shell基础
shell概述
Shell是什么
Shell是一个命令行解释器,它为用户提供了一个向 Linux 内核发送请求以便运行程序的界面系统级程序,用户可以用Shell启动、挂起、停止甚至是编写一些程序。
简单来说就是将类似于
ls的命令 , 转化01序列流程:
外层应用程序 –> shell命令解释器 –> 内核 –> 硬件
shell是一个功能相当强大的编程语言,易编写,易调试,灵活性较强.Shell是解释执行的脚本语言,在Shell中可以直接调用 Linux 系统命令。
Shell的分类
- Bourne Shell
- C Shell
Linux 支持的Shell
1 | more /etc/shells |
shell脚本的执行方式
echo输出命令
1 | echo [选项] [输出内容] |
-e : 开启转义
1 | echo -e "asasdasdasd asdasdasd" |
第一个脚本
创建脚本
1
vi hello.sh
hello.sh内容如下
1
2
3
4
5
#The first program
#Author: hyl
echo "hello world"#!/bin/bash不是注释 , 标志这个文件是shell脚本执行:
1
2
3
4
5# 赋予执行权限
chmod 755 hello.sh
# 执行命令
./hello.sh或者:
1
bash hello.sh
如果shell脚本是在window里写的 , 因为换行符不同 ,我们可以使用
dos2unix来解决1
2dos2unix hello.sh
bash hello.sh
Bash的基本功能
历史命令
history [选项] [历史命令保存文件]
选项:
- -c : 清空历史命令
- -w : 把缓存中的历史命令写入历史命令保存文件
./bash history
1 | history |
历史命令默认会保存1000条,
可以在环境变量配置文件/etc/profile中进行修改
使用上、下箭头调用以前的历史命令
使用
!n重复执行第n条历史命令使用
!!重复执行上一条命令使用
!字符串重复执行最后一条以该字串开头的命令
命令别名与常用快捷键
1 | alias 别名="原命令" |
示例:
1 | # 原命令vim , 别名vi |
命令执行顺序
- 第一顺位执行用绝对路径或相对路径执行的命令。
- 第二顺位执行别名。
- 第三顺位执行Bash的内部命令。
- 第四顺位执行按照$PATH环境变量定义的目录査找顺序找到的第一个命令
删除别名:
1 | unalias 别名 |
让别名永久生效:修改文件
1 | vi /root/.bashrc |
bash常用快捷键
- Ctrl+U : 剪切(可以当成删除使用)
- Ctrl +Y : 粘贴
- Ctrl+ R : 历史记录
输入输出重定向
标准输入输出
| 设备 | 设备文件名 | 文件描述符 | 缩写 | 描述 | |
|---|---|---|---|---|---|
| 键盘 | /dev/stdin | 0 | STDIN | 标准输入 | |
| 显示器 | /dev/sdtout | 1 | STDOUT | 标准输出 | |
| 显示器 | /dev/sdterr | 2 | STDERR | 标准错误输出 |
输出重定向
| 命令 | 说明 |
|---|---|
| command > file | 已覆盖的方式, 将输出重定向到 file。 |
| command < file | 已覆盖的方式,将输入重定向到 file。 |
| command >> file | 将输出以追加的方式重定向到 file。 |
| n > file | 将文件描述符为 n 的文件重定向到 file。 |
| n >> file | 将文件描述符为 n 的文件以追加的方式重定向到 file。 |
| n >& m | 将输出文件 m 和 n 合并。 |
| n <& m | 将输入文件 m 和 n 合并。 |
| << tag | 将开始标记 tag 和结束标记 tag 之间的内容作为输入。 |
对于报错信息 , 我们需要使用
2重定向错误信息
2
lssst 2>> file1注意
2和>>之间没有空格
不管对错都重定向到file1
2
3
4
5
6
# 覆盖
lssssst &> file1
# 追加
lssssst &>> file1正确追加到文件1 , 错误追加到文件2
输入重定向
比如某些命令需要参数 , 我们就可以将参数存储到文件中,使用输入重定向传参
1 | wc [选项] [文件名] |
选项:
- -c 统计字节数
- -w 统计单词数
- -l 统计行数
1 | wc < python.cfg |
多命令顺序执行与管道符
多命令顺序执行
- ; 分号,没有任何逻辑关系的连接符。当多个命令用分号连接时,各命令之间的执行成功与否彼此没有任何影响,都会一条一条执行下去。
