谈谈你对http协议的认识
HTTP协议本质:通过\r\n分割的规范 + 请求响应之后断开链接
具体:
- Http协议是建立在tcp之上的,是一种规范,它规范定了发送的数据的数据格式
- 然而这个数据格式是通过
\r\n进行分割的,请求头与请求体也是通过2个\r\n分割的,响应的时候,响应头与响应体也是通过\r\n分割, - 并且还规定已请求已响应就会断开链接 : 短连接、无状态
整个HTTP流程: 流程:
域名解析
tcp3次握手建立连接
发起http请求
服务器端响应http请求,浏览器得到到http请求的内容
浏览器解析html代码,并请求html代码中的资源
浏览器对页面进行渲染,展现在用户面前
域名解析检查顺序
- 浏览器自身DNS缓存
- OS自身的DNS缓存
- 读取host文件
- 本地域名服务器
- 权限域名服务器
- 根域名服务器
如果有且没有过期,则结束本次域名解析。域名解析成功之后,进行后续操作
谈谈你对websocket协议的认识
- WebSocket是HTML5开始提供的一种浏览器与服务器间进行
全双工通讯的网络技术。 - 依靠这种技术可以实现客户端和服务器端的
长连接,双向实时通信。 - 特点:
- 事件驱动,异步
- 使用ws或者wss协议的客户端socket能够实现真正意义上的推送功能
- 缺点:
少部分浏览器不支持,浏览器支持的程度与方式有区别。
什么是magic string
客户端向服务端发送消息时,会有一个sec-websocket-key和magic string的随机字符串(魔法字符串)
服务端接收到消息后会把他们连接成一个新的key串,进行编码、加密,确保信息的安全性
简述jsonp及实现原理?
- JSONP是json用来跨域的一个东西。
- 原理是通过script标签的跨域特性来绕过同源策略。(创建一个回调函数,然后在远程服务上调用这个函数并且将json数据形式作为参数传递,完成回调)。
什么是cors ?
跨域资源共享(CORS,Cross-Origin Resource Sharing),其本质是设置响应头,使得浏览器允许跨域请求。
浏览器将CORS请求分成两类:简单请求和复杂请求
简单请求(同时满足以下两大条件)
- 请求方法是以下三种方法之一:
HEAD
GET
POST- HTTP的头信息不超出以下几种字段:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type :只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain凡是不同时满足上面两个条件,就属于非简单请求
列举Http请求中的状态码?
分类:
1** 信息,服务器收到请求,需要请求者继续执行操作
2** 成功,操作被成功接收并处理
3** 重定向,需要进一步的操作以完成请求
4** 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在处理请求的过程中发生了错误
常见的状态码
200 -请求成功
202 -已接受请求,尚未处理
204 -请求成功,且不需返回内容
301 - 资源(网页等)被永久转移到其他url
400 - 请求的语义或是参数有错
403 - 服务器拒绝请求
404 - 请求资源(网页)不存在
500 - 内部服务器错误
502 - 网关错误,一般是服务器压力过大导致连接超时
503 - 由于超载或系统维护,服务器暂时的无法处理客户端的请求。
列举Http请求中常见的请求头?
- user-agent
- host
- referer
- cookie
- content-type
Django
django、flask、tornado框架的比较?
- d:大而全
- f:微型灵活
- t:异步非阻塞
Flask 和 Django 路由映射的区别
- 在django中,路由是浏览器访问服务器时,先访问的项目中的url,再由项目中的url找到应用中url,这些url是放在一个列表里,遵从从前往后匹配的规则。
- 在flask中,路由是通过装饰器给每个视图函数提供的,而且根据请求方式的不同可以一个url用于不同的作用。
什么是wsgi,uwsgi,uWSGI
- WSGI:
web服务器网关接口,是一套协议。在web服务和web应用之间的协议规范,用于接收用户请求并将请求进行初次封装,然后将请求交给web框架。- wsgiref:实现wsgi协议的模块,本质上就是一个socket服务端,用于接收用户请求(用于django)
- werkzeug,和wsgiref一样,都是实现wsgi协议的模块。本质上就是编写一个socket服务端,用于接收用户请求(用于flask)
- tornado,和wsgiref一样,都是实现wsgi协议的模块。(用于tornado)
- uWSGI:
是一个web服务器,实现了WSGI的协议,uWSGI协议,http协议 - uwsgi:
与WSGI一样是一种通信协议,它是uWSGI服务器的独占协议,用于定义传输信息的类型。
什么是wsgi?
Web服务器网关接口(Web Server Gateway Interface,缩写为WSGI)
是Python应用程序或框架和Web服务器之间的一种接口,已经被广泛接受, 它已基本达成它的可移植性方面的目标。
通过以下模块实现了wsgi协议:
wsgiref
werkzurg
uwsgi 关于部署
以上模块本质:
编写socket服务端,用于监听请求,当有请求到来,则将请求数据进行封装,然后交给web框架处理。
CORS 和 CSRF的区别
CORS是一个W3C标准,全称是
跨域资源共享(Cross-origin resoure sharing).
