__del__的坑
del是删除引用。
对象引用为0的时候会调用__del__。如果在程序结束时,有些对象还存在(引用未到0),那么python解释器一样会自动调用它们的
__del__方法来完成清理工作
1 | class Hero: |
1 | class Hero: |
直接将文件数据读取到缓冲区
file.readinto(buf,size) : 读取size个字节到文件缓冲器中
- 和普通 read() 方法不同的是,==readinto() 填充已存在的缓冲区而不是为新对象重新分配内存再返回它们。==
- 有点像json.load,直接将文件数据读取到操作对象中,不必先读取到内容再到操作对象.因此,你可以使用它来避免大量的内存分配操作。
1 | import os.path |
单例模式
1 | class Person: |
1 | class Person: |
enumerate函数
enumerate一般有两种作用
- 方便迭代idx
- 方便计数
1 | alist = ['a','b','c','d','e','f'] |
树的遍历
- 先序遍历:
在第一次遍历到节点时就执行操作,一般只是想遍历执行操作(或输出结果)可选用先序遍历; - 中序遍历:
对于二分搜索树,中序遍历的操作顺序(或输出结果顺序)是符合从小到大(或从大到小)顺序的,故要遍历输出排序好的结果需要使用中序遍历 - 后序遍历:
后续遍历的特点是执行操作时,肯定已经遍历过该节点的左右子节点,故适用于要进行破坏性操作的情况,比如删除所有节点
一棵表达式树,中序遍历是他的中缀表达式,先序遍历是他的前缀表达式,后序遍历是他的后缀表达式
lambda配合sorted的key参数
正数从小到大,负数从大到小
1 | alist = [-5,8,0,4,9,-4,-20,-2,8,2,-4] |
1 | # 列表嵌套字典的排序,根据年龄和姓名排序 |
1 | # 列表嵌套元组,分别按字母和数字排序 |
- 元组支持大小比较
- 给key传入元组就可以实现主要关键字和次要关键字
Python的内存管理
0. 地址
1. Python变量、对象、引用、存储
python语言是一种解释性的编程语言,它不同于一些传统的编译语言,不是先编译成汇编再编程机器码,而是==在运行的过程中,逐句将指令解释成机器码==,
所以造就了python语言一些特别的地方。例如a=1,其中a是变量,1是对象。这里所谓的变量,它的意义类似一个指针,它本身是没有类型的,只有它指向的那个对象是什么类型,它才是什么类型,一旦把它指到别的地方,它的类型就变了,现在指向的是1,它的类型可以认为是int,假如接下来执行a=2.5,那么变量的类型就变了。甚至当先给a=1,a=a+1时,a的地址也会改变。而这里的1,2.5或者一个list一个dict就是一个被实例化的对象,对象拥有真正的资源与取值,当一个变量指向某个对象,被称为这个对象的产生了一个引用,一个对象可以有多个变量指向它,有多个引用。而一个变量可以随时指向另外的对象。同时一个变量可以指向另外一个变量,那么它们指向的那个对象的引用就增加了一个。
Python有个特别的机制,它会在解释器启动的时候事先分配好一些缓冲区,这些缓冲区部分是固定好取值,例如整数[-5,256]的内存地址是固定的。这块区域称为
小整数缓冲池这里的固定指这一次程序启动之后,这些数字在这个程序中的内存地址就不变了,但是启动新的python程序,两次的内存地址不一样
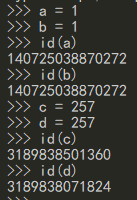
有的缓冲区就可以重复利用。这样的机制就使得不需要python频繁的调用内存malloc和free。
- 针对string类型,它也有自己的缓冲区,也是分为固定缓冲区和可重复缓冲区,固定的是256个ASCII码字符。
- 一个有意思的现象 : 如果string中只有字母和数字,那么对a和b赋同样的值,它们的内存地址都相同。但是如果string对象中有其他字符,那么对两个变量赋相同的string值,它们的内存地址还是不一样的。

dict和list的缓冲区也是事先分配好,大小为80个对象。
因此变量的存储有三个区域
- 事先分配的静态内存
- 事先分配的可重复利用内存
- 需要通过malloc和free来控制的自由内存
2. Python内存管理机制和操作对变量的影响
2.1 内存管理机制
python的内存在底层也是由malloc和free的方式来分配和释放,只是它代替程序员决定什么时候分配什么时候释放,同时也提供接口让用户手动释放,因此它有自己的一套内存管理体系,主要通过两种机制来实现,一个是
引用计数,一个是垃圾回收。前者负责确定当前变量是否需要释放,后者解决前者解决不了的循环引用问题以及提供手动释放的接口引用计数(reference counting) :
针对可以重复利用的内存缓冲区和内存,python使用了一种引用计数的方式来控制和判断某块内存是否已经没有再被使用。即每个对象都有一个计数器count,记住了有多少个变量指向这个对象,当这个对象的引用计数器为0时,假如这个对象在缓冲区内,那么它地址空间不会被释放,而是等待下一次被使用,而非缓冲区的该释放就释放。可以使用sys.getrefcount来获取引用计数:
1
2
3
4
5
6
7
8
9
10
11import sys
a = ['dsz','czj','heyingliang']
# 二的原因是getrefcount本身产生一个临时引用
print(sys.getrefcount(a)) # 2
b = a
print(sys.getrefcount(a)) # 3
a = 1
# 因为1属于静态内存,所以有很多个引用
print(sys.getrefcount(a)) # 120垃圾回收(Garbage Collection) :
垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率
python提供了del方法来删除某个变量,它的作用是让某个对象引用数减少1。
当某个对象引用数变为0时并不是直接将它从内存空间中清除掉,而是采用垃圾回收机制gc模块,当这些引用数为0的变量规模达到一定规模,就自动启动垃圾回收,将那些引用数为0的对象所占的内存空间释放。
这里gc模块采用了分代回收方法,
这一策略的基本假设是,存活时间越久的对象,越不可能在后面的程序中变成垃圾。将对象根据存活的时间分为三“代”,他们对应的是3个链表
- 所有新建的对象都是0代,当0代对象经过一次自动垃圾回收,没有被释放的对象会被归入1代,同理1代归入2代。
- 每次当0代对象中引用数为0的对象超过700个时,启动一次0代对象扫描垃圾回收,经过10次的0代回收,就进行一次0代和1代回收,1代回收次数超过10次,就会进行一次0代、1代和2代回收。
- 这里的几个值是通过查询get_threshold()返回(700,10,10)得到的。
- get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。
- (700,10,10)可以通过gc中的set_threshold()方法重新设置。此外,gc模块还提供了手动回收的函数,即gc.collect()。
垃圾回收还有一个重要功能是,解决循环引用的问题 :
通常发生在某个变量a引用了自己或者变量a与b互相引用。
考虑引用自己的情况,可以从下面的例子中看到,a所指向的内存对象有3个引用,但是实际上只有两个变量,假如把这两个变量都del掉,对象引用个数还是1,没有变成0,这种情况下,如果只有引用计数的机制,那么这块没有用的内存会一直无法释放掉。
1
2
3
4
5
6
7
8
9
10
11
12
13from sys import getrefcount
import gc
a = []
b = a
print(getrefcount(b)) # 3
a.append(a)
print(getrefcount(b)) # 4
del a
print(getrefcount(b)) # 3
del b
unreachable = gc.collect()
print(unreachable) # 1因此python的gc模块利用了
标记-清除法,即认为有效的对象之间能通过有向图连接起来,其中图的节点是对象,而边是引用,下图中obj代表对象,ref代表引用,从一些不能被释放的对象节点出发(称为root object,一些全局引用或者函数栈中的引用,例如下图的obj_1,箭头表示obj_1引用了obj_2)遍历各代引用数不为0的对象。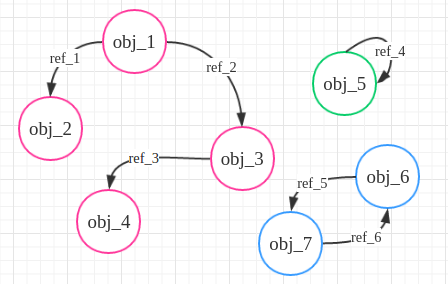
在python源码中,每个变量不仅有一个引用计数,还有一个有效引用计数gc_ref,后者一开始等于前者,但是启动标记清除法开始遍历对象时,从root object出发(初始图中的gc_ref为(1,1,1,1,1,1,1)),当对象i引用了对象j时,将对象j的有效引用个数减去1,这样下图中各个对象有效引用个数变为了(1, 0, 0, 0, 0, 0, 0),接着将所有对象分配到两个表中,一个是reachable对象表,一个是unreachable对象表,root object和在图中能够直接或者间接与它们相连的对象就放入reachable,而不能通过root object访问到且有效引用个数变为0的对象作为放入unreachable,从而通过这种方式来消去循环引用的影响。
步骤 :
- 收集所有容器对象(循环引用只针对于容器对象,其他对象不会产生循环引用),使用双向链表(可以看作一个集合)对这些对象进行引用;之所以使用双向链表是为了方便快速的在容器集合中插入和删除对象.