- || 逻辑或,当用此连接符连接多个命令时,前面的命令执行成功,则后面的命令不会执行。前面的命令执行失败,后面的命令才会执行。
- && 逻辑与,当用此连接符连接多个命令时,前面的命令执行成功,才会执行后面的命令,前面的命令执行失败,后面的命令不会执行,与 || 正好相反。
- | 管道符,当用此连接符连接多个命令时,前面命令执行的正确输出,会交给后面的命令继续处理。若前面的命令执行失败,则会报错,若后面的命令无法处理前面命令的输出,也会报错。
1 | # 判断命令是否正常运行 |
通配符与其他特殊符号
? : 匹配一个字符
* : 匹配0到多个字符
Bash中其他特殊符号
| 符号 | 作用 |
|---|---|
单引号'' |
在单引号中所有的特殊符号都没有特殊含义。 |
双引号"" |
1. 在双引号中特殊符号都没有特殊含义, 2. 但是$、`、\是例外,分别代表 调用变量的值、引用命令和转义符的特殊含义 |
| 反引号 ` | 1. 反引号。反引号括起来的内容是系统命令,在Bash中会先执行 2. 它和 $()作用一样,不过推荐使用$(),因为反引号非常容易看错。 |
$() |
和反引号作用一样,用来引用系统命令 |
井号# |
注释 |
$ |
用于调用变量的值,如需要调用变量name的值时,需要用$name的方式得到变量的值。 |
反斜线\ |
转义符 |
1 | name=sc |
Bash的变量
- 用户自定义变量
- 环境变量:这种变量中主要保存的是和系统操作环境相关的数据。
- 位置参数变量:这种变量主要是用来向脚本当中传递参数或数据的,变量名不能自定义,变量作用是固定的。
- 预定义变量:是Bash中已经定义好的变量,变量名不能自定义,变量作用也是固定的。
在Bash中,变量的默认类型都是字符串型,如果要进行数值运算,则必须指定变量类型为数值型。
变量赋值的时候等号左右不能有空格 ,
1
2
3
4
5
6# right
name=hyl
name='he ying liang'
# wrong
name = hyl
用户自定义变量
- 变量的叠加 :
"$变量名"或者${变量名} set查看全部的变量unset name: 删除变量
1 | aa=123 |
环境变量
用户自定义变量只在当前的She中生效,而环境变量会在当前Shell和这个Shell所有子Shell中生效。如果把环境变量写入相应的配置文件,那么这个环境变量就会在所有的Shell生效
环境变量和自定义变量的本质区别就是 : 作用域不同
- 自定义变量只在当前shell中生效
- 环境变量在子shell中生效
- 如果把环境变量写入配置文件,那么就会在所有shell中生效
环境变量名建议大写,便于区分
设置环境变量
1
2
3
4
5
6
7
8export 变量名=变量值
# 声明变量
env
# 查询变量
unset 变量名
# 删除变量
示例:
1 | name=hyl |
系统常见环境变量
PATH : 系统查找命令的路径
1
2
3
4
5
6
7echo $PATH
# /usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
# 使用冒号分割
PATH=" $PATH":/root/sh
# PATH变量叠加
# 临时改变 , 重启就失效PS1 : 定义系统提示符的变量
1
2
3echo $PS1
# [\u@\h \W]\$
# 对应[root@li1596-233 ~]
位置参数变量
变量名称和变量作用都不能更改
| 位置参数变量 | 作用 |
|---|---|
| $1, $2, …: | 对应第1、第2等参数,shift [n]换位置 |
$n |
n为数字,$0代表命令本身,$1-$9代表第一到第九个参数,十以上的参数需要用大括号包含,如${10} |
$* |
这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体 |
$@ |
这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待 |
$# |
这个变量代表命令行中所有参数的个数 |
示例:
1 | vim script.sh |
预定义变量
位置参数变量就是特殊的预定义变量
| 预定义变量 | 作用 |
|---|---|
$? |
最后一次执行的命令的返回状态。 1. 如果这个变量的值为0,证明上一个命令正确执行; 2. 如果这个变量的值为非0,则证明上一个命令执行不正确 3. 不同的错误有不同的错误码 |
$$ |
当前进程的进程号(P ID) |
$! |
后台运行的最后一个进程的进程号(PID) |
1 | # 正确执行 |
||和&&的惰性运算 , 其实就是依赖于echo $?