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。CSRF, Cross Site Request Forgery,
跨站点伪造请求。
某些恶意网站包含链接,表单,按钮,js利用登录用户在浏览器中认证,从而攻击服务器.跨站请求伪造,你在某不安全的论坛上看到一张图片:
1
<img src="http://bank.com/withdraw?account=bob&amount=100&for=mallory">
浏览器为了显示图片,会向bank.example.com发起get请求。这是你银行的域名,并且get后面带了转账等信息,跨域请求时附带的是接口所属域名下的cookie,意味着你之前在银行的登录态也会带上。这样,银行主机收到请求,误以为你在执行转账操作,并且登录态校验通过,黑客就把你的钱转走了。
CSRF主流防御方式是在后端生成表单的时候生成一串随机token,内置到表单里成为一个字段,同时,将此串token置入session中。每次表单提交到后端时都会检查这两个值是否一致,以此来判断此次表单提交是否是可信的,提交过一次之后,如果这个页面没有生成CSRF token,那么token将会被清空,如果有新的需求,那么token会被更新。
攻击者可以伪造POST表单提交,但是他没有后端生成的内置于表单的token,session中没有token都无济于事。
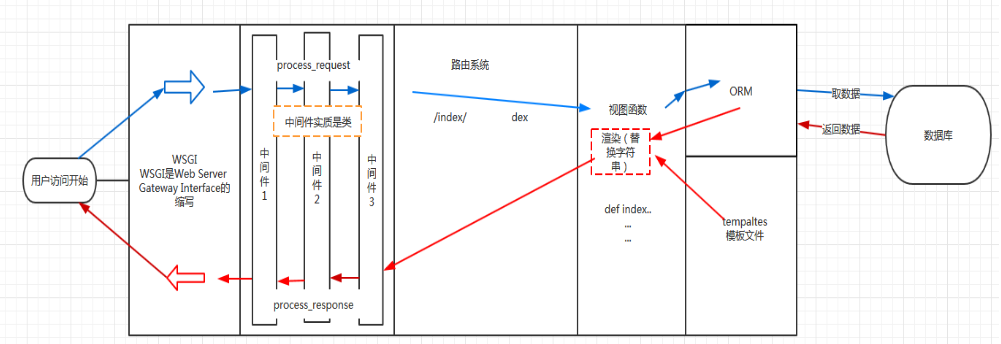
简述Django请求生命周期
- wsgi ,请求封装后交给web框架(Flask,Django)
- 中间件,对请求进行校验或在请求对象中添加其他相关数据,例如:csrf,request.session
- 路由匹配 根据浏览器发送的不同url去匹配不同的视图函数
- 视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm,templates
- 中间件,对响应的数据进行处理
- wsgi,将响应的内容发送给浏览器
Django的存缓
常用的数据放在缓存里面,就不用走视图函数,
请求进来通过所有的process_request,会到缓存里面查数据,有就直接拿,没有就走视图函数
关键点:
- 执行完所有的process_request才去缓存取数据
- 执行完所有的process_response才将数据放到缓存
为什么放在最后一个process_request才去缓存?
因为需要验证完用户的请求,才能返回数据
列举django中间件的5个方法?以及django中间件的应用场景?
- process_request(self,request) 先走request 通过路由匹配返回
- process_view(self, request, callback, callback_args, callback_kwargs) 再返回执行view
- process_template_response(self,request,response) 当视图函数的返回值
- process_exception(self, request, exception) 如果程序报错执行process_exception
- process_response(self, request, response) 当视图函数的返回值对象中有render方法时,该方法才会被调用
auto_now_add和auto_now的区别?
- auto_now_add和auto_now是互斥的.他们不会同时出现在同一个字段.(废话,一个是创建时间,一个是修改时间.)
- auto_now : 每次保存对象时,自动设置该字段为当前时间,一般用于
最后一次修改的时间戳 - auto_now_add : 当对象第一次被创建时自动设置当前时间,用于创建的时间戳,他总是使用当前日期
简述什么是FBV和CBV?
- FBV方式请求的过程
用户发送url请求,Django会依次遍历路由映射表中的所有记录,一旦路由映射表其中的一条匹配成功了,就执行视图函数中对应的函数名,这是fbv的执行流程 - CBV方式请求的过程
当服务端使用CBV模式的时候,用户发给服务端的请求包含url和method,这两个信息都是字符串类型,服务端通过路由映射表匹配成功后会自动去找dispatch方法,然后Django会通过dispatch反射的方式找到类中对应的方法并执行类中的方法执行完毕之后,会把客户端想要的数据返回给dispatch方法,由dispatch方法把数据返回经客户端 - FBV和CBV的区别?
- 没什么区别,因为他们的本质都是函数。CBV的.as_view()返回的view函数,view函数中调用类的dispatch方法,在dispatch方法中通过反射执行get/post/delete/put等方法。
- CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
django的request对象是在什么时候创建的?
- 当请求一个页面时, Django会建立一个包含请求元数据的 HttpRequest 对象.
- 当Django 加载对应的视图时, HttpRequest对象将作为视图函数的第一个参数. 每个视图会返回一个HttpResponse对象.
如何给CBV的程序添加装饰器?
加在dispath前面
1
2
3
4class UserView(View):
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')加载CBV前面
1
2
3
4# name---> 指定名字
class UserView(View):
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
列举django orm 中所有的方法(QuerySet对象的所有方法)
- 返回QuerySet对象的方法有:
all()
filter()
exclude()
order_by()
reverse()
distinct() - 特殊的QuerySet:
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元组序列 - 返回具体对象的:
get()
first()
last() - 返回布尔值的方法有:
exists() - 返回数字的方法有:
count()
only和defer的区别?
- only : 仅取某个表中的数据
- defer : 映射中排除某列数据
filter和exclude的区别?
- 条件查询符合条件
- 条件查询排除条件
- 两个条件的参数可以是:参数,字典,Q
values和values_list的区别?
- values获取每行数据为字典格式
- values_list获取每行数据为元祖
select_related和prefetch_related的区别?
