Tornado入门到应用
简介
什么是Tornado : 全称 Tornado Web Server,是一种Web服务器软件的开源版本,是一个轻量级的Web框架
特点 : 作为Web服务器,拥有异步非阻塞O的处理方式,Tornado有较为出色的抗负载能力,官方用 nginx反向代理的方式部署 Tornado
使用场景 :
用户量大,高并发
大量的HTTP持久连接
- 使用同一个TCP连接来发送和接收多个HTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方法
- 对于HTTP1.0,可以在请求的包头(Header)中添加Connection:Keop-Aive=
- 对于HTTP11,所有的连接默认都是持久连接
C10K : 上面的高井发问题,通常用C10K这一概念来描述.
C10K —
Concurrently handling ten thousand connections,即并发10000个连接。对于单台服务器而言,根本无法承担,而采用多台服务器分布式又意味看高昂的成本性能 : Tornado在设计之初就考虑到了性能因素,旨在解决C10K问题,这样的设计使得其成为一个拥有非常高性能的解决方案(服务器与框架的集合体)
与Django的对比
- Django是走大而全的方向,注重的是高效开发,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台
- Django提供的方便,也意味着 Django内置的ORM跟框架内的其他模块耦合程度高,应用程序必须使用 Django内置的ORM,否则就不能享受到框架内提供的种种基于其ORM的便利.
- Django特性 :
- session功能
- 后台管理
- ORM
- Tornado : Tornado走的是少而精的方向,注重的是性能优越,它最出名的是异步非阻塞的设计方式
- 特点 :
- HTTP服务器
- 异步编程
- WebSockets
- 要性能,Tornado 首选;要开发速度,Django 和Flask 都行,区别是Flask 把许多功能交给第三方库去完成了,因此Flask 更为灵活。Django适合初学者或者小团队的快速开发,适合做管理类、博客类网站、或者功能十分复杂需求十分多的网站,Tornado适合高度定制,适合访问量大,异步情况多的网站。
基础流程
1 | # tornado的基础web框架模块 |
流程图示
- 首先生成一个监听客户端连接的socket , 一旦有新的连接过来就会生成一个新的socket
- linux-epoll会管理所有的socket
- IOLoop会监听linux-epoll中是否有IO操作
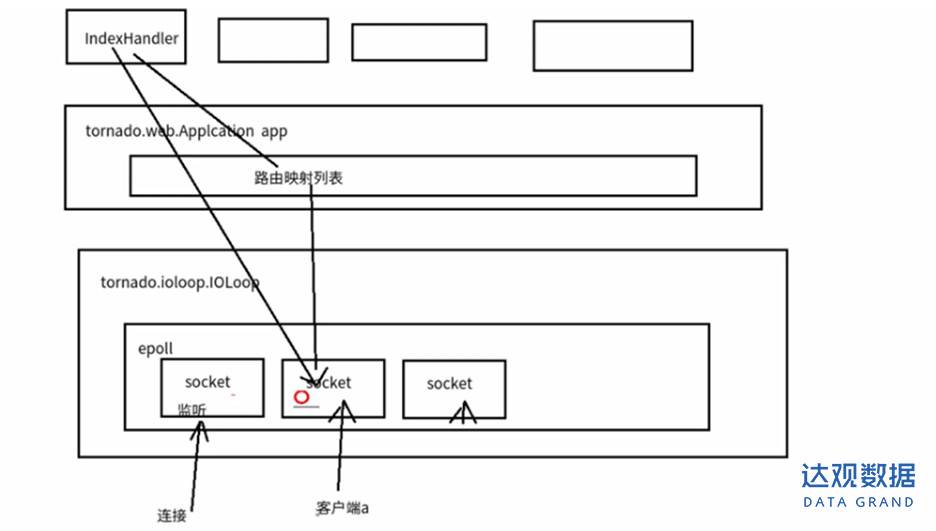
首先Tornado需要建立监听,会创建一个socket用于监听,如果有客户端A请求建立连接之后,Tornado会基于原先的socket新创建一个包含客户端A连接的有关信息的socket(分配新的监听端口),用于监听和客户端A的请求。此时对Tornado来说就有两个socket需要进行监控,原先的socket继续用来监听建立新连接,新的socket用于和客户端A进行通信,假如没有epoll技术的话,Tornado需要自己去循环询问哪个socket有新的请求。