1 | echo $$ |
接受键盘输入
1 | read [选项] [变量名] |
选项:
-p “提示信息”:在等待read输入时,输出提示信息-t 秒数:read命令会一直等待用户输入,使用此选项可以指定等待时间-n 字符数:read命令只接受指定的字符数,就会执行本来输入后回车 , 程序才会运行.现在你只要输入字符长度大于某个值 , 程序就会自动运行
-s: 隐藏输入的数据,适用于机密信息的输入
示例:
1 | # 提示“请输入姓名”并等30秒,把用户的输入保存入变量nme中 |
Bash的运算符
Bash的默认数据类型是字符串
数值运算与运算符
1 | a=11 |
declare 声明变量类型:
1 | declare [+-] [选项] 变量名 |
选项:
-: 给变量设定类型属性+: 取消变量的类型属性-i: 将变量声明为整数型(Integer)-x: 将变量声明为环境变量-p: 显示指定变量的被声明的类型
1 | declare -p a |
1 | aa=11 |
expr或let数值运算工具
1 | aa=11 |
1 | a=11 |
"$((运算式))"或"$[运算式]"
1 | aa=11 |
变量测试与内容替换
| 变量置换方式 | 变量y没有设置 | 变量y为空值 | 变量y设置值 |
|---|---|---|---|
| x=${y-新值} | x= 新值 | x 为空 | x=$y |
| x=${y:-新值} | x= 新值 | x= 新值 | x=$y |
| x=${y+新值} | x 为空 | x= 新值 | x=新值 |
| x=${y:+新值} | x 为空 | x 为空 | x=新值 |
| x=${y=新值} | x= 新值 | x 为空 | x=$y |
| y= 新值 | y 值不变 | y值不变 | |
| x=${y:=新值} | x= 新值 | X= 新值 | x=$y |
| y= 新值 | y= 新值 | y值不变 | |
| x=${y?新值} | 新值输出到标准错误输出(屏幕) | x 为空 | x=$y |
| x=${y:?新值} | 新值输出到标准错误输出 | 新值输出到标准错误输出 | x=$y |
1 | unset y |
环境变量配置文件
配置文件的读取顺序 :
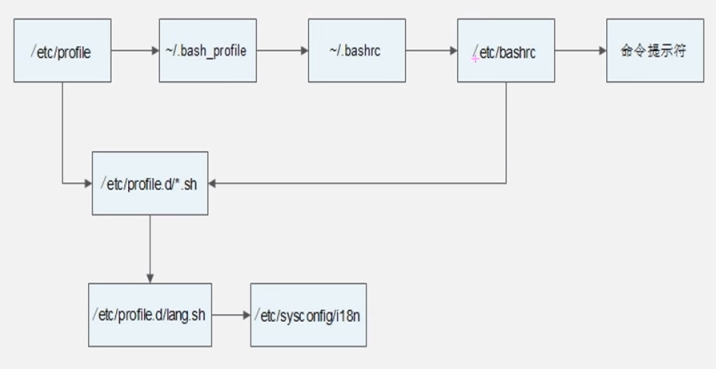
虽然 /etc/profile 和 /etc/bashrc 都调用了 /etc/profile.d/*.sh .