- select_related主要针
一对一和多对一关系进行优化,通过多表join关联查询,一次性获得所有数据,存放在内存中,但如果关联的表太多,会严重影响数据库性能。 - prefetch_related是通过分表,先获取各个表的数据,存放在内存中,然后通过Python处理他们之间的关联。
列举django orm中三种能写sql语句的方法。
- 使用execute执行自定义SQL
- 使用extra方法
- 使用raw方法
F和Q的作用?
F:主要用来
使用模型的A属性与B属性进行比较和获取原数据进行计算。F表达式常用来执行数据库层面的计算,从而避免出现竞争状态.
简单来说 : F()对象代表一个模型字段的值或注释列
Q:用来进行复杂查询
如何使用django orm批量创建数据?
bulk_create函数
1 | objs = [ |
django的Form和ModeForm的作用?
- 作用:
- 对用户请求数据格式进行校验
- 自动生成HTML标签
- 区别:
- Form,字段需要自己手写。
- ModelForm,可以通过Meta进行定义
django中csrf的实现机制?
- Django预防CSRF攻击的方法是在用户提交的表单中加入一个csrftoken的隐含值,这个值和服务器中保存的csrftoken的值相同,这样做的原理如下:
- 在用户访问django的可信站点时,django反馈给用户的表单中有一个隐含字段csrftoken,这个值是在服务器端随机生成的,每一次提交表单都会生成不同的值
- 当用户提交django的表单时,服务器校验这个表单的csrftoken是否和自己保存的一致,来判断用户的合法性
- 当用户被csrf攻击从其他站点发送精心编制的攻击请求时,由于其他站点不可能知道隐藏的csrftoken字段的信息,这样在服务器端就会校验失败,攻击被成功防御
基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
给每个ajax都加上上请求头
1
2
3
4
5
6
7
8
9
10
11function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
data:{csrfmiddlewaretoken:'{{ csrf_token }}',name:'alex'}
success:function(data){
console.log(data);
}
});
}去cookie中获取token
1
2
3
4
5
6
7
8
9
10
11
12
13function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
headers:{
'X-CSRFToken':$.cookie('csrftoken') // 去cookie中获取
},
success:function(data){
console.log(data);
}
});
}
django中如何实现orm表中添加数据时创建一条日志记录
1 | LOGGING = { |
django缓存如何设置?
三种粒度缓存
中间件级别
1
2
3
4
5
6# 全站缓存(中间件)
MIDDLEWARE_CLASSES = (
'django.middleware.cache.UpdateCacheMiddleware', #第一
'django.middleware.common.CommonMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware', #最后
)视图级别
1
2
3
4
5from django.views.decorators.cache import cache_page
# 超时时间为15秒
def index(request):
pass局部缓存
1
2
3
4
5
6{# 模板缓存#}
{% load cache %}
<h3 style="color: green">不缓存:-----{{ t }}</h3>
{% cache 2 'name' %} # 存的key
<h3>缓存:-----:{{ t }}</h3>
{% endcache %}
django的缓存能使用redis吗?如果可以的话,如何配置?
1 | pip install django-redis |
然后在settings.py 里面添加
1 | CACHES = { |
django路由系统中name的作用?
反向解析路由字符串
1 | url(r'^home', views.home, name='home') |
django的模板中filter和simple_tag的区别?
- filter : 类似管道,只能接受两个参数第一个参数是|前的数据
- simple_tag : 类似函数
- 模板继承:{ % extends ‘layouts.html’ %}
- 自定义方法
- ‘filter’:只能传递两个参数,可以在if、for语句中使用
- ‘simple_tag’:可以无线传参,不能在if for中使用
- ‘inclusion_tags’:可以使用模板和后端数据
- 防xss攻击: ‘|safe’、’mark_safe’
django-debug-toolbar的作用?
django_debug_toolbar是django的第三方工具包,给django扩展了调试功能。
- 查看访问的速度、数据库的行为、cache命中等信息。
- 尤其在Mysql访问等的分析上大有用处(sql查询速度)
django中如何实现单元测试?
- 对于每一个测试方法都会将
setUp()和tearDown()方法执行一遍 - 会单独新建一个测试数据库来进行数据库的操作方面的测试,默认在测试完成后销毁。
- 在测试方法中对数据库进行增删操作,最后都会被清除。也就是说,在test_add中插入的数据,在test_add测试结束后插入的数据会被清除。
- django单元测试时为了模拟生产环境,会修改settings中的变量,例如, 把DEBUG变量修改为True, 把ALLOWED_HOSTS修改为[*]。
1 | from django.test import TestCase |
开启测试:
1 | # 测试整一个工程 |
解释orm中 db first 和 code first的含义?
ORM分为两种:
- DB First 数据库里先创建数据库表结构,根据表结构生成类,根据类操作数据库
- Code First 先写代码,执行代码创建数据库表结构,主流的orm都是code first。django 的orm也是code first,所以学的时候,本质就分为两块:
- 根据类自动创建数据库表
- 根据类对数据库表中的数据进行各种操作
django中如何根据数据库表生成model中的类?
修改seting文件,在setting里面设置要连接的数据库类型和名称、地址
运行下面代码可以自动生成models模型文件
1
python manage.py inspectdb
创建一个app
执行下下面代码:
1
python manage.py inspectdb > app/models.py
什么是ORM,使用orm和原生sql的优缺点?