- 针对每一个容器对象,使用变量gc_refs来记录当前对应的应用个数;
- 对于每一个容器对象, 找到所有其引用的对象, 将被引用对象的
gc_refs值减1. - 执行完步骤2以后所有
gc_refs值还大于0的对象都被非容器对象引用着, 至少存在一个非循环引用. 因此 不能释放这些对象, 将他们放入另一个集合. - 在步骤3中不能被释放的对象, 如果他们引用着某个对象, 被引用的对象也是不能被释放的, 因此将这些 对象也放入另一个集合中.
- 此时还剩下的对象都是无法到达的对象. 现在可以释放这些对象了.
2.2 各种操作对变量地址的改变
当处理赋值、加减乘除时,这些操作实际上导致变量指向的对象发生了改变,已经不是原来的那个对象了,并不是通过这个变量来改变它指向的对象的值。
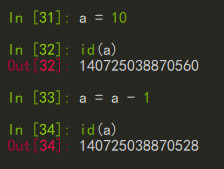
实际使用中,可能需要的是将里面的内容给复制出来到一个新的地址空间,这里可以使用python的copy模块,copy模块分为两种拷贝,一种是浅拷贝,一种是深拷贝。
假设处理一个list对象,浅拷贝调用函数copy.copy(),产生了一块新的内存来存放list中的每个元素引用,也就是说每个元素的跟原来list中元素地址是一样的。
1
2
3
4
5
6
7
8
9
10
11
12import copy
l1 = [1,2,3,4,5]
l2 = copy.copy(l1)
# 父对象id不一致
print(id(l1)) # 2001776215304
print(id(l2)) # 2001776116616
# 子对象id一致
print(id(l1[0])) # 140725038870272
print(id(l2[0])) # 140725038870272
3. 内存池机制
- 在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间会大量地执行malloc和free的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。
- 为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
- 内存池的概念就是预先在内存中申请一定数量的,大小相等的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够了之后再申请新的内存。这样做最显著的优势就是能够减少内存碎片,提升效率。内存池的实现方式有很多,性能和适用范围也不一样。
- 对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
Python中有分为大内存和小内存:(256K为界限分大小内存)
- 大内存使用malloc进行分配
- 小内存使用内存池进行分配
Python的内存池(金字塔)
第3层:
最上层,用户对Python对象的直接操作第1层和第2层:
内存池,有Python的接口函数PyMem_Malloc实现若请求分配的内存在1~256字节之间就使用内存池管理系统进行分配,调用malloc函数分配内存,但是每次只会分配一块大小为256K的大块内存,不会调用free函数释放内存,将该内存块留在内存池中以便下次使用。
第0层:
大内存—–若请求分配的内存大于256K,malloc函数分配内存,free函数释放内存。第-1,-2层:
操作系统进行操作
4. 总结
先从较浅的层面来说,Python的内存管理机制可以从三个方面来讲
- 垃圾回收
- 引用计数
- 内存池机制
python的内存回收机制以引用计数为主,标记-清除和分代回收为辅
python变量的存储有三个区域
- 事先分配的静态内存
- 事先分配的可重复利用内存
- 需要通过malloc和free来控制的自由内存
当某个对象引用数变为0时并不是直接将它从内存空间中清除掉,而是采用垃圾回收机制gc模块,当这些引用数为0的变量规模达到一定规模,就自动启动垃圾回收,将那些引用数为0的对象所占的内存空间释放。
引用计数针对可重复利用的内存和自由内存
- 每个对象都有一个计数器count,记住了有多少个变量指向这个对象,当这个对象的引用计数器为0时
- 假如这个对象在缓冲区内,那么它地址空间不会被释放,而是等待下一次被使用,而非缓冲区的该释放就释放。
分代回收方法 :
将对象根据存活的时间分为三
代,- 所有新建的对象都是0代,当0代对象经过一次自动垃圾回收,没有被释放的对象会被归入1代,同理1代归入2代。
- 每次当0代对象中引用数为0的对象超过700个时,启动一次0代对象扫描垃圾回收,经过10次的0代回收,就进行一次0代和1代回收,1代回收次数超过10次,就会进行一次0代、1代和2代回收。
- 而这里的几个值是通过查询get_threshold()返回(700,10,10)得到的。此外,gc模块还提供了手动回收的函数,即gc.collect()。
标记-清除针对解决循环引用问题 :
- 每一次分代回收都会启用标记-清除
- 每个变量不仅有一个引用计数,还有一个有效引用计数
gc_ref, - 后者一开始等于前者,但是启动标记清除法开始遍历对象时,从root object(一些不能被释放的对象,一些全局引用或者函数栈中的引用)出发
- root object和在图中能够直接或者间接与它们相连的对象就放入reachable
- 而不能通过root object访问到且有效引用个数变为0的对象作为放入unreachable,从而通过这种方式来消去循环引用的影响。
模块和包的导入机制
模块与包的不同的:
- 模块 : 一个
.py文件就是一个模块(module) - 包 :
__init__.py文件所在目录就是包(package)
第一次导入模块:
底层做了3件事情,在自己的命名空间执行被导入模块中的所有代码;
以模块名为名称创建一个模块对象,并将模块中所有的顶级变量(包括变量和函数)以属性的形式绑定在该模块对象上;
在import位置引入该对象名称到当前命名空间。
这就是在当前命名空间使用被导入模块中的属性时要使用“.”语法的原因
第二次导入模块:
直接执行第3步,即在import位置引入该对象名称到当前命名空间。
原因是第一次导入之后,已经将前两步执行的结果存储到内存中,第二次导入时直接到相应的内存寻找即可,不需浪费更多内存于此。因此,第二次导入速度更快,且更节省内存
import M和from A import B两种导入方式在底层执行机制的异同(重点):
- 两种导入方式第一次导入都会执行上述3步,
- 第二次或更多次导入则只会执行第三步,所以两种导入方式没有谁比谁更节省内存之说,不要认为后者只是导入了模块中的一部分就觉得后者比较省内存,实际都是会首先执行被导入模块中的所有内容,占的内存是相同的,区别在于是拿被导入模块中的哪些部分到当前命名空间中进行使用
被导入模块位置的检索顺序:
第一级是内置模块,如sys模块,这类模块优先级最高;
这些模块在 Python 解释器启动时就加载到了
sys.modules中缓存起来了- 内置模块不是标准库,是指
sys.builtin_module_names输出的字符串元祖。 - 解释器启动时确实会加载
buit-in module,但是,执行print(sys.builtin_module_names)发现,os并不是built-in module。所以,解释器执行 python 文件时,不仅仅是加载了内置模块的!!!使用sys.modules可以看到实际启动时加载的所有模块。
- 内置模块不是标准库,是指
第二级是sys.path路径列表。其中sys.path路径列表路径列表由四部分组成,分别是
- 当前目录;
- 环境变量PYTHONPATH中指定的路径列表;
- 指定路径下的.pth文件中的文件路径列表;
- python的安装路径及其中的lib库
import 的实际过程十分复杂,不过其大致过程可以简化为:
1
2
3
4
5
6
7
8
9
10
11
12
13def import(module_name):
# sys.modules 用于缓存,避免重复 import 带来的开销
if module_name in sys.modules:
return sys.modules[module_name]
else:
module_path = find(module_name)
if module_path:
module = load(module_path)
sys.modules[module_name] = module
return module
else:
raise ImportErrorimport 会生成 .pyc 文件,.pyc 文件的执行速度不比 .py 快,但是加载速度更快
Python的函数重载机制
重载(overload)和覆盖(override),在C++,Java,C#等静态类型语言类型语言中,这两个概念同时存在。- 重载是为了让同一个函数名(方法名)匹配不同的参数(个数不同,类型不同)
- 覆盖是为了实现多态,在相同名称的函数(方法)和参数,在不同的类中(父类,子类),有不同的实现。
函数重载 : 名字相同但参数类型或个数不同时执行不同的函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def func(args):
print('ordinary')
def _func(args):
print('str')
def _func(args):
print('int')
def _func(args):
print('list')
if __name__ == '__main__':
func(1) # int
func('h') # str
func([1,2]) # list
func(object) # ordinary
func(lambda x:x) # ordinary
- 只要不和原函数一样 , 重载函数的名字可以顺便取.