/etc/profile定义的是需要使用登录密码后才能使用的shell ./etc/bashrc定义的是不需要使用登录密码后才能使用的shell
环境变量配置文件简介
环境变量配置文件中主要是定义对系统的操作环境生效的系统默认环境变量,比如PATH、HISTSIZE、PS1、HOSTNAME等默认环境变量。
source命令
本来修改环境变量要在重启后才生效,现在强制性让配置文件直接生效1
2
3source 配置文件
# 或者(.和配置文件中间有括号)(. 就是source的缩写)
. 配置文件主要的环境变量配置文件:
- /etc/profile
- /etc/profile.d/*.sh
- ~/.bash_profile
- ~/.bashrc
- /etc/bashrc
环境变量配置文件作用
/etc/profile的作用
- USER变量
- LOGNAME变量
- MAIL变量
- PATH变量
- HOSTNAME变量
- HISTSIZE变量
- umask
- 调用/etc/profile.d/*.sh文件
~/.bash_profile的作用
- 调用了~/.bashrc文件。
- 在PATH变量后面加入了
:$HOME/bin这个目录
/etc/.bashrc的作用
- PS1变量
- umask
- PATH变量
- 调用/etc/profile.d/*.sh文件
其他配置文件和登录信息
~/.bash_logout: 注销时生效的环境变量配置文件就是说当用户注销时,就会执行的该文件
~/bash_history: 存放使用过的命令/etc/issue: 本地终端欢迎信息/etc/issue.net: 远程终端欢迎信息/etc/motd: 不管是本地登录,还是远程登录,都可以显示此欢迎信息
Shell中的正则表达式
- shell中正则为
包含匹配, shell中通配符是完全匹配 - shell中的正则是在文件中匹配字符串的 , shell中的通配符是用来匹配符合条件的文件名
- ls , find , cp 这些命令不支持正则 . 仅支持shell的通配符
shell中的正则某些命令要加反斜杠
\{n\}: 前一个字符恰好出现n次1
2[1][3-8][0-9]\{9\}
# 匹配手机号码\{n,\}\{n,m\}
字符截取命令
cut字段提取命令
提取列
```bash
cut [选项] 文件名1
2
3
4
5
6
7
8
9
10
11
12
13
- 选项:
- -f 列号 : 提取第几列
- -d 分隔符 : 按照指定分隔符分割列
- 示例:
```bash
cut -d ":" -f 1,3 test.txt
# 分割符为: , 获取1和3列
cat test.txt | grep 100 | grep -v hyl | cut -f 2
#包含100,不包含hyl , 截取第2列1
2
3
4
5
6
7
8
9
10
11cat test.txt
# id name score
# 1 hyl 96
# 2 dsz 100
# 3 gzr 120
$ cut -f 2 test.txt
# name
# hyl
# dsz
# gzr
printf命令
格式化输出
```bash
printf ‘输出类型输出格式’ 输出内容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
- 输出类型:
- `%ns` : 输出**字符串**,n是数字指代输出几个字符
- `%ni` : 输出**整数**,n是数字指代输出几个数字
- `%m.nf` : 输出**浮点数**,m和n是数字,指代输出的整数位数和小数位数。如`%8.2f`代表共输出8位数其中2位是小数,6位是整数。
- 输出格式:
- `\n` : 换行
- `\r` : 回车,也就是 Enter键
- `\t` : 水平输出退格键,也就是Tab键
- 示例:
```bash
printf %s 1 2 3 4 5 6
# 123456
printf %s %s %s 1 2 3 4 5 6
# %s%s123456
printf '%s %s %s' 1 2 3 4 5 6
# 1 2 34 5 6
printf '%s %s %s\n' 1 2 3 4 5 6
# 1 2 3
# 4 5 6
awk命令
比起cut命令更加全能的截取列的命令
在awk命令的输出中支持print和printf命令
- print:print会在每个输出之后自动加入一个换行符(Linux默认没有print命令)
- printf:printf是标准格式输岀命令,并不会自动加入换行符,如果需要换行,需要手工加入换行符
```bash
awk ‘条件1 {动作1} 条件2 {动作2}…’ 文件名如果条件1符合,执行动作1,条件2符合,执行动作2
1
2
3
4
5
6
7
8
- 示例:
```bash