对象关系映射,通过创建一个类,这个类与数据库的表相对应!类的对象代指数据库中的一行数据。
- SQL
优点:执行速度快
缺点:编写复杂,开发效率不高 - ORM
优点:让用户不再写SQL语句,提高开发效率。可以很方便地引入数据缓存之类的附加功能
缺点:在处理多表联查、where条件复杂查询时,ORM的语法会变得复杂。没有原生SQL速度快
django的contenttype组件的作用?
contenttype是django的一个组件(app),它可以将django下所有app下的表记录下来
可以使用他再加上表中的两个字段,实现一张表和N张表动态创建FK关系。
- 字段:表名称
- 字段:数据行ID
谈谈你对restfull 规范的认识?
restful其实就是一套编写接口的协议,规定如何编写以及如何设置返回值、状态码等信息。
最显著的特点:
用restful:
给用户一个url,根据method不同在后端做不同的处理比如:post创建数据、get获取数据、put和patch修改数据、delete删除数据。
不用restful:
给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/
当然,还有协议其他的,比如:
版本来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数- 状态码
- url中尽量使用名词、restful也可以称为
面向资源编程
https
域名
- api.oldboy.com
- www.oldboy.com/api
版本:
URL资源,名词
请求方式:
GET/POST/PUT/DELETE/PATCH/OPTIONS/HEADERS/TRACE
返回值:
- www.oldboy.com/api/v1/student/ -> 结果集
- www.oldboy.com/api/v1/student/1/ -> 单个对象
URL添加条件
状态码
错误信息
2
3
4
code:1000,
meg:'xxxx'
}
hyperlink
2
3
4
5
id:1
name: ‘xiangl’,
type: http://www.xxx.com/api/v1/type/1/
}
接口的幂等性是什么意思?
- 一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
- 所谓
影响相同,不是要求返回值完全相同,而且是指后续多余的调用对系统的数据一致性不造成破坏。
- 对于写入类操作,如果第一次写入是成功的,后续的写入应该抛出异常或者空操作,或者执行了写入但是未对数据造成变化。
- 对于读取类操作,需要保证其实现上是真正的读取,不能在读操作中夹带写操作。
- DELETE
http://www.forum.com/article/4231,调用一次和N次对系统产生的副作用是相同的,即删掉id为4231的帖子- 接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的。
一个接口通过首先进行1次访问,然后对该接口进行N次相同访问的时候,对访问对象不造成影响,没有副作用,那么就认为接口具有幂等性。
- GET, 第一次获取数据、第二次也是获取结果,幂等。
- POST, 第一次新增数据,第二次也会再次新增,非幂等。
- PUT, 第一次更新数据,第二次不会再次更新,幂等。
- PATCH,第一次更新数据,第二次可能再次更新,非幂等。
- DELTE,第一次删除数据,第二次不会再次删除,幂等。
什么是RPC?
远程过程调用协议
是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
进化的顺序: 现有的RPC,然后有的RESTful规范
Http和Https的区别?
- http信息是明文传输,https则是具有安全性的ssl加密传输协议。
- Http: 80端口。https: 443端口
- https协议需要到ca申请证书
为什么要使用django rest framework框架?
- 客户端-服务端分离
优点:提高用户界面的便携性,通过简化服务器,提高可伸缩性 - 无状态(Stateless):从客户端的每个请求要包含服务器所需要的所有信息
优点:提高可见性(可以单独考虑每个请求),提高了可靠性(更容易从局部故障中修复),提高可扩展性(降低了服务器资源使用) - 缓存(Cachable):服务器返回信息必须被标记是否可以缓存,如果缓存,客户端可能会重用之前的信息发送请求
优点:减少交互次数,减少交互的平均延迟 - 统一接口
优点:提高交互的可见性,鼓励单独改善组件 - 支持按需代码(Code-On-Demand 可选)
优点:提高可扩展性
- 提供了一些常用的组件,比如说
认证、权限、阈值等等,方便我们的时候,能让我们快速开发- 统一了接口,让我们单独改善组件,提高了可扩展性
- 支持按需使用,需要什么组件就导入什么组件就可以了
django rest framework框架中都有那些组件?
路由,自动帮助开发者快速为一个视图创建4个url
1
2
3
4
5www.oldboyedu.com/api/v1/student/$
www.oldboyedu.com/api/v1/student(?P<format>\w+)$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)/$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)(?P<format>\w+)$版本处理
- 问题:版本都可以放在那里?
- url
- GET
- 请求头
- 问题:版本都可以放在那里?
认证
问题:认证流程?权限
权限是否可以放在中间件中?以及为什么?访问频率的控制
匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。
如果要封IP,使用防火墙来做。- 登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,也无法防止。
视图
解析器 ,根据Content-Type请求头对请求体中的数据格式进行处理。request.data
分页
序列化
- 序列化
- source
- 定义方法
- 请求数据格式校验
- 序列化
渲染器
django rest framework框架中的视图都可以继承哪些类
继承 APIView
这个类属于rest framework中顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制,但凡是数据库、分页等操作都需要手动去完成,比较原始。继承
GenericViewSet(ViewSetMixin, generics.GenericAPIView)
如果继承它之后,路由中的as_view需要填写对应关系1
.as_view({'get':'list','post':'create'})
在内部也帮助我们提供了一些方便的方法:
- get_queryset
- get_object
- get_serializer
继承
ModelViewSet,mixins.CreateModelMixin,GenericViewSet, mixins.CreateModelMixin,GenericViewSet
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。
简述 django rest framework框架的认证流程。
如何编写?
请求进来认证需要编写一个类,类里实现authenticators方法,定制3类返回值。- 成功返回元组
- 返回none为匿名用户
- 抛出异常为认证失败。
源码流程:
请求进来先走dispatch方法,然后封装的request对象会执行user方法,由user触发authenticators认证流程。方法中可以定义三种返回值:- (user,auth),认证成功
- None , 匿名用户
- 异常 ,认证失败
django rest framework如何实现的用户访问频率控制?