(就是说这里的三个_func可以改为A,B,C,D)singledispatch只支持根据第一个参数的类型来重载
代码执行顺序
1 | # evalsupport.py |
1 | # evaltime.py |
1 | # evaltime_meta.py |
运行evaltime.py,得到:
1 | <[100]> evalsupport module start # 先运行被导入模块 |
运行evaltime_meta.py,得到:
1 | <[100]> evalsupport module start |
结论:
扫描类的时候就会扫描类里面的定义体
- 这个步骤是为了知道这个类有什么属性
- 如果类里面还定义了类B(如:定义了描述符),那么一样也会扫描类B
一个类如果被装饰了,那么在扫描完类里面的定义体后,立马就会去扫描装饰器
因为
1
2
3
class ClassThree():
pass其实就等于:
1
2
3class ClassThree():
pass
ClassThree = deco_alpha(ClassThree)相当于直接运行了deco_alpha函数
一个类A如果有元类,那么类A在扫描完后马上就会执行元类
一个类A,继承了类B,类B有元类C,那么,类A在扫描完毕之后马上就会去扫描元类
注意这种偷偷更换类方法的做法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
print('<[200]> deco_alpha')
def inner_1(self):
print('<[300]> deco_alpha:inner_1')
cls.method_y = inner_1
return cls
class ClassThree():
print('<[7]> ClassThree body')
def method_y(self):
print('<[8]> ClassThree.method_y')
同步异步,阻塞非阻塞举例
以小明下载文件打个比方
同步阻塞:小明一直盯着下载进度条,到 100% 的时候就完成。
同步体现在:等待下载完成通知;
阻塞体现在:等待下载完成通知过程中,不能做其他任务处理;
同步非阻塞:小明提交下载任务后就去干别的,每过一段时间就去瞄一眼进度条,看到 100% 就完成。
同步体现在:等待下载完成通知;
非阻塞体现在:等待下载完成通知过程中,去干别的任务了,只是时不时会瞄一眼进度条;【小明必须要在两个任务间切换,关注下载进度】
异步阻塞:小明换了个有下载完成通知功能的软件,下载完成就“叮”一声。不过小明仍然一直等待“叮”的声音(看起来很傻,不是吗)。
异步体现在:下载完成“叮”一声通知;
阻塞体现在:等待下载完成“叮”一声通知过程中,不能做其他任务处理;
异步非阻塞:仍然是那个会“叮”一声的下载软件,小明提交下载任务后就去干别的,听到“叮”的一声就知道完成了。
异步体现在:下载完成“叮”一声通知;
非阻塞体现在:等待下载完成“叮”一声通知过程中,去干别的任务了,只需要接收“叮”声通知即可;【软件处理下载任务,小明处理其他任务,不需关注进度,只需接收软件“叮”声通知,即可】
进程里的Queue
1 | from multiprocessing import Process,Queue |
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到如下的错误信息:
RuntimeError: Queue objects should only be shared between processs through inheritance
1 | from multiprocessing import Manager,Pool |
特性与描述符
1 | class Person: |
1 | class Descriptor: |
描述符优于特性的地方 :
特性只能使用客户类的属性,描述符有自己的属性,并且可以调用自己的属性。
1 | class Descriptor: |
僵尸进程与孤儿进程