有了epoll技术,Tornado只需要把所有的socket丢给epoll,epoll作为管家帮忙监控,然后Torando.ioloop.IOLoop.current().start()开启循环,不断的去询问epoll是否有请求需要处理,这就是ioloop所做的工作,也是Tornado的核心部分。
当有客户端进行请求,epoll就发现有socket可处理,当ioloop再次询问epoll时,epoll就把需要处理的socket交由Tornado处理
Tornado对请求进行处理,取出报文,从报文中获取请求路径,然后从tornado.web.Applcation里配置的路由映射中把请求路径映射成对应的处理类,如上图IndexHandler就是处理类。
处理类处理完成后,生成响应,将响应内容封装成http报文,通过请求时建立的连接(尚未中断)将响应内容返回给客户端。
当有多个请求同时发生,Tornado会按顺序挨个处理。
Tornado能同时处理大量连接的原因
- 利用高效的epoll技术处理请求,单线程/单进程同时处理大量连接。
- 没用使用传统的wsgi协议,而是利用Tornado自己的web框架和http服务形成了一整套WSGI方案进行处理。
- 异步处理方式,Tornado提供了异步接口可供调用。
创建HttpServer对象
其实app.listen(8000)会自动帮我们创建一个httpserver,此时我们可以自定义一个服务器:
1 | import tornado.web |
也就是说
等于
2
3
4
HttpServer = tornado.httpserver.HTTPServer(app)
# 绑定端口
HttpServer.listen(8000)
多进程
tordano服务默认启动是单进程
1 | import tornado.web |
HttpServer.bind(8000): 将服务绑定到指定的端口HttpServer.start(num):
- 默认为1
- 若num>0,创建num个子进程
- 若num<=0或者None : 开启对应硬件机器的cup核心数个子进程
也就是说:
相当于:
2
HttpServer.start(1)
app.listen()只能在单进程模式中使用虽然tornado给我们提供了一次性启动多个进程的方式,但是由于一些问题(见下),不建议使用上面方式启动多进程,而是手动启动多个进程,并且还能绑定不同的端囗
问题:
- 每个子进程都会从父进程中复制一份 IOLoop 的实例,如果在创建子进程前修改了 IOLoop,会影所有的子进程
- 所有的讲程都是由一个命令启动的,无法做到在不停止服劳的情况下修改代码(比如仅仅想修改某个进程的代码)
- 所有进程共享一个端囗,想要分别监控很困难
options
非正常结束 : 因为tornado需要占用端口号.如果tornado非正常结束 . 那么就有可能端口号没有被释放 .这时就要使用options
基础方法与属性:
tornado为我们提供了一个 tornado.options模块 .
作用 : 全局参数的定义,存储,转换tornado.options.define()方法: 功能 : 用来定义options选项变量的方法参数 name : 选项变量名,必须保证其唯一性
参数 default : 设置选项变量的赋认值,默认为None
参数 type : 设置选项变量的类型 , 从命令行或配置文件导入参数时tornado会根据类型输入值进行转换.