awk '{printf $2 "\t" $6 "\n"}' student.txt
# 不用条件,全部都执行
cat student.txt | grep -v Name | awk '$6>=87 {printf $2 "\n"}'1
2
3
4
5
6
7
8
9
10
11cat test.txt
# id name score
# 1 hyl 96
# 2 dsz 100
# 3 gzr 120
awk '{printf $2 "\t" $3 "\n"}' test.txt
# name score
# hyl 96
# dsz 100
# gzr 120awk首先读入一行数据 , 然后赋值 , $2代表第二行 ,$0代表一整行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17df -h
# Filesystem Size Used Avail Use% Mounted on
# C:/Program Files/Git 111G 80G 31G 73% /
# D: 100G 99G 1.8G 99% /d
# F: 235G 183G 53G 78% /f
df -h | awk '{printf $3 "\n"}'
# Used
# 111G
# 99G
# 183G
df -h | awk '{print $3}'
# Used
# 111G
# 99G
# 183Gprint命令只能用于awk命令内部
BEGIN : 在读取数据之前先执行某些语句
1
2
3
4
5
6
7
8
9
10
11
12
13awk 'BEGIN{print "test!!"} {print $2 "\t" $3}' test.txt
# test!!
# name score
# hyl 96
# dsz 100
# gzr 120t
# 指定分隔符
awk '{FS=" "} {print $1 "\t" $3}' test.txt
# id score
# 1 96
# 2 100
# 3 120awk首先读入第一行数据 , 然后赋值 , 所以我们可以使用begin
1
2
3
4
5
6
7
8
9
10
11
12
13# 先扫描第一行, 然后设置分隔符
awk '{FS=":"} {print $1 "\t" $2}' xxx.txt
# id:name:score
# 1 hyl
# 2 dsz
# 3 gzr
# 在扫描之前就设置分隔符
awk 'BEGIN{FS=":"} {print $1 "\t" $2}' xxx.txt
# id name
# 1 hyl
# 2 dsz
# 3 gzr同理 , 还有END
1
awk 'BEGIN{print "test!!"}END {printf "The End \n"} {print $2 }' xxx.txt
sed命令
sed是一种几乎包括在所有UNIX平台(包括 Linux)的轻量级流编辑器.
sed主要是用来将数据进行选取、替换、删除、新增的命令。
简单来说 ,sed就像是vim , 但是vim只能修改文件 , 而sed可以修改命令返回的数据
```bash
sed [选项] ‘[动作]’ 文件名1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
- 选项:
- `-n` : **一般sed命令会把所有数据都输出到屏幕**,如果加入此选择,则只会把经过sed命令处理的行输出到屏幕。
- `-e` : 允许对输入数据应用多条sed命令编辑
- `-i` : 用sed的修改结果**直接修改读取数据的文件**,而不是由屏幕输出
- 动作:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
- 示例:
```bash
cat xxx.txt
# id:name:score
# 1:hyl:96
# 2:dsz:100
# 3:gzr:120
sed -n '2p' xxx.txt
# 1:hyl:96
df -h
# Filesystem Size Used Avail Use% Mounted on
# C:/Program Files/Git 111G 80G 31G 73% /
# D: 100G 99G 1.8G 99% /d
# F: 235G 185G 50G 79% /f
df -h | sed -n '2p'
# C:/Program Files/Git 111G 80G 31G 73% /
sed '1,3d' xxx.txt
# 3:gzr:120
# 删除第一行到第三行的数据(并不修改文件本身)
# 在第2行新增 ----------
sed '2a ----------' xxx.txt
# id:name:score
# 1:hyl:96
# ----------
# 2:dsz:100
# 3:gzr:120字符串替换:
1
