <= n; i++ { res *= i } lock.Lock() m[n] = res lock.Unlock() } func main () for i := 1 ; i <= 200 ; i++ { go Factorial(i) } time.Sleep(time.Second * 5 ) lock.Lock() for i, v := range m { fmt.Printf("map[%d]=%d\n" , i, v) } lock.Unlock() }
读取为什么需要加互斥锁?
按理说5秒后协程都应该执行完,后面就不应该出现资源竞争的问题了,
但是在实际运行中,还是可能在读取的时候出现竞争问题(运行时增加-race参数确实会发现有资源竞争问题),
因为我们程序从设计上可以知道5秒就执行完所有协程,但是主线程并不知道,因此底层可能仍然岀现资源争夺,因此加入互斥锁即可解决问题
channel
本质是队列
channel 是有类型的 , string类型就需要放到string类型的channel
当我们给channel写入数据时 , 不能超出channel的容量
在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告deadlock
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func main () var intChan chan int intChan = make (chan int , 3 ) num := 10 intChan <- num intChan <- 20 fmt.Println(len (intChan), cap (intChan)) num2 := <-intChan fmt.Println(num2) fmt.Println(len (intChan), cap (intChan)) mapChan := make (chan map [string ]int , 4 ) mapChan <- map [string ]int {"heyingliang" : 21 } fmt.Println(<-mapChan) }
使用空接口作为chan的时候 , 在取出后注意需要进行类型断言
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type Student struct { Name string Age int } func main () allChan := make (chan interface {}, 10 ) allChan <- Student{"heyingliang" , 21 } allChan <- 12 allChan <- "heyingling" allChan <- &Student{"123" , 123 } allChan <- map [string ]int {"heyingliang" : 21 } fmt.Println((<-allChan).(Student).Name) fmt.Println((<-allChan).(int ) + 22 ) fmt.Println((<-allChan).(string ) + "is sb" ) fmt.Println((<-allChan).(*Student).Name) m := (<-allChan).(map [string ]int ) m["czj" ] = 22 fmt.Println(m["czj" ]) }
chan操作
关闭 : 关闭后只允许读取 , 不允许写入
严格来说 , 应该是 : 在最后发送的值被接收后停止该通道。
遍历 : for--range
不能使用for-index,val 原因 : chan取值是弹出操作 , 所以每次取值之后,chan的长度会-1 . 这样的话100个数据最后只能拿到50个数据
这也说明了为什么遍历是for val := range chan ,而不是for idx ,val :=range chan .
因为chan本身就是队列 , 没有下标
在遍历时,如果channe没有关闭,则会出现 deadlock的错误
为什么会出现deadlock的错误?
因为 : 在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告deadlock
当chan的最后一个值被取出后 , 再取就报错
在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退岀遍历
检查Channel是否已经被关闭了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func main () c := make (chan int , 4 ) c <- 1 c <- 2 c <- 3 c <- 4 close (c) val, ok := <-c fmt.Println(val, ok) for v := range c { fmt.Println(v) } }
chan使用案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 var intChan = make (chan int , 10 )var exitChan = make (chan bool , 1 )func WriteData () for i := 1 ; i <= 50 ; i++ { fmt.Println("write" , i) intChan <- i } close (intChan) } func ReadData () for { v, ok := <-intChan if !ok { break } fmt.Println("read" , v) } exitChan <- true close (exitChan) } func main () go WriteData() go ReadData() for { _, ok := <-exitChan if !ok { break } } }
上面的intChan长度只有10 , 但是写入了50个元素 , 结果没有报错 , 原因 : 管道的阻塞机制
如果编译器发现管道只有写,而没有读,则该管道会发生阻塞 , 报错。
写管道和读管道的频率不一致,一样能运行通过。
chan使用案例2 求出1-20000中的质数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 var inputChan = make (chan int , 1000 )var outputChan = make (chan int , 2000 )var exitChan = make (chan bool , 4 )func inputData (num int ) for i := 2 ; i <= num; i++ { inputChan <- i } close (inputChan) } func oddNum (num int ) for { isOdd := true val, ok := <-inputChan if !ok { exitChan <- true fmt.Println(num, "is stopping" ) break } for i := 2 ; i <= val/2 ; i++ { if val%i == 0 { isOdd = false break } } if isOdd { outputChan <- val } } } func main () go inputData(8000 ) go oddNum(1 ) go oddNum(2 ) go oddNum(3 ) go oddNum(4 ) go func () for { if len (exitChan) == 4 { close (outputChan) close (exitChan) break } } }() for val := range outputChan { fmt.Println(val) } }
只读只写管道 1 2 3 4 5 6 7 8 9 var chan1 = make (chan int , 20 )var chan2 = make (<-chan int , 3 )var chan3 = make (chan <- int , 4 )
用法 :
将函数参数的chan改成只写或只读 , 防止误操作