正常情况下,子进程是通过父进程创建的,子进程再创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程: 父进程退出,子进程还在运行的这些子进程都是孤儿进程,孤儿进程将被init 进程(进程号为1)所收养,并由init 进程对他们完成状态收集工作。
僵尸进程: 进程使用 fork 创建子进程,如果子进程退出,而父进程并没有调用wait 获取waitpid 获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中的这些进程是僵尸进程。
启动一个程序,开始我们的任务,然后等任务结束了,我们就停止这个进程。 进程停止后, 该进程就会从进程表中移除。但是,有时候有些程序即使执行完了也依然留在进程表中。那么,这些完成了生命周期但却依然留在进程表中的进程,我们称之为 “僵尸进程”。
当你运行一个程序时,它会产生一个父进程以及很多子进程。 所有这些子进程都会消耗内核分配给它们的内存和 CPU 资源。
这些子进程完成执行后会发送一个 Exit 信号然后死掉。这个 Exit 信号需要被父进程所读取。父进程需要随后调用
wait命令来读取子进程的退出状态,并将子进程从进程表中移除。若父进程正确第读取了子进程的 Exit 信号,则子进程会从进程表中删掉。
但若父进程未能读取到子进程的 Exit 信号,则这个子进程虽然完成执行处于死亡的状态,但也不会从进程表中删掉。
针对于僵尸进程 :
- 孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,
- init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。
- 这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。
- 因此孤儿进程并不会有什么危害。
针对于僵尸进程 :
unix提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。这种机制就是:
- 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放。
- 但这样就导致了问题,如果进程不调用wait / waitpid的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
避免僵尸进程的方法:
- fork 两次用孙子进程去完成子进程的任务
- 用wait()函数使父进程阻塞
- 使用信号量,在signal handler 中调用waitpid,这样父进程不用阻塞
Linux 五种IO模型
用户空间与内核空间
- 操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限
- 为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为
内核空间,一部分为用户空间
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
- 保存处理机上下文,包括程序计数器和其他寄存器。
- 更新PCB信息。
- 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
- 选择另一个进程执行,并更新其PCB。
- 更新内存管理的数据结构。
- 恢复处理机上下文。
进程的阻塞
- 正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。
- 可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。
- 当进程进入阻塞状态,是不占用CPU资源的。
文件描述符
文件描述符(File descriptor)是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。
当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 IO
- 缓存 IO 又被称作