sed 's/旧字串/新字串/g' 文件名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18cat xxx.txt
id:name:score
# 1:hyl:96
# 2:dsz:100
# 3:gzr:120
sed 's/gzr/XXX/g' xxx.txt
# id:name:score
# 1:hyl:96
# 2:dsz:100
# 3:XXX:120
# 把第4行的120替换成999
sed '4s/120/999/g' xxx.txt
# id:name:score
# 1:hyl:96
# 2:dsz:100
# 3:gzr:999
字符处理命令
排序命令sort
1 | sort [选项] 文件名 |
选项:
-f: 忽略大小写-n: 以数值型进行排序,默认使用字符串型排序-r: 反向排序-t: 指定分隔符,默认是分隔符是制表符-k n[,m]: 按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)
1 | sort xxx.txt |
wc
统计命令
1 | wc [选项] 文件名 |
选项:
-l: 只统计行数-w: 只统计单词数-m: 只统计字符数
1 | wc xxx.txt |
条件判断
单个文件的判断
-d 文件:判断该文件是否存在,并且是否为目录文件(是目录为真)-e 文件: 判断该文件是否存在(存在为真)-f 文件: 判断该文件是否存在,并且是否为普通文件(是普通文件为真)-L 文件: 判断该文件是否存在,并且是否为符号链接文件(是符号链接文件为真)-r 文件: 判断该文件是否存在,并且是否该文件拥有读权限(有读权限为真)-w 文件: 判断该文件是否存在,并且是否该文件拥有写权限(有写权限为真)-x 文件: 判断该文件是否存在,并且是否该文件拥有执行权限(有执行权限为真)
rwx: 所有人,所属组,其他人三者只要有人有权限 ,即为真
1 | test -e xxx.txt |
示例:
1 | test -e xxx.txt |
两个文件之间进行比较
文件1 -nt 文件2: nt(new then) , 判断文件1的修改时间是否比文件2的新(如果新则为真)文件1 -ot 文件2: ot(old then) , 判断文件1的修改时间是否比文件2的旧(如果旧则为真)文件1 -ef 文件2: ef(equal file) , 判断文件1是否和文件2的inode号一致,可以理解为两个文件是否为同一个文件。这个判断用于判断硬链接是很好的方法
1 | [ xxx.txt -ef hyl.txt ] && echo "yes" || echo "no" |
两个整数之间进行比较
-eq-ne-gt-lt-ge-le
1 | [ 22 -gt 33 ] && echo "yes" || echo "no" |
字符串的判断
-z 字符串: 判断字符串是否为空(为空返回真)-n 字符串: 判断字符串是否为非空(非空返回真字串1==字串2:判断字符串1是否和字符串2相等字串1!=字串2: 判断字符串1是否和字符串2不相等(不相等返回真
1 | name=hyl |
多重条件判断
判断1 -a 判断2: 与判断1 -o 判断2: 或!判断: 非
1 | [ 22 -gt 33 -a 55 -lt 23 ] && echo "yes" || echo "no" |
流程控制
if
1 | if [ 条件 ] |
1 | # 判断分区使用率 |
case
case语句和if….elif….else语句一样都是多分支条件语句,
不过和if多分支条件语气不同的是,case语句只能判断一种条件关系,而i语句可以判断多种条件关系。
```bash
case $变量名 in"值1") ;; "值2") ;; *) ;;esac
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 示例:
```bash
read -p "Pleace choose yes/no: " -t 30 cho
case $cho in
"yes")
echo "Your choose is Yes"
;;
"no")
echo "Your choose is no"
;;
*)
echo "Your choose is error"
;;
esac
for
语法一 :
1 | for 变量 in 值1 值2 值3... |
示例:
1 | for time in moring noon afternoon evening |
1 | # 批量解压缩 |
语法二 :
1 | for (( 初始值; 循环控制条件; 变量变化)) |
示例:
1 | s=0 |
while循环和until
1 | while [ 条件判断式 ] |
1 | i=1 |
1 | i=1 |