- 基于用户IP限制访问频率
- 基于用户IP显示访问频率(利于Django缓存)
- view中限制请求频率
- 匿名时用IP限制+登录时用Token限制
- 全局使用
Django模型管理器
重写get_queryset方法
1 | class IsDeleteManager(models.Manager): |
Django的字段查询
属性名称__比较运算符=值.
1 | # 找出sname字段存在%的数据 |
跨关联关系
模型类名__属性名__比较运算符
1 | # 班级里面有名字叫何应良的学生 的班级有哪些? |
聚合函数
使用aggregate()函数返回聚合函数的值
1 | # 先引入 |
Django的session
session是一个字典,敏感数据存储在字典的values中,现在我将字典的key作为cookie返回给客户端.
获取session
1 | def main(request): |
设置cookies
1 | def showmain(request): |
设置过期:
1 | def showmain(request): |
设置存储session的位置:
1 | # 默认存储在数据库中 |
在模板里使用session
使用request.session
1 | {% if request.session.username %} |
SQLAlchemy
SQLAlchemy如何执行原生SQL?
1 | # 使用execute方法直接操作SQL语句(导入create_engin、sessionmaker) |
ORM的实现原理?
- 映射类:描述数据库表结构,
- 映射文件:指定数据库表和映射类之间的关系
- 数据库配置文件:指定与数据库连接时需要的连接信息(数据库、登录用户名、密码or连接字符串)
SQLAchemy中如何为表设置引擎和字符编码?
设置引擎编码方式为utf8
sqlalchemy设置编码字符集一定要在数据库访问的URL上增加charset=utf8,否则数据库的连接就不是utf8的编码格式
1
eng = create_engine('mysql://root:root@localhost:3306/test2?charset=utf8',echo=True)
设置数据库表编码方式为utf8
1
2
3
4
5
6
7
8
9
10class UserType(Base):
__tablename__ = 'usertype'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='管理员')
# 添加配置设置编码
__table_args__ = {
'mysql_charset':'utf8'
}__table_args__还可设置存储引擎、外键约束等等信息。
SQLAchemy中如何设置联合唯一索引?
通过UniqueConstraint字段来设置联合唯一索引
1 | # h_id和username组成联合唯一约束 |
GIT
- git init 初始化,当前所在的文件夹可以被管理且以后版本相关的数据都会存储到.git文件中
- git status 查看当前文件夹以及子目录中文件是否发生变化:内容修改/新增文件/删除,已经变化的文件会变成红色,已经add的文件会变成绿色
- git add . 给发生变化的文件(贴上一个标签)或 将发生变化的文件放到某个地方,只写一个句点符就代表把git status中红色的文件全部打上标签
- git commit -m ‘新增用户登录认证功能以及xxx功能’ 将“绿色”文件添加到版本中
- git log 查看所有版本提交记录,可以获取版本号
- git reset –hard 版本号 将最新的版本回退到更早的版本
- git reflog 回退到之前版本后悔了,再更新到最新或者最新之前的版本
- git reset –hard 版本 回退
简述以下git中stash命令作用以及相关其他命令
- ‘git stash’:将当前工作区所有修改过的内容存储到“某个地方”,将工作区还原到当前版本未修改过的状态
- ‘git stash list’:查看“某个地方”存储的所有记录
- ‘git stash clear’:清空“某个地方”
- ‘git stash pop’:将第一个记录从“某个地方”重新拿到工作区(可能有冲突)
- ‘git stash apply’:编号, 将指定编号记录从“某个地方”重新拿到工作区(可能有冲突)
- ‘git stash drop’:编号,删除指定编号的记录
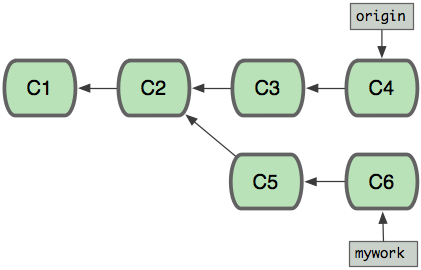
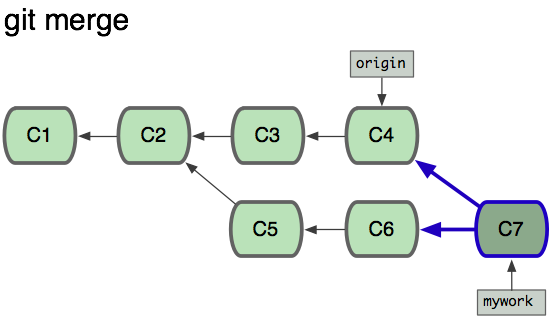
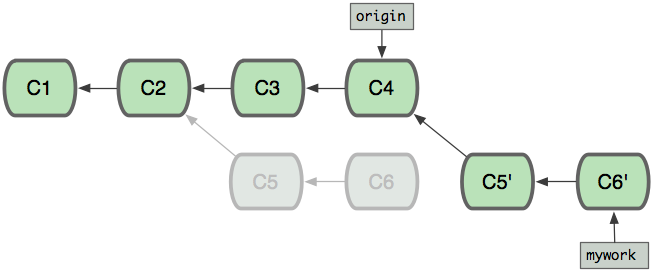
git 中 merge 和 rebase 命令的区别
merge:
会将不同分支的提交合并成一个新的节点,之前的提交分开显示,
注重历史信息、可以看出每个分支信息,基于时间点,遇到冲突,手动解决,再次提交
rebase:
将两个分支的提交结果融合成线性,不会产生新的节点;
注重开发过程,遇到冲突,手动解决,继续操作
使用merge
使用rebase
公司如何基于git做的协同开发?