1 2 3 4 5 6 7 func writeChan (intchan chan <- int ) intchan <- 1 } func readChan (intchan <-chan int ) fmt.Println(<-intchan) }
select
select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句 。
每个 case 必须是一个通信操作,要么是发送要么是接收。
select 随机执行一个可运行的 case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。
(如果有多个 case 都可以运行,Select 会随机公平地选出一个执行。其他不会执行。)
一个默认的子句应该总是可运行的。
如果有 default 子句,则执行该语句。
如果没有 default 子句,select 将阻塞,直到某个通信可以运行;Go 不会重新对 channel 或值进行求值。
所以沒有 default 的 select 就會遇到 blocking,假設沒有送 value 進去 Channel 就會造成 panic。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 func main () var intChan = make (chan int , 20 ) var stringChan = make (chan string , 20 ) for i := 0 ; i <= 9 ; i++ { intChan <- i } for i := 0 ; i <= 9 ; i++ { stringChan <- "hyl" + fmt.Sprintf("%s" , i) } for { select { case v := <-intChan: fmt.Printf("intChan %d\n" , v) time.Sleep(time.Second) case v := <-stringChan: fmt.Printf("stringChan %s\n" , v) time.Sleep(time.Second) default : fmt.Printf("默认\n" ) return } } }
反射 python中的反射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def add (num_arr ): res = 0 for val in num_arr: res += val return res def sub (num1,num2 ): return num1 - num2 def bridge (func,*args ): return func(*args) print (bridge(add,[1 ,2 ,3 ,4 ,5 ])) print (bridge(sub,50 ,10 ))
反射可以在运行时 动态获取变量的各种信息,比如变量的类型(type),类别(kind)
如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)
通过反射,可以修改变量的值,可以调用关联的方法
使用反射,需要import("reflect")
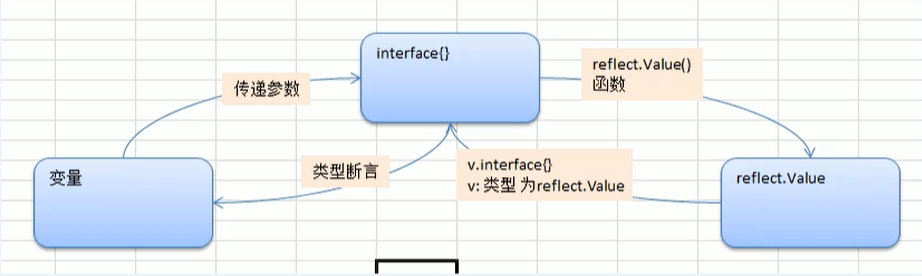
reflect包实现了运行时反射,允许程序操作任意类型的对象,典型用法是用静态类型interface{}保存一个值,
reflect.TypeOf(变量名) : 获取变量类型 , 返回reflect.Type类型reflect.ValueOf(变量名) : 获取变量的值 , 返回refulect.Value类型 (refulect.Value是一个结构体类型)reflect.Zero(Type类型变量) : 返回该类型零值的Value类型值
reflect.Kind 和 reflect.Type的区别
Type是类型,Kind是类别,
Type和Kind可能是相同的,也可能是不同
比如:var num int = 10 , num的Type是int , Kind也是int
比如:var stu Student stu 的Type是pkg1.Student , Kind是 struct
interface , reflect.Value 和 变量类型互转 1 2 3 4 5 6 7 8 9 10 func bridge (b interface {}) rVal := reflect.ValueOf(b) iVal := rVal.interface () v := iVal.(Student) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func reflectTest (b interface {}) rValue := reflect.ValueOf(b) rType := reflect.TypeOf(b) rKind := rValue.Kind() fmt.Println(rValue, rType, rKind) inf := rValue.Interface() v := inf.(float64 ) fmt.Println(inf, v) } func main () b := 25.5 reflectTest(b) }
在反射函数中修改int值
rVal.Elem():取元素,等效于对指针类型变量做了一个*操作
1 2 3 4 5 6 7 8 9 10 11 12 func reflectTest (b interface {}) rVal := reflect.ValueOf(b) rVal.Elem().SetInt(20 ) } func main () var num int = 100 reflectTest(&num) fmt.Println(num) }
使用反射遍历结构体的字段,调用结构体方法,获取stuct tag值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 type Monster struct { Name string `json:"name"` Age int `json:"monster_age"` Score float32 Sex string } func (m Monster) Print () fmt.Println(m) } func (m Monster) GetSum (n1 ,n2 int ) int return n1 +n2 } func (m Monster) Set (name string ,age int ,socre float32 ,sex string ) m.Name = name m.Age = age m.Score = socre m.Sex = sex } func TestStruct (a interface {}) typ := reflect.TypeOf(a) val := reflect.ValueOf(a) kd := val.Kind() if kd != reflect.Struct{ fmt.Println("expect struct" ) return } num := val.NumField() fmt.Printf("struct has %d fields\n" ,num) for i:=0 ;i<num;i++{ fmt.Printf("Field %d: 值为=%v\n" ,i,val.Field(i)) tagVal := typ.Field(i).Tag.Get("json" ) if tagVal != "" { fmt.Printf("Field %d: tag为=%v\n" ,i,tagVal) } } numOfMethod := val.NumMethod() fmt.Printf("struct has %d methods\n" ,numOfMethod) val.Method(1 ).Call(nil ) var params []reflect.Value params = append (params,reflect.ValueOf(10 )) params = append (params,reflect.ValueOf(40 )) res := val.Method(0 ).Call(params) fmt.Println("res=" ,res[0 ].Int()) } func main () var m Monster = Monster{ Name:"heyingliang" , Age:400 , Score:30.8 , Sex:"男" , } TestStruct(m) }