标准 IO,大多数文件系统的默认 IO 操作都是缓存 IO。 - 在 Linux 的缓存 IO 机制中,操作系统会将 IO 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
Linux IO模型
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作
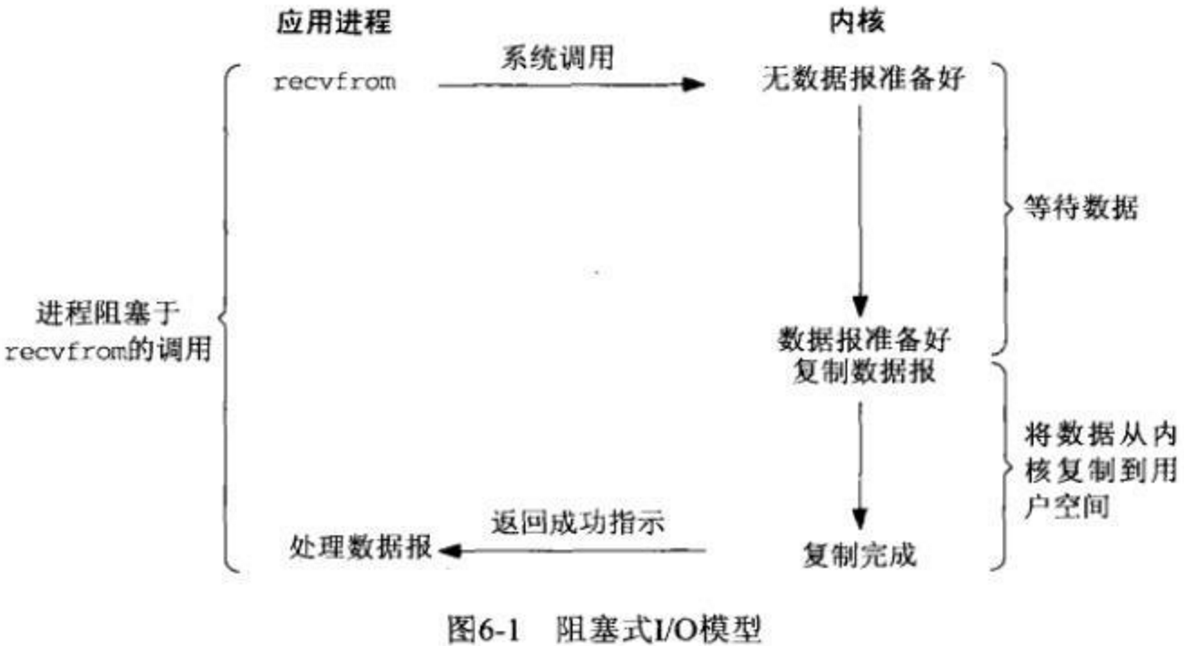
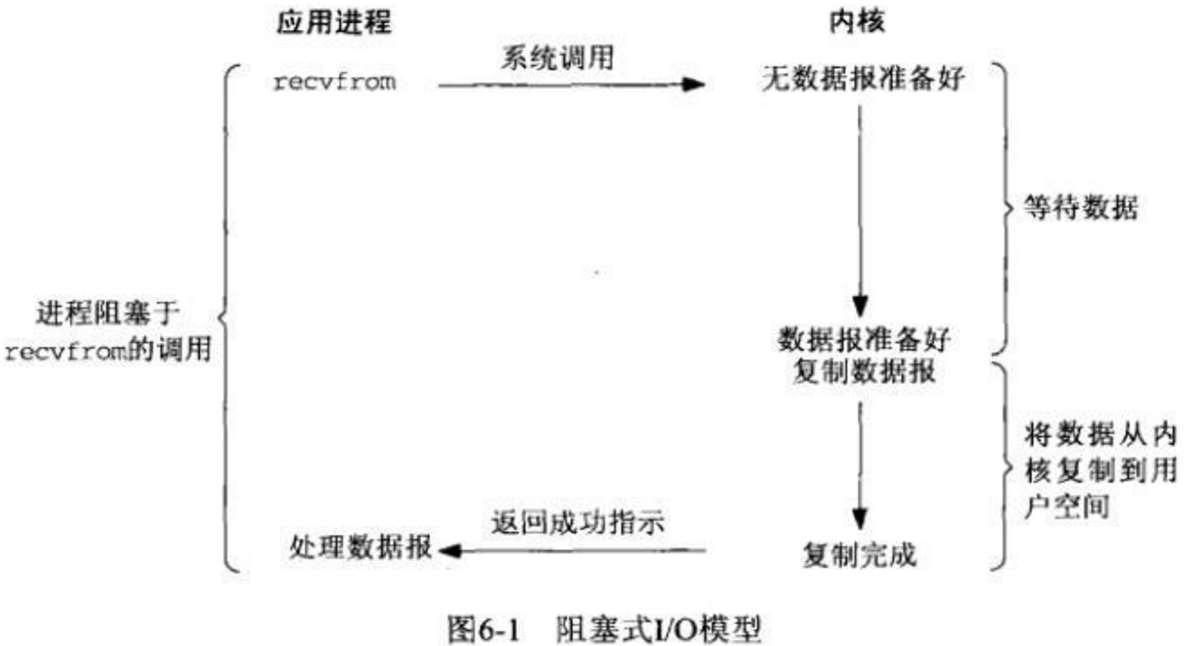
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
- 第一阶段:等待数据准备 (Waiting for the data to be ready)。
- 第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。
对于socket流而言,
- 第一步:等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
- 第二步:把数据从内核缓冲区复制到应用进程缓冲区。
网络应用需要处理的无非就是两大类问题,
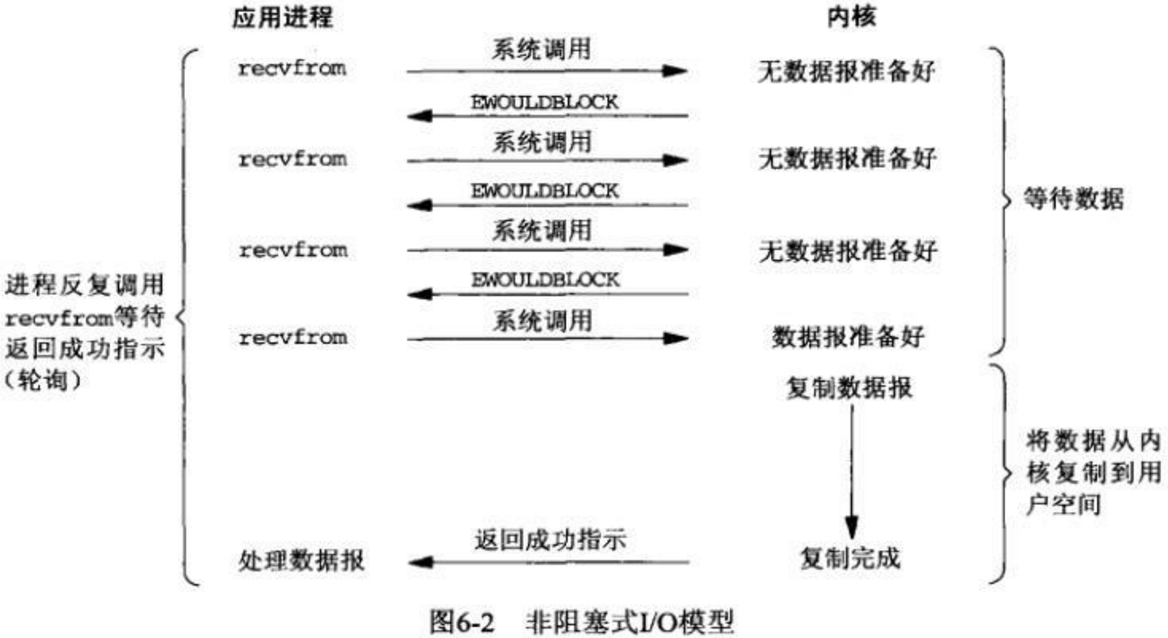
网络IO,数据计算。相对于后者,网络IO的延迟,给应用带来的性能瓶颈大于后者。网络IO的模型大致有如下几种:- 同步模型(synchronous IO)
- 阻塞IO(bloking IO)
- 非阻塞IO(non-blocking IO)
- 多路复用IO(multiplexing IO)
- 信号驱动式IO(signal-driven IO)
- 异步IO(asynchronous IO)
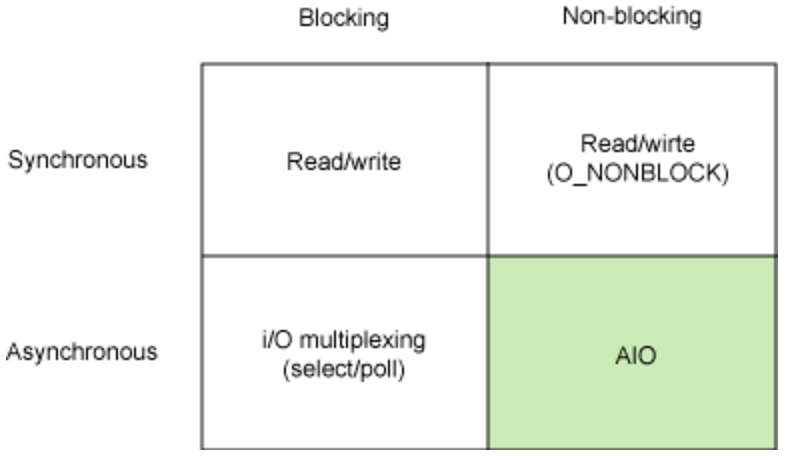
每个 IO 模型都有自己的使用模式,它们对于特定的应用程序都有自己的优点。
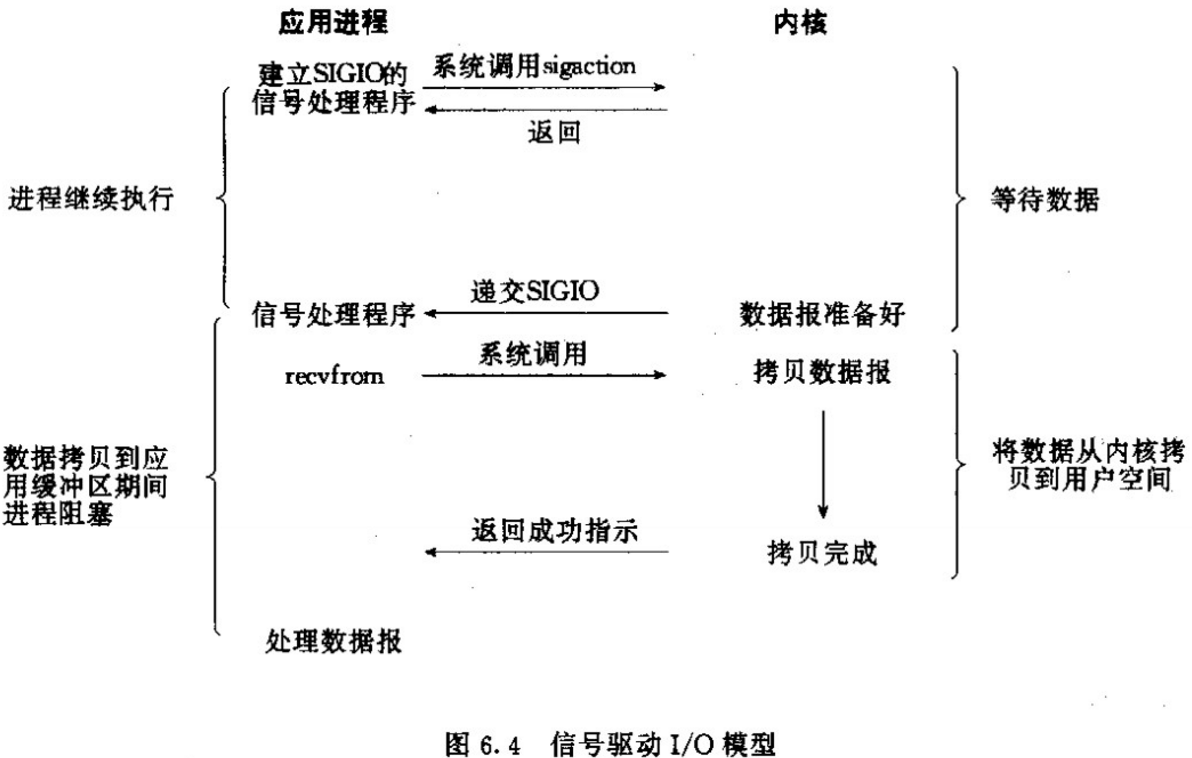
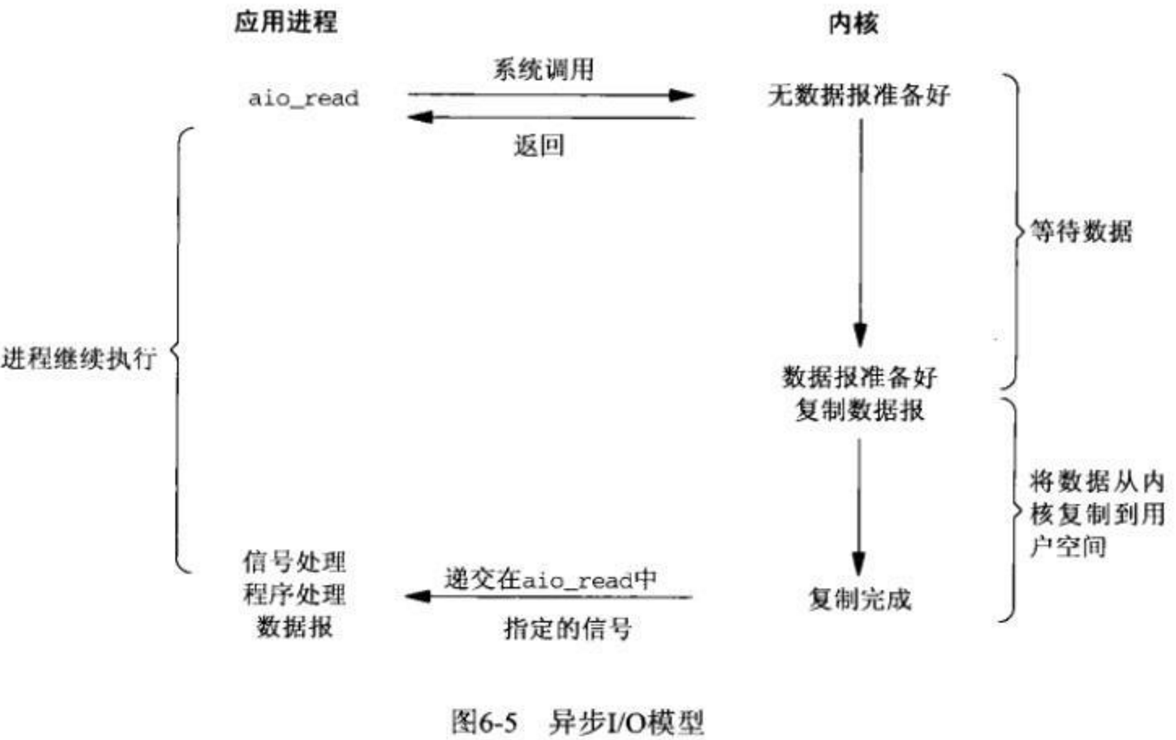
I/O多路复用技术(multiplexing)
I/O多路复用技术(multiplexing):
就是很多网络连接(多路),共(复)用少数几个(甚至是一个)线程。
通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,pselect,poll,epoll本质上都是同步I/O- 连接很多的时候,不能每个连接一个线程,会耗尽系统内存的。
- 线程也不能阻塞在任何一个连接上,等新的数据来,这样就不能及时响应其他连接发来的数据了;
- 也不能用非阻塞方式,不能轮询所有的连接,这会浪费掉大量CPU时间;
- 只能告诉系统,我对哪些连接感兴趣,有消息来的时候,通知我处理。
- 根据平台不同,可能会用到select/devpoll/epoll/kqueue/IOCP。
举例说明:
模拟一个tcp服务器处理30个客户socket。假设你是一个超市老板,30个用户分别买不同的东西,但是有的商品有库存有的商品没有库存需要等待供应商送货,然后有下面几个选择:
- 按顺序逐个检查,A用户先来买卫生纸,B用户买手电筒,C用户买泡面。。。。,逐个处理的结果是A用户买完走了,但是B用户的商品卖完了等待供应商送货30分钟后货送到了B购买成功,继续处理C用户。。。,这样处理就相当于最后的需要等待前面的用户全部购买成功才能继续购买。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
- 你创建30个分身,每个分身去负责处理每个用户的购买请求。 这种类似于为每一个用户创建一个进程或者线程处理连接,但是Redis是单线程的
- 当A请求购买时 有货告知可以买 然后A购买,B请求购买 需要等待供应商送货 等待直到供应商送货过来 告知B来货了 B发起购买 购买成功;在B等待供应商的期间C用户的购买请求开始处理 有货直接购买成功 无需等待B用户购买。 这种就是IO复用模型
阻塞I/O模型 :
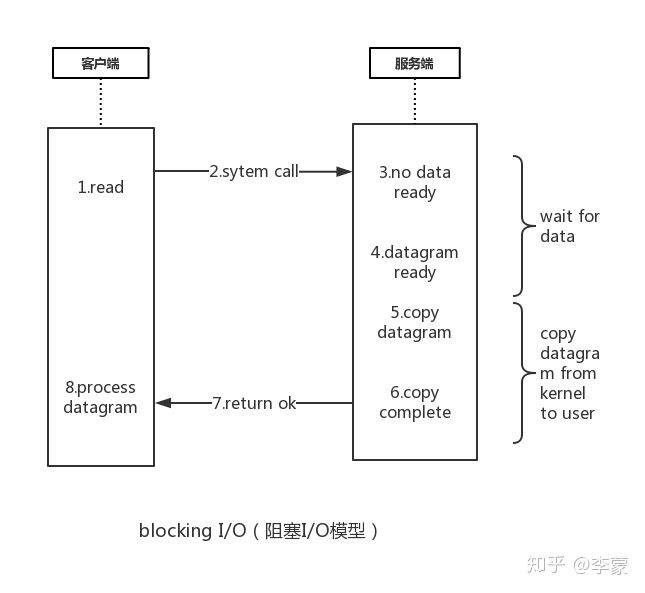