- 切换到develop分支 :>>> git checkout develop
- 分出一个功能性分支: >>> git checkout -b feature-discuss
- 在功能性分支上进行开发工作,多次commit,测试以后…
- 把做好的功能合并到develop中:
- git checkout develop # 回到develop分支
- git merge–no-ff feature-discuss# 把做好的功能合并到develop中
- git branch -d feature-discuss # 删除功能性分支
- git push origin develop # 把develop提交到自己的远程仓库中
如何基于git实现代码review?
根据开发任务,建立git分支, 分支名称模式为feature/任务名,比如关于API相关的一项任务,建立分支feature/api。
git checkout -b feature/api运行git branch 确认切换到了feature/api分支
编辑代码完成开发任务, commit相关代码
git add -A
git commit -m “implement api architecture”将分支代码push到服务器
git push origin -u feature/api登录到bitbucket的源代码库,如https://bitbucket.org/xxxx/ljq_web ,点击Pull request按钮去创建一个pull request
再pull request详细页面, 填写相关标题/说明/reviewer, 目前请将reviewer设成lijing_dkhs和zhuangqunxiong
请提醒reviewer去审核pull request,系统也会发邮件提醒reviewer
Reviewer打开pull request页面,查看代码修改情况,也可以在相应的代码处添加注视,提示代码作者哪里应该修正。
代码作者根据reviewer的要求,调整代码后commit/push到服务器。 然后reviewer继续设置, 如此循环,直到没有问题。
当代码没有问题以后, 需要将任务代码merge到主代码库, 有两种方法:
- Reviewer可以在pull request页面点击Merge按钮, 把代码merge到主代码库
- 代码作者自己merge到主代码库, 并push到服务器。
git pull origin
git log ..master
如果看到master里有修改没在当前分支, 那么运行git rebase master来把master的修改加入到当前分支
运行一下合并命令
git checkout master
git merge –no-ff feature/api
git push代码作者删除feature子分支。
git checkout master
git branch -D feature/api
git push origin :feature/api
git如何实现v1.0 、v2.0 等版本的管理?
使用git tag –a tagname –m “comment”可以快速创建一个标签。
需要注意,命令行创建的标签只存在本地Git库中,还需要使用Git push –tags指令发布到服务器的Git库中
git中 .gitignore文件的作用
告诉Git哪些文件不需要添加到版本管理中。
什么是敏捷开发?
- 敏捷开发以
用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。 - 在敏捷开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备可视、可集成和可运行使用的特征。
- 换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。
Celery
简述 celery 是什么以及应用场景?
Celery是由Python开发的一个简单、灵活、可靠的处理大量任务的分发系统,它不仅支持实时处理也支持任务调度。