- 可以是str,float,int,datetime,timedelta
- 如果没有设置type , 会根据default的值进行转换
- 如果没有设置default , 那么就不进行转换
参数 multiple : 设置选项变量是否可以为多个值,吗默认false
参数 help : 选项变量的帮助信息
1
2tornado.options.define('port',default=8000,type=int)
tornado.options.define('list',default=[],type=str,multiple=True)tornado.options.options属性: 全局的 options对象,所有定义的选项变量都会作为该对象的属性获取参数的方法:
tornado.options.parse_command_line():作用 : 转换命令行参数,并保存到tornado.options.options
1
tornado.options.parse_command_line()
tornado.options.parse_config_file(path)
作用 : 从配置文件导入参数1
2# 查找config.py文件
tornado.options.parse_config_file('config.py')甚至直接使用config.py文件:
1
2
3
4
5
6
7
8
9# config.py
options = {
'post' : 8080,
'other_args':55
}
# server.py
from config import options
HttpServer.bind(config.options.port)
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28# server.py
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
# 定义一个hyl参数
tornado.options.define('hyl',default=8000,type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
self.write('hello world')
if __name__ == '__main__':
# 转换命令行参数,并保存到tornado.options.options
tornado.options.parse_command_line()
app = tornado.web.Application([
(r'/',IndexHandler)
])
HttpServer = tornado.httpserver.HTTPServer(app)
# 使用tornado.options.options
HttpServer.bind(tornado.options.options.hyl)
HttpServer.start(1)
tornado.ioloop.IOLoop.current().start()1
python server.py --hyl=9000
日志
当我们在代码中使用
parse_command_line()或者parse_config_file(path)方法是,tornado会默认开启logging模块功能,向屏幕终端输出打印信息关闭:
对于
parse_config_file(path):1
2
3# 这行一定要放在前面
tornado.options.options.logging = None
tornado.options.parse_command_line()对于
parse_command_line():1
python server.py --hyl=111 --logging=none
当然也可以在代码文件里写
tornado.options.options.logging = None
总结
目录结构:
1 | project |
1 | # main.py |
1 | # application.py |
1 | # views/index.py |
1 | # config.py |
1 | <!--index.html --> |
请求与响应
Application
settings
debug : 设置tornado在调试模式还是生成模式 , 默认Flase
调试模式:
自动重启 :
tornado应用会监控源代码文件,当有保存改动时便会重新启动服务器,可以减少手动重启的次数 . 如果保存后代码有错误会导致重启失败,修改惜误后需要手动重目(如果仅仅想启动此功能 , 可以使用
autoreload=True设置)取消缓存编译的模板
(如果仅仅想关闭此功能 , 可以使用compiled_tempate_cache=False设置)取消缓存静态文件的hash值
(如果仅仅想启动关闭此功能 , 可以使用static_hash_cache=False设置)提供追追信息
(如果仅仅想启动此功能 , 可以使用server_traceback=True设置)
static_path : 设置静态文件目录
template_path : 设置模板文件目录
autoescape : 关闭当前项目的自动转义
cookie_secret : 配置安全cookies密钥
xsrf_cookies : 当为True开启XSRF保护
login_url : 用户验证失败会映射该路由
1 | settings = { |
路由
简单使用
(r'/',views.index.IndexHandler)服务器自己传递的参数:
1
(r'/test',views.index.TestHandler,{'name':'hyl','age':21})
1
2
3
4
5
6
7
8
9# 使用initialize获取参数
class TestHandler(tornado.web.RequestHandler):
# 会在get方法前调用
def initialize(self,name,age):
self.name = name
self.age = age
def get(self,*args,**kwargs):
self.write(f'TestHandler...{self.name}...{self.age}')使用反向解析:
1
2
3
4
5
6# application.py
headlers = [
(r'/',views.index.IndexHandler),
# 使用tornado.web.url
tornado.web.url(r'/test2',views.index.TestHandler2,{'name':'hyl','age':21},name='test2'),
]1
2
3
4
5
6
7
8# views.py
class TestHandler2(tornado.web.RequestHandler):