- 客户端发起读(read)的命令
- 调用redis服务端
- 此时没有数据
- 数据报准备完成
- 复制数据报
- 复制完成
- 返回成功
- 客户端 处理数据报
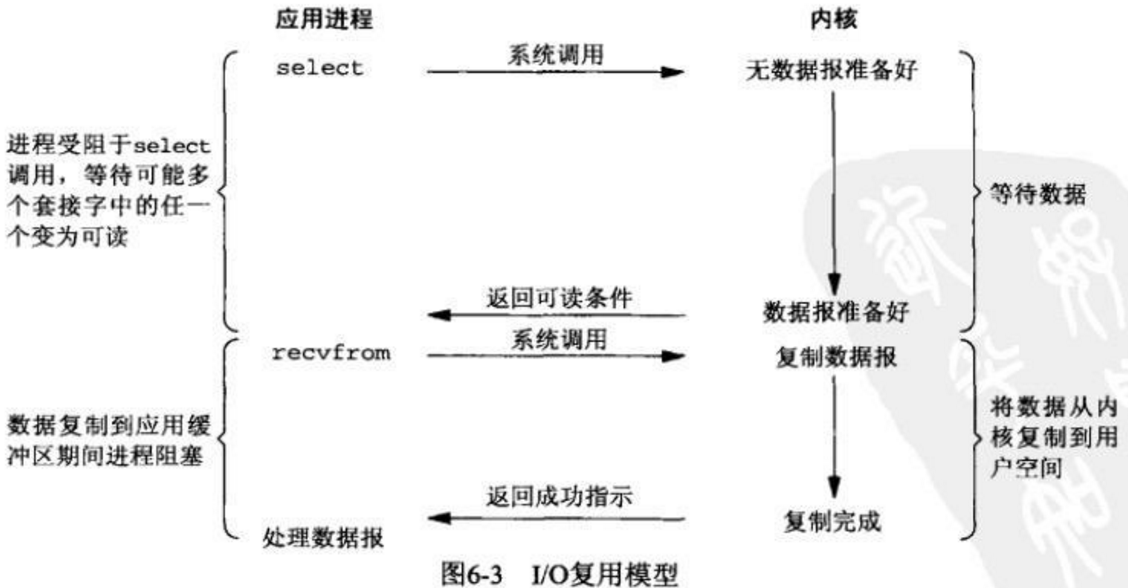
多路复用I/O模型:
- redis客户端先去select循环询问服务端是否可以发起read 这个过程是阻塞的 但是速度很快,当服务端准备好了数据报告诉客户端readable,客户端即可发起read请求,此时因为服务端已经准备好了数据报,直接返回即可。
- 整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的。这种方式避免了线程的阻塞,又称为非阻塞I/O模型
- 这里
多路指的是多个网络连接,复用指的是复用同一个线程。 - 采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗)
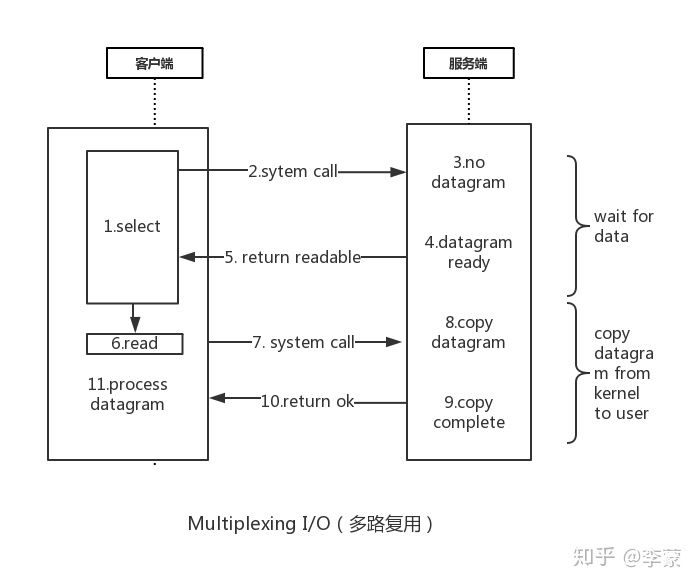
- 客户端select机制 循环请求
- 去请求服务端 询问是否可以read
- 此时没有数据
- 数据报准备完成
- 服务端告诉客户端 可以read了
1~5 这个过程是阻塞的 - 客户端发起read
- 系统调用read
- 复制数据报
- 复制完成
- 返回成功
- 客户端 处理数据报
在最开始的时候,为了实现一个服务器可以支持多个客户端连接,人们想出了fork/thread等办法,当一个连接来到的时候,就fork/thread一个进程/线程去接收并且处理请求,然而,当时大家都穷,没啥钱买电脑,所以这个模型一直很好用,过去几十年都没有问题。
人们终于意识到了这种问题,所以发明了一种叫做
IO多路复用的模型,这种模型的好处就是: 没必要开那么多条线程和进程了,一个线程一个进程就搞定了。select函数发明:
一个连接来了,就必须遍历所有已经注册的文件描述符,来找到那个需要处理信息的文件描述符,如果已经注册了几万个文件描述符,那会因为遍历这些已经注册的文件描述符,导致cpu爆炸。epoll方法
每当一个学生入住新宿舍的时候,楼妈就记录下这个人的名字,学号,电话,以及宿舍房号。当小春找小丽的时候,楼妈掏出眼镜,查表,马上就能知道小丽在哪里了,小春几分钟就到达了小丽的宿舍….
在现代工业中我们会面临两个问题:
- 单线程模型不能有阻塞,一旦发生任何阻塞(包括计算机计算延迟)都会使得这个模型不如多线程。另外,单线程模型不能很好的利用多核cpu
- 既然不能有阻塞,那我们只有用多线程去做异步io,那马上就会面临回调地狱。
为了解决我上述说的两个问题人们做出了一些改进:
- 利用多进程,每个进程单条线程去利用多核CPU。但是这又引入了新的问题:进程间状态共享和通信。但是对于提升的性能来说,可以忽略不计。
- 发明了协程。
IO无非就是几种
- 读硬盘
- 写硬盘
- 网络请求(读和写)
所有的读和写,网络请求接口都要设置成非阻塞式的,当系统内核把这些玩意儿执行完毕以后,再通过回调函数,通知用户处理。在用户空间上来看,我们就一直保持在一个线程,一个进程之中,因此,这种速率极高!
常用的设计模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
- 创建者模式
- 原型模式
- 单例模式
设计模式七大原则
开放封闭原则:一个软件实体如类,模块和函数应该对扩展是开放的,对修改是关闭的。即软件实体应尽量在不修改原有代码的情况下进行扩展(装饰器)
里氏替换原则:重写父类里面的方法,逻辑可能不一样,但是返回的结果参数啥的要一样(所有引用基类的地方必须能透明的使用其子类的对象)
依赖倒置原则:高层模块不应该依赖低层模块,二者都应该依赖其抽象,要针对接口编程,而不是针对实现编程。(接口类)
接口隔离原则:使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要实现的接口
迪米特法则:一个软件实体应当尽可能少的与其他实体发生相互作用
单一职责原则:一个类只负责一项职责(不要存在多于一个导致类变更的原因,即一个类只负责一项职责)
合同复用原则:多用组合少用继承.