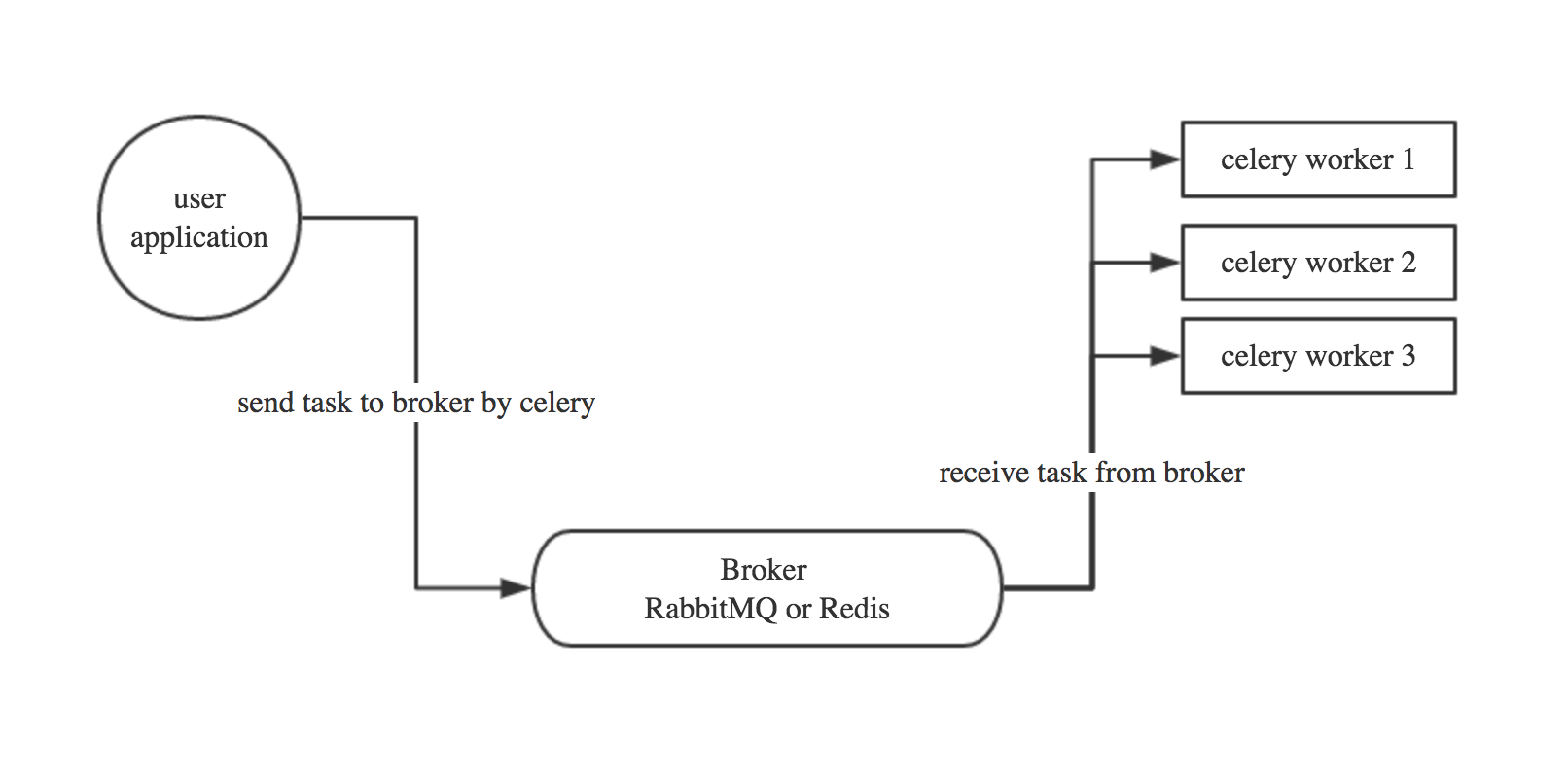
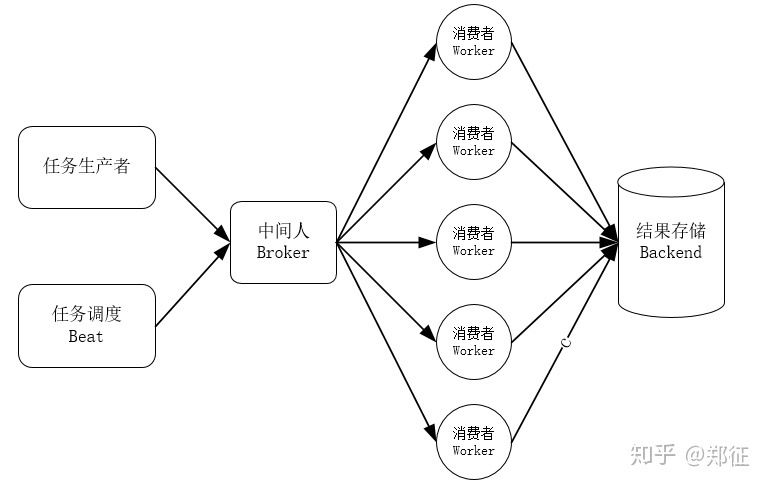
- user:用户程序,用于告知celery去执行一个任务。
- broker: 存放任务(依赖RabbitMQ或Redis,进行存储)
- worker:执行任务
简述 celery多任务结构目录
1 | pro_cel |
celery中装饰器 @app.task 和 @shared_task的区别
@shared_task 这个装饰器。这些任务是所有app共享的。
- 一般情况使用的是从celeryapp中引入的app作为的装饰器:@app.task
- django那种在app中定义的task则需要使用@shared_task
如果开启多个worker
celery -A 项目名 worker -loglevel=info: 前台启动命令celery multi start w1 -A 项目名 -l info: 后台启动命令celery multi restart w1 -A 项目名 -l info: 后台重启命令celery multi stop w1 -A 项目名 -l info: 后台停止命令
w1是worker的名称
爬虫
简述requests模块的作用及基本使用?
- 封装了urllib,模拟浏览器的请求
- 常用参数:url、headers、cookies、data、json、params、proxy
- 常用返回值:content、iter_content、text 、encoding=”utf-8”、cookie.get_dict()、
简述 beautifulsoup模块的作用及基本使用?
用于从HTML或XML文件中提取、过滤想要的数据形式
常用方法:find、find_all、text、attrs、get
简述 seleninu 模块的作用及基本使用?
- selenium最初是一个
自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 - selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
scrapy框架中各组件的工作流程?
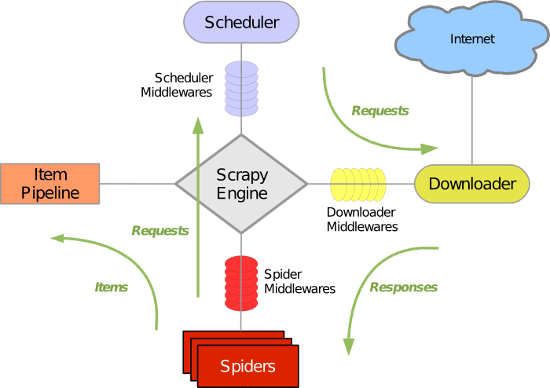
- 生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,
默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发 - 在回调函数中,解析response并且返回值
返回值可以4种:- 包含解析数据的字典
- Item对象
- 新的Request对象(新的Requests也需要指定一个回调函数)
- 或者是可迭代对象(包含Items或Request)
- 在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但你也可以使用Beutifulsoup,lxml。 - 最后,针对返回的Items对象将会被持久化到数据库
通过Item Pipeline组件存到数据库 或者导出到不同的文件(通过Feed exports)
在scrapy框架中如何设置代理(两种方法)?
1 | from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware |
1 | # 方式一:内置添加代理功能 |
scrapy框架中如何实现大文件的下载?
1 | from twisted.web.client import Agent, getPage, ResponseDone, PotentialDataLoss |
scrapy中如何实现限速?
- 在Scrapy中,下载延迟是通过计算建立TCP连接到接收到HTTP包头(header)之间的时间来测量的。
- AUTOTHROTTLE_START_DELAY指定的下载延迟启动。当接收到回复时,下载延迟会调整到该回复的延迟与之前下载延迟之间的平均值
scrapy中如何实现暂停爬虫?