def initialize(self,name,age):
self.name = name
self.age = age
def get(self,*args,**kwargs):
self.write(f'TestHandler2...{self.name}...{self.age}')使用反向解析:
1
2
3
4class IndexHandler(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
url = self.reverse_url('test2')
print('--------',url)
RequestHandler
利用Http协议向服务器递参数
提取url的特定部分
提取http://127.0.0.1:8000/shop/goods/pan中的goods/pan
位置参数
1
(r'/shop/(\w+)/(\w+)',views.index.Test3Handler)
1
2
3
4class TestHandler3(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
print('*****',args)
self.write('-------')当访问
http://127.0.0.1:8000/test3/shop/goods/pan时,print('*****',args)会返回goods和pan关键字参数
1
(r'/test3/shop/(?P<name>\w+)/(?P<age>\w+)',views.index.TestHandler3),
1
2
3
4class TestHandler3(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
print('*****',kwargs)
self.write('-------')当访问
http://127.0.0.1:8000/test3/shop/goods/pan时,print('*****',kwargs)会返回{'name': 'goods', 'age': 'pan'
get方式传递参数
提取http://127.0.0.1:8000/test4?a=1&b=2中的a,b
- Django中使用
x = request.GET.get('a',100) - tornado中使用
x = self.get_query_argument('a',default=100,strip=True) - 多了一个功能 , strip:去除左右两边的空白符(默认为True)
1 | (r'/test4',views.index.TestHandler4) |
1 | class TestHandler4(tornado.web.RequestHandler): |
http://127.0.0.1:8000/test4?a=4,返回4
- 对于像
http://127.0.0.1:8000/test4?a=4&a=5,默认self.get_query_argument获取最后一个, - 此时可以使用
x = self.get_query_arguments('a'),返回的x是一个list
post方式传递参数
- Django中使用
x = request.POST.get('a',100) - tornado中使用
self.get_body_argument('a',default=100,strip=True)
1 | (r'/',views.index.IndexHandler), |
1 | class IndexHandler(tornado.web.RequestHandler): |
1 | <form action="/" method="post"> |
同理 ,对于复选框,我们可以使用get_body_arguments()
既可以获取get请求,也可以获取post请求
- get为
x = self.get_requry_argument('a',default=100,strip=True) - post为
x = self.get_body_argument('a',default=100,strip=True) - 既可以获取get请求,也可以获取post请求使用
x = self.get_argument('a',default=100,strip=True) - 同理也有
self.get_arguments
在http报文的头中增加自定义的字段
1 | class TestHandler6(tornado.web.RequestHandler): |
request对象
和Django一样,request对象存储了关于请求的相关信息
属性:
- method : HTTP请求方式
- host : 被请求的主机名
- uri : 请求的权证资源地址 , 包括路径和get请求参数
http://www.baidu.com:8000/pan/goods/a.html?a=1&v=4#abc - path : 请求的路径部分
- query : 请求的参数部分
- version : 请求的HTTP部分
- headers : 请求头
- body : 请求踢
- remote_ip : 客户的IP
- files : 上传的文件
tornado.httputil.HTTPFile对象
- 功能 : 接受到的文件对象
- 属性 :
- filename : 文件实际名
- boby : 文件数据实体
- content_type : 文件类型
1 | (r'/test5',views.index.TestHandler5), |
1 | class TestHandler5(tornado.web.RequestHandler): |
1 | <form action="/test5" method="post" enctype="multipart/form-data"> |
上传hyl.txt,内容为hyl is sb. 得到
1 | {'file1': |
上传hyl.txt和B_1564.jpg,得到
1 | {'file1': |
响应
write
self.write(chunk): 将chunk数据写到缓冲区因为是写到缓冲区 , 所以可以使用多次的哦
self.write1
2
3
4
5
6class TestHandler6(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
self.write('1')
self.write('2')
self.write('3')
self.write('4')终端显示
1234self.finish(): 手动刷新缓冲区 , 关闭本次请求通道1
2
3
4
5