一个类重用另一个类的代码有两种方式
- 继承
- 组合
接口隔离原则
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
from abc import abstractmethod,ABCMeta #借助abc模块来实现接口
#接口类就是为了提供标准,约束后面的子类
class Animal(metaclass=ABCMeta):
def walk(self):
pass
def fly(self):
pass
def swim(self):
pass
class Frog(Animal):
'''像是这样定义一个青蛙类,由于接口类的方法都要被实现,而青蛙只会走,没不要要实现其他的方法
动物不同会的功能也会不同,所以这时候我们就可以选择用接口隔离原则
'''
def walk(self):
print('青蛙会走')
obj = Frog()
obj.walk() #会报错
# =====================改进-=================
class AnimalOnLand(metaclass=ABCMeta):
'''在陆地上的动物'''
def walk(self):
pass
class AnimalInSky(metaclass=ABCMeta):
'''飞行动物'''
def fly(self):
pass
class AnimalInWater(metaclass=ABCMeta):
'''在水里的动物'''
def swim(self):
pass
class Tiger(AnimalOnLand):
def walk(self):
print('老虎在地上')
class Frog(AnimalOnLand,AnimalInWater):
def swim(self):
print('青蛙会游')
def walk(self):
print('会跳')
obj = Tiger()
obj.walk()
obj = Frog()
obj.walk()
obj.swim()继承和组合
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class A:
def test(self):
return '你好啊'
class B(A): #继承
def test(self):
return 123
class C:
def __init__(self):
self.a = A() #组合
self.a.test()
def test(self):
return 789
print(B().test())
print(C().a)
print(C().a.test())
print(C().test())
简单工厂模式
内容 :
不直接向客户端暴露对象创建的实现细节,而是通过一个工厂类来负责创建产品类的实例。角色 :
- 工厂角色(Creator)
- 抽象产品角色(Product)
- 具体产品角色(Concrete Product)
优点
- 隐藏了对象创建的实现细节
- 客户端不需要修改代码
缺点
- 违反了单一职责原则,将创建逻辑集中到一个工厂类中
- 当添加新产品时,需要修改工厂类代码,违反了开放封闭原则
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 初始的
from abc import abstractmethod,ABCMeta
class Payment(metaclass=ABCMeta):
def pay(self):
pass
class Alipay(Payment):
def __init__(self,money):
self.money = money
def pay(self):
print('支付宝支付了%s元'%self.money)
class Whatpay(Payment):
def __init__(self, money):
self.money = money
def pay(self):
print('微信支付了%s元' % self.money)
obj = Alipay(100)
obj.pay()
obj2 = Whatpay(200)
obj2.pay()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# 类工厂
from abc import abstractmethod,ABCMeta
class Payment(metaclass=ABCMeta):
def pay(self,money):
pass
class Alipay(Payment):
def pay(self, money):
print('支付宝支付了%s元'%money)
class Applepay(Payment):
def pay(self, money):
print('微信支付了%s元' %money)
class Yuebao(Payment):
def pay(self,money):
print('余额宝支付了%s元' %money)
class PaymentFactory:
'''工厂类:封装了对象创建的细节'''
def create_payment(self,method):
if method =='alipay':
return Alipay()
elif method =='applepay':
return Applepay()
elif method =='yuebao':
return Yuebao()
else:
return NameError(method)
factory = PaymentFactory()
alipay=factory.create_payment('yuebao')
alipay.pay(100)
工厂方法模式
内容
定义一个用于创建对象的接口(工厂接口),让子类决定实例化哪一个产品类角色
- 抽象工厂角色(Creator)
- 具体工厂角色(Concrere Creator)
- 抽象产品角色(Product)
- 具体产品角色(Concrete Product)
工厂方法模式相比简单工厂模式将每个具体产品都对应一个具体工厂
优点
- 每个具体产品都对应一个具体工厂类,不需要修改工厂类代码
- 隐藏了对象创建的实现细节
缺点
- 每增加一个具体产品类,就必须增加一个相应的具体工厂类
使用场景
- 需要生产多种、大量复杂对象的时候
- 需要降低耦合度的时候
- 当系统的产品种类需要经常扩展的时候
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35from abc import ABCMeta,abstractmethod
class Payment(metaclass=ABCMeta):
def pay(self,money):
pass
class Alipay(Payment):
def pay(self, money):
print('支付宝支付了%s元'%money)
class Applepay(Payment):
def pay(self, money):
print('微信支付了%s元' %money)
class PaymentFactory(metaclass=ABCMeta):
def create_payment(self):
pass
class AlipayFactory(PaymentFactory):
def create_payment(self):
return Alipay()
class AppleFactory(PaymentFactory):
def create_payment(self):
return Applepay()
apple = AppleFactory()
apple.create_payment().pay(100)
alipay = AlipayFactory()
alipay.create_payment().pay(300)原来的工厂类是:
1
2
3
4
5
6
7
8
9
10
11class PaymentFactory:
'''工厂类:封装了对象创建的细节'''
def create_payment(self,method):
if method =='alipay':
return Alipay()
elif method =='applepay':
return Applepay()
elif method =='yuebao':
return Yuebao()
else:
return NameError(method)改为:
1
2
3
4
5
6
7
8
9
10
11
12class PaymentFactory(metaclass=ABCMeta):
def create_payment(self):
pass
class AlipayFactory(PaymentFactory):
def create_payment(self):
return Alipay()
class AppleFactory(PaymentFactory):
def create_payment(self):
return Applepay()简单工厂模式的角色为:
- 工厂角色(Creator)
- 抽象产品角色(Product)
- 具体产品角色(Concrete Product)
工厂方法模式的角色为:
- 抽象工厂角色(Creator)
- 具体工厂角色(Concrere Creator)
- 抽象产品角色(Product)
- 具体产品角色(Concrete Product)
也就是说,把
工厂角色拆分成了抽象工厂角色和具体工厂角色
抽象工厂模式
内容:
定义一个工厂类接口,当工厂子类来创建一系列相关或相互依赖的对象例:生产一部手机,需要手机壳、CPU、操作系统三类对象进行组装,其中每类对象都有不同的种类。对每个具体工厂,分别生产一部手机所需要的三个对象。
角色
- 抽象工厂角色(Creator)
- 具体工厂角色(Concrete Creator)
- 抽象产品角色(Product)
- 具体产品角色(Concrete Product)
- 客户端(Client)
相比工厂方法模式,抽象工厂模式中的每个具体工厂都产生一套产品
优点
- 将客户端与类的具体实现相分离
- 每个工厂创建了一个完整的产品系列,使得易于交换产品系列
- 有利于产品的一致性(即产品之间的约束关系)
缺点
- 难以支持新种类的(抽象)产品
使用场景
- 系统要独立于产品的创建与组合时
- 强调一系列相关的产品对象的设计以便进行联合使用时
- 提供一个产品类库,想隐藏产品的具体实现时
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119from abc import abstractmethod,ABCMeta
#==============抽象产品============
class PhoneShell(metaclass=ABCMeta):
'''手机壳'''
def show_shell(self):
pass
class CPU(metaclass=ABCMeta):
'''CPU'''
def show_cpu(self):
pass
class OS(metaclass=ABCMeta):
'''操作系统'''
def show_os(self):
pass
# ===============抽象工厂==============
class PhoneFactory(metaclass=ABCMeta):
def make_shell(self):
'''制作手机壳'''
pass
def make_cpu(self):
'''制作cpu'''
pass
def make_os(self):
'''制作手机壳'''
pass
# =================具体产品==============
class SmallShell(PhoneShell):
def show_shell(self):
print('普通手机小手机壳')
class BigShell(PhoneShell):
def show_shell(self):
print('普通手机大手机壳')
class AppleShell(PhoneShell):
def show_shell(self):
print('苹果手机壳')
class YingTeerCPU(CPU):
def show_cpu(self):
print('英特尔cpu')
class MediaCPU(CPU):
def show_cpu(self):
print('联发科cpu')
class AppleCPU(CPU):
def show_cpu(self):
print('苹果cpu')
class Android(OS):
def show_os(self):
print('Android系统')
class IOS(OS):
def show_os(self):
print('ios系统')
# ==============具体工厂================
class MiFactory(PhoneFactory):
def make_shell(self):
return SmallShell()
def make_cpu(self):
return AppleCPU()
def make_os(self):
return Android()
class HuaWeiactory(PhoneFactory):
def make_shell(self):
return BigShell()
def make_cpu(self):
return YingTeerCPU()
def make_os(self):
return Android()
# ===============使用===============
class Phone:
def __init__(self,cpu,os,shell):
self.cpu = cpu
self.os = os
self.shell = shell
def show_info(self):
print('手机信息')
self.cpu.show_cpu()
self.os.show_os()
self.shell.show_shell()
def make_phone(factory):
cpu = factory.make_cpu()
os = factory.make_os()
shell = factory.make_shell()
return Phone(cpu,os,shell)
p1 = make_phone(HuaWeiactory())
p1.show_info()
p2 = make_phone(MiFactory())
p2.show_info()
建造者模式
内容
将一个复杂对象的构建与它表示分离,使得同样的构建过程可以创建不同的表示角色
- 抽象建造者
- 具体建造者
- 指挥者
- 产品
建造者模式与抽象工厂模式相似,也用来创建复杂对象。
主要区别是建造者模式着重一步步构造一个复杂对象,而抽象工厂模式着重于多个系列的产品对象。优点
- 隐藏了一个产品的内部结构和装配过程
- 将构造代码与表示代码分开
- 可以将构建过程进行更精细的控制
使用场景
- 当创建复杂对象的算法(Director)应该独立于该对象的组成部分以及它们的装配方式(Builder)时
- 当构造过程允许被构造的对象有不同的表示时(不同Builder)
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80import random
from abc import abstractmethod, ABCMeta
#------产品------
class Player:
def __init__(self, face=None, body=None, arm=None, leg=None):