一个把调度请求保存在磁盘的调度器
一个把访问请求保存在磁盘的副本过滤器[duplicates filter]
一个能持续保持爬虫状态(键/值对)的扩展
Job 路径
要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。这个路径将会存储所有的请求数据来保持一个单独任务的状态(例如:一次spider爬取(a spider run))。必须要注意的是,这个目录不允许被不同的spider 共享,甚至是同一个spider的不同jobs/runs也不行。也就是说,这个目录就是存储一个 单独 job的状态信息。
scrapy中如何进行自定制命令?
在spiders同级创建任意目录,如:commands
在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
1 | from scrapy.commands import ScrapyCommand |
在settings.py 中添加配置 COMMANDS_MODULE = ‘项目名称.目录名称’
在项目目录执行命令:scrapy crawlall
scrapy中如何实现的记录爬虫的深度?
- ‘DepthMiddleware’是一个用于追踪每个Request在被爬取的网站的深度的中间件。
其可以用来限制爬取深度的最大深度或类似的事情。 - ‘DepthMiddleware’可以通过下列设置进行配置(更多内容请参考设置文档):
- ‘DEPTH_LIMIT’:爬取所允许的最大深度,如果为0,则没有限制。
- ‘DEPTH_STATS’:是否收集爬取状态。
- ‘DEPTH_PRIORITY’:是否根据其深度对requet安排优先
scrapy中的pipelines工作原理?
- Scrapy 提供了 pipeline 模块来执行保存数据的操作。
- 在创建的 Scrapy 项目中自动创建了一个 pipeline.py 文件,同时创建了一个默认的 Pipeline 类。我们可以根据需要自定义 Pipeline 类,然后在 settings.py 文件中进行配置即可
scrapy的pipelines如何丢弃一个item对象?
通过raise DropItem()方法
简述scrapy中爬虫中间件和下载中间件的作用?
scrapy-redis组件的作用?
- scheduler - 调度器
- dupefilter - URL去重规则(被调度器使用)
- pipeline - 数据持久化
常见的反爬虫和应对方法
- 通过Headers反爬虫,
其中最常用就是User-Agent,Referer,Host三个值 - 基于用户行为反爬虫
同一IP短时间内多次访问同一页面,这时就可以设置下载延迟,使用IP池 - 动态页面的反爬虫
爬取的数据是通过ajax请求得到,或者通过JavaScript生成的 - 检查cookies
可以自定义设置cookie策略 - 采用验证码
- 蜜罐
Scrapy框架
- url调度器 : 将url封装成request
- 经过request中间件
- 发送到下载器,下载器返回response
- response经过response中间件
- response到spider处理,产生Item或者request
- item到Item pipeline处理
工具
简述 vitualenv 及应用场景?
vitualenv是一个独立的python虚拟环境
如:当前项目依赖的是一个版本,但是另一个项目依赖的是另一个版本,这样就会造成依赖冲突,而virtualenv就是解决这种情况的,virtualenv通过创建一个虚拟化的python运行环境, 将我们所需的依赖安装进去的,不同项目之间相互不干扰
简述 pipreqs 及应用场景?
查找python项目依赖并生成requirements.txt
1 | pipreqs ./ 生成requirements.txt |
当然也可以使用
1 | pip freeze > requirements.txt |
在Python中使用过什么代码检查工具?
- PyFlakes:静态检查Python代码逻辑错误的工具。
- Pep8: 静态检查PEP8编码风格的工具。
- NedBatchelder’s McCabe script:静态分析Python代码复杂度的工具。
- Python代码分析工具:PyChecker、Pylint
B Tree和B+ Tree的区别?
- B树中同一键值不会出现多次,并且有可能出现在叶结点,也有可能出现在非叶结点中。
而B+树的键一定会出现在叶结点中,并有可能在非叶结点中重复出现,以维持B+树的平衡。 - 因为B树键位置不定,且在整个树结构中只出现一次,
请列举常见查找并通过代码实现任意三种。
无序查找、二分查找、插值查找
请列举你熟悉的设计模式?
工厂模式/单例模式等
supervisor的作用?
是一款基于Python的进程管理工具,可以很方便的管理服务器上部署的应用程序。
是C/S模型的程序,其服务端是supervisord服务,客户端是supervisorctl命令
主要功能:
- 启动、重启、关闭包括但不限于python进程。
- 查看进程的运行状态。
- 批量维护多个进程。
什么是反向代理?
正向代理代理客户端(客户端找哟个代理去访问服务器,服务器不知道你的真实IP)
反向代理代理服务器(服务器找一个代理给你响应,你不知道服务器的真实IP)
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
简述SSH的整个过程。
SSH 为 ‘Secure Shell’ 的缩写,是建立在应用层基础上的安全协议。
SSH 是目前较可靠,为远程登录会话和其他网络服务提供的安全性协议。
利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。
Linux
10个Linux常用命令
- ls
- pwd
- cd
- touch
- rm
- mkdir
- tree
- cp
- mv
- cat
- more
- grep
- echo
重定向 > 和 >>
- 表示输出,会覆盖文件原有的内容
- 表示追加,会将内容追加到已有文件的末尾
- 如何查看剩余内存
- 如何查看端口是否被占用
- 如何查看一个程序的PID以及它的所有子进程
- 如何为一个目录下的所有文件添加权限
- 如果你对一个目录具有写权限,那么你是否具有对这个目录下的所有文件具有删除权限?
- 对Linux多路复用的理解
- 修改IP地址的方法
解释 PV、UV 的含义?
PV访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。
UV访问数(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。
解释 QPS的含义?
‘QPS(Query Per Second)’
每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准