go的适配器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func add (num1 int , num2 int ) fmt.Println(num1 + num2) } func sub (num1 int , num2 int ) fmt.Println(num1 - num2) } func bridge (call interface {}, args ...interface {}) n := len (args) inValue := make ([]reflect.Value,n) for i:=0 ; i<n; i++{ inValue[i] = reflect.ValueOf(args[i]) } function := reflect.ValueOf(call) function.Call(inValue) } func main () bridge(add, 100 ,200 ) bridge(sub,100 ,200 ) }
自定义错误 1 2 3 4 5 6 7 import "errors" var ( ERROR_USER_NOTEXISTS = errors.New("用户不存在" ) ERROR_USER_EXISTS = errors.New("用户已经存在" ) ERROR_USER_PWD = errors.New("密码不正确" ) )
DAO 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 type UserDao struct { pool *redis.Pool } func NewUserDao (pool *redis.Pool) (userDao *UserDao) UserDao = &UserDao{ pool } return } func (this *UserDao) getUserByID (conn redis.Conn, id int ) (user *User, err error) res, err := redis.String(conn.Do("HGet" ,"users" ,id)) if err != nil { if err == redis.ErrNil { err = ERROR_USER_NOTEXISTS } return } user = &User{} err = json.Umarshal([]byte (res), User) if err != nil { fmt.Println("json.Umarshal err=" , err) return } return } func (this *UserDao) Login (userId int , UserPwd string ) (user *User, err error) conn := this.pool.Get() defer conn.Close() user, err = this.getUserByID(conn, userId) if err != nil { return } if user.UserPwd != userPwd { err = ERROR_USER_PWD return } return }
TCP编程
端口监听到一个请求时 , 其他语言都会创建一个线程/进程/协程来处理该请求 , go就可以使用goroutine来解决
net包包含网络socket开发需要所有的方法和函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import ( "fmt" "net" ) func process (conn net.Conn) defer conn.Close() for { buf := make ([]byte , 1024 ) n,err := conn.Read(buf) if err == io.EOF { fmt.Println("客户端已退出" ) return } fmt.Println(string (buf[:n])) } } func main () listen, err := net.Listen("tcp" ,"0.0.0.0:8888" ) if err != nil { fmt.Println("listen err=" , err) return } defer listen.Close() for { fmt.Println("等待客户端连接" ) conn, err := listen.Accept() if err != nil { fmt.Println("Accept() err=" , err) } else { fmt.Println("Accept() suc con=%v\n" , conn) } go process(conn) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func main () conn, err := net.Dial("tcp" ,"192.168.20.253:8888" ) if err != nil { fmt.Println("client dial err=" , err) return } fmt.Println("conn 成功=" , conn) reader := bufio.NewReader(os.Studin) for { line,err := reader.ReadString('\n' ) if err != nil { fmt.Println("readString err=" , err) return } if line == "exit" { fmt.Println("客户端退出" ) break } n, err := conn.Write([]byte (line)) if err != nil { fmt.Println("conn.Write err=" , err) } fmt.Println("客户端发送了 %d 字节的数据,并退出" , n) } }
Redis 基本操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import ( "fmt" "github.com/garyburd/redigo/redis" ) func main () conn, err := redis.Dial("tcp" ,"127.0.0.1:6379" ) if err != nil { fmt.Println("redis.Dial err=" , err) return } defer conn.Close() _, err := conn.Do("Set" ,"name" ,"heyingliang" ) if err != nil { fmt.Println("set err=" , err) return } fmt.Println("set succ" ) r, err := redis.String(conn.Do("Get" ,"name" )) if err != nil { fmt.Println("get err" , err) return } fmt.Println(r) _,err = conn.Do("HMSet" ,"user" ,"name" ,"heyingliang" ,"age" :21 ) r,err = redis.Strings(conn.Do("HMSet" ,"user" ,"name" ,"age" )) for i,v := range r { fmt.Println(i,v) } }
Redis连接池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import "github.com/garyburd/redigo/redis" var poll *redis.Poolfunc init () pool = &redis.Pool{ MaxIdle: 8 , MaxActive: 0 , IdleTimeout: 100 , Dial: func () (redis.Conn, error) return redis.Dial("tcp" ,"localhost:6379" ) }, } } func main () conn := pool.Get() defer conn.Close() _,err := conn.Do("Set" ,"name" ,"hyl" ) }