6class TestHandler6(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
self.write('1')
self.write('2')
self.finish()
self.write('3')终端只会显示
12使用
self.write()写json数据(Ajax)1
2
3
4
5
6
7
8import json
class TestHandler6(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
data = {
'name' : 'hyl',
'age' : 21
}
self.write(json.dumps(data))或者:
1
2
3
4
5
6
7class TestHandler6(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
data = {
'name' : 'hyl',
'age' : 21
}
self.write(data)区别:
- self.write(json.dumps(data))返回的数据的content_type为
text/html - self.write(data)返回的数据的content_type为
application/json
- self.write(json.dumps(data))返回的数据的content_type为
print刷新缓冲区的时机(刷新缓冲区就是将缓冲区的数据写到输出设备上) :
- 程序结束
- 手动刷新
- 缓冲区满了
- 遇到
\n
set_header(name,value)
手动没置一个名为name,值力value的响应头字段
1
self.set_header('Content-Type':'application/json;charset=UTF-8')
self.set_header可以自定义响应头1
self.set_header('name':'hyl')
set_default_headers(name,value)
在进入HTTP响应处理方法(get,post等)之前调用
set_default_headers(name,value), 可以重写该方法来预先设置默认的headers```python
class TestHandler6(tornado.web.RequestHandler):def set_default_headers(self): self.set_header('name','hyl') self.set_header('name1','hyl2') def get(self,*args,**kwargs): data = { 'name' : 'hyl', 'age' : 21 } self.write(data)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
- 对同一个header设置的话,后者会覆盖前者 : `self.set_header('name','hyl')`,`self.set_header('name','hyl2')`
### self.set_status(status_code,reason=None)
- 设置状态码
- 如果reason的值为None , 那么状态码必须设置为有效值
- 示例:
```python
class TestHandler6(tornado.web.RequestHandler):
def set_default_headers(self):
self.set_header('name','hyl')
def get(self,*args,**kwargs):
self.set_status(404)
data = {
'name' : 'hyl',
'age' : 21
}
self.write(data)1
2
3
4
5
6
7
8
9
10
11
12class TestHandler6(tornado.web.RequestHandler):
def set_default_headers(self):
self.set_header('name','hyl')
def get(self,*args,**kwargs):
# 999是非有效值 , 但是因为reason!=None,不会出错
self.set_status(999,'this is reason')
data = {
'name' : 'hyl',
'age' : 21
}
self.write(data)如果是
1
self.set_status(999)
则报错
重定向 rediret(url)
1 | class TestHandler6(tornado.web.RequestHandler): |
配合反向解析 :
1 | class TestHandler7(tornado.web.RequestHandler): |
self.send_error(status_code=500,**kwargs)
- 抛出HTTP错误状态码,默认是500,抛出错误后 tornado会词用 write_error方法进行处理,并返回给浏器错误界面
- 类似于Django自定义404页面
write_error(status_code,**kwargs)
用来处理 send_error抛出的错误信息,并返回给浏览器错误界面
1 | class TestHandler7(tornado.web.RequestHandler): |
接口调用顺序
1 | class TestHandler7(tornado.web.RequestHandler): |
RequestHandler的方法 :
initialize
prepare :
- 预处理方法,在执行对应的请求方法之前调用
- 任何一种HTTP请求都会执行 prepare 方法
HTTP方法 :
- get
- post
- head : 类似get请求,只不过响应中没有具体的内容,用户获取报头
- delete : 请求服务器删除指定的资源
- put : 从客户端向服务器传送指定内容
- patch : 请求修改局部内容
- options : 返回URL支持的所有HTTP方法
set_default_headers
write_error
on_finish : 在请求处理结束后调用,在该方法中进行资源的清理释放,或者是日志处理
尽量不要在该方法中进行响应输出
上述方法的执行顺序:
- 正常情况时:
- set_default_headers
- initialize
- prepare
- HTTP方法
- on_finish
- 抛出错误时:
- set_default_headers
- initialize
- prepare
- HTTP方法
- set_default_headers(第二次调用)
- write_error
- on_finish