self.face = face
self.arm = arm
self.leg = leg
self.body = body
def __str__(self):
return "%s, %s, %s, %s" % (self.face, self.arm, self.body, self.leg)
#------建造者------
class PlayerBuilder(metaclass=ABCMeta):
def build_face(self):
pass
def build_arm(self):
pass
def build_leg(self):
pass
def build_body(self):
pass
def get_player(self):
pass
class BeautifulWomanBuilder(PlayerBuilder):
def __init__(self):
self.player = Player()
def build_face(self):
self.player.face = "漂亮脸蛋"
def build_arm(self):
self.player.arm="细胳膊"
def build_body(self):
self.player.body="细腰"
def build_leg(self):
self.player.leg="长腿"
def get_player(self):
return self.player
class RandomPlayerBuilder(PlayerBuilder):
def __init__(self):
self.player = Player()
def build_face(self):
self.player.face = random.choice(["瓜子脸","西瓜子脸"])
def build_arm(self):
self.player.arm=random.choice(["长胳膊","短胳膊"])
def build_body(self):
self.player.body=random.choice(["苗条","胖"])
def build_leg(self):
self.player.leg=random.choice(["长腿","短腿"])
def get_player(self):
return self.player
class PlayerDirector:
def __init__(self, builder):
self.builder = builder
# 控制组装顺序
def build_player(self):
self.builder.build_body()
self.builder.build_face()
self.builder.build_arm()
self.builder.build_leg()
return self.builder.get_player()
pd = PlayerDirector(RandomPlayerBuilder())
p = pd.build_player()
print(p)
原型模式
内容:
假如你爱玩游戏,你能想到游戏里面有很多的角色,但是其实你有没有注意:脸型,身材,眼睛..这些其实都是略有不同的搭配, 这也就是原型的作用:不需要你每次都制造一个复杂的人物,只是根据一个原型的人物做些简单的修改即可代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# 这里肯定要做深拷贝,要不然python的就是对象的引用
from copy import deepcopy
class Prototype:
def __init__(self):
self._objs = {}
def registerObject(self, name, obj):
"""注册对象"""
self._objs[name] = obj
def unregisterObject(self, name):
"""取消注册"""
del self._objs[name]
def clone(self, name, **attr):
"""克隆对象"""
obj = deepcopy(self._objs[name])
# 但是会根据attr增加或覆盖原对象的属性
obj.__dict__.update(attr)
return obj
if __name__ == '__main__':
class A:
pass
a=A()
prototype=Prototype()
prototype.registerObject("a",a)
b=prototype.clone("a",a=1,b=2,c=3)
# 这里会返回对象a
print(a)
# 这里的对象其实已经被修改成(1, 2, 3)
print(b.a, b.b, b.c)
单例模式
内容
保证一个类只有一个实例,并提供一个访问它的全局访问点角色
单例使用场景
- 当类只有一个实例而且客户可以从一个众所周知的访问点访问它时
- 比如:数据库链接、Socket创建链接
优点
- 对唯一实例的受控访问
- 单利相当于全局变量,但防止了命名空间被污染
与单利模式功能相似的概念:
全局变量、静态变量(方法)为什么用单例模式,不用全局变量呢?
答、全局变量可能会有名称空间的干扰,如果有重名的可能会被覆盖
单例模式的四种实现方式
文件导入的形式(常用)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18############ s1.py ############
class Foo(object):
def test(self):
print("123")
v = Foo()
#v是Foo的实例
############ s2.py ############
from s1 import v as v1
print(v1,id(v1)) #<s1.Foo object at 0x0000000002221710> 35788560
from s1 import v as v2
print(v1,id(v2)) #<s1.Foo object at 0x0000000002221710> 35788560
# 两个的内存地址是一样的
# 文件加载的时候,第一次导入后,再次导入时不会再重新加载。基于类实现的单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65# ======================单例模式:无法支持多线程情况===============
class Singleton(object):
def __init__(self):
import time
time.sleep(1)
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance
import threading
def task(arg):
obj = Singleton.instance()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()
# ====================单例模式:支持多线程情况================、
import time
import threading
class Singleton(object):
_instance_lock = threading.Lock()
def __init__(self):
time.sleep(1)
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
with Singleton._instance_lock: #为了保证线程安全在内部加锁
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance
def task(arg):
obj = Singleton.instance()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()
time.sleep(20)
obj = Singleton.instance()
print(obj)
# 使用先说明,以后用单例模式,obj = Singleton.instance()
# 示例:
# obj1 = Singleton.instance()
# obj2 = Singleton.instance()
# print(obj1,obj2)
# 错误示例
# obj1 = Singleton()
# obj2 = Singleton()
# print(obj1,obj2)基于__new__实现的单例模式(最常用)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# =============单线程下执行===============
import threading
class Singleton(object):
_instance_lock = threading.Lock()
def __init__(self):
pass
def __new__(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
with Singleton._instance_lock:
if not hasattr(Singleton, "_instance"):
# 类加括号就回去执行__new__方法,__new__方法会创建一个类实例:Singleton()
Singleton._instance = object.__new__(cls) # 继承object类的__new__方法,类去调用方法,说明是函数,要手动传cls
return Singleton._instance #obj1
#类加括号就会先去执行__new__方法,在执行__init__方法
# obj1 = Singleton()
# obj2 = Singleton()
# print(obj1,obj2)
# ===========多线程执行单利============
def task(arg):
obj = Singleton()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()
# 使用先说明,以后用单例模式,obj = Singleton()
# 示例
# obj1 = Singleton()
# obj2 = Singleton()
# print(obj1,obj2)基于metaclass(元类)实现的单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65"""
1.对象是类创建,创建对象时候类的__init__方法自动执行,对象()执行类的 __call__ 方法
2.类是type创建,创建类时候type的__init__方法自动执行,类() 执行type的 __call__方法(类的__new__方法,类的__init__方法)
# 第0步: 执行type的 __init__ 方法【类是type的对象】
class Foo:
def __init__(self):
pass
def __call__(self, *args, **kwargs):
pass
# 第1步: 执行type的 __call__ 方法
# 1.1 调用 Foo类(是type的对象)的 __new__方法,用于创建对象。
# 1.2 调用 Foo类(是type的对象)的 __init__方法,用于对对象初始化。
obj = Foo()
# 第2步:执行Foo的 __call__ 方法
obj()
"""
# ===========类的执行流程================
class SingletonType(type):
def __init__(self,*args,**kwargs):
print(self) #会不会打印? #<class '__main__.Foo'>
super(SingletonType,self).__init__(*args,**kwargs)
def __call__(cls, *args, **kwargs): #cls = Foo
obj = cls.__new__(cls, *args, **kwargs)
obj.__init__(*args, **kwargs)
return obj
class Foo(metaclass=SingletonType):
def __init__(self,name):
self.name = name
def __new__(cls, *args, **kwargs):
return object.__new__(cls, *args, **kwargs)
'''
1、对象是类创建的,创建对象时类的__init__方法会自动执行,对象()执行类的__call__方法
2、类是type创建的,创建类时候type类的__init__方法会自动执行,类()会先执行type的__call__方法(调用类的__new__,__init__方法)
Foo 这个类是由SingletonType这个类创建的
'''
obj = Foo("hiayan")
# ============第三种方式实现单例模式=================
import threading
class SingletonType(type):
_instance_lock = threading.Lock()
def __call__(cls, *args, **kwargs):
if not hasattr(cls, "_instance"):
with SingletonType._instance_lock:
if not hasattr(cls, "_instance"):
cls._instance = super(SingletonType,cls).__call__(*args, **kwargs)
return cls._instance
class Foo(metaclass=SingletonType):
def __init__(self,name):
self.name = name
obj1 = Foo('name')
obj2 = Foo('name')
print(obj1,obj2)使用装饰器实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def wrapper(cls):
instance = {}
def inner(*args,**kwargs):
if cls not in instance:
instance[cls] = cls(*args,**kwargs)
return instance[cls]
return inner
class Singleton(object):
def __init__(self,name,age):
self.name = name
self.age = age
obj1 = Singleton('haiyan',22)
obj2 = Singleton('xx',22)
print(obj1)
print(obj2)
或者:
1
2
3
4
5
6
7
8
9
10class Scheduler:
__instance = None
def __new__(cls):
if cls.__instance is None:
cls.__instance = object.__new__(cls)
return cls.__instance
def __init__(self):
self.q = asyncio.Queue()
单例模式的应用
1 | # pool.py |
1 | # app.py |