网络编程 网络编程就是如何在程序中实现两台计算机的通信.
用python进行网络编程,就是在python程序本身这个进程内,连接别的服务器进程的通信端口进行通信.
TCP编程
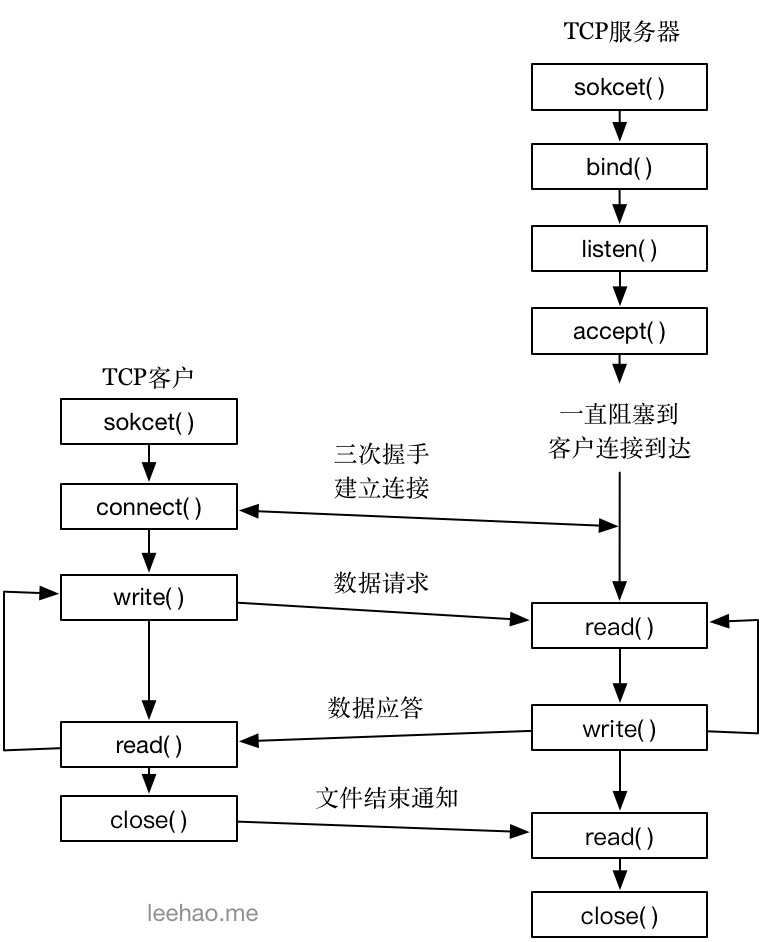
服务器
socket():创建一个socket.
bind():绑定端口号
listen():监听.(可以设置参数,允许几个客户端连接)
accept():等待客户端的连接
客户端:
socket():客户端初始化一个Socket
connect():连接服务器
如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据
最后关闭连接,一次交互结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import socketsk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) sk.connect(('www.sina.com.cn' ,80 )) sk.send((b'GET / HTTP/1.1\r\n' b'Host: www.sina.com.cn\r\n' b'Connection: close\r\n\r\n' )) data = [] while True : tempData = sk.recv(1024 ) if tempData: data.append(tempData) else : break datStr = (b'' .join(data)).decode('utf-8' ) sk.close() print (datStr)
服务器与客户端的简单连接:
服务器:
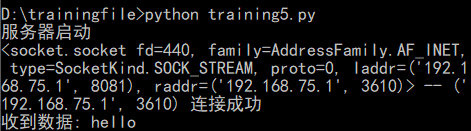
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import socketserver = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('192.168.75.1' ,8081 )) server.listen(5 ) print ('服务器启动' )clientSocket,clientAddress = server.accept() print (f'{clientSocket} -- {clientAddress} 连接成功' )while True : data = clientSocket.recv(1024 ).decode('utf-8' ) print (f'收到数据: {data} ' ) clientSocket.send('so do you' .encode('utf-8' ))
客户端:
1 2 3 4 5 6 7 8 9 10 11 12 import socketclient = socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(('192.168.75.1' ,8081 )) while True : data = input ('请输出给服务器发送的数据: ' ).encode('utf-8' ) client.send(data) info = client.recv(1024 ).decode('utf-8' ) print (f'服务器响应为: {info} ' )
这里有一个问题,那就是服务器其实只允许一个客户端连接:clientSocket,clientAddress = server.accept()只会执行一次,执行完,程序控制权就一直只while True里面了.这样就无法连接其他客户端了.
要想解决这样问题,必须使用多进程/多线程.
TCP是建立可靠的连接,并且通信双方都可以以流的形式发送数据 .
读书快
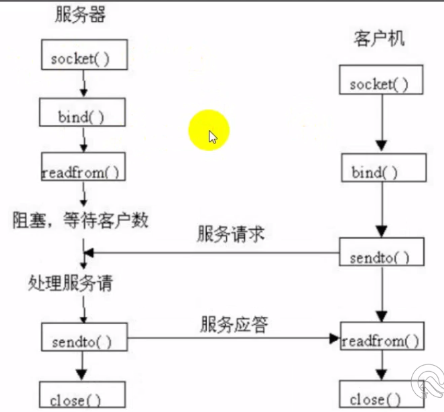
常用于广播
服务器与客户端的通讯:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import socketudp_server = socket.socket(socket.AF_INET,socket.SOCK_DGRAM) udp_server.bind(('192.168.75.1' ,8081 )) print ('服务器启动' )while True : data,addr= udp_server.recvfrom(1024 ) print ('客户端响应为: ' ,data.decode('utf-8' )) info = input ('请输入数据: ' ).encode('utf-8' ) udp_server.sendto(info,addr)
1 2 3 4 5 6 7 8 9 10 11 12 import socketclient = socket.socket(socket.AF_INET,socket.SOCK_DGRAM) print ('客户端启动' )while True : data = input ('请输入数据:' ).encode('utf-8' ) client.sendto(data,('192.168.75.1' ,8081 )) info = client.recv(1024 ).decode('utf-8' ) print (f'服务器响应为: {info} ' )
进程和线程 操作系统是如何同时运行多个任务
单核CUP实现多任务原理:
单核CUP实现多任务原理:
并发:看上去一起执行,任务数多于CPU核心数
并行:真正的一起执行,任务数不多于CPU核心数
实现多任务的方式:
多进程模式
多线程模式
协程模式
多线程+多进程模式
对于操作系统而言,==一个任务就是一个进程==.
进程是系统在程序执行和 资源分配的基本单位.每个进程都有自己的数据段,代码段和堆栈段
单任务与多任务:
1 2 3 4 5 6 7 8 9 10 11 import timedef run (): while 1 : print (123 ) time.sleep(1 ) while 1 : print (456 ) time.sleep(1 ) run()
我们看上面的代码,下面的run()永远不会执行.
创建==子==进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timefrom multiprocessing import Processdef run (): while 1 : print (123 ) time.sleep(1 ) if __name__ == '__main__' : print ('父进程启动' ) p = Process(target=run) p.start() while 1 : print (456 ) time.sleep(1 )
注意:p = Process(target=run)创建的是一个子进程
父子进程的先后顺序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timefrom multiprocessing import Processdef run (): print ('子进程启动' ) time.sleep(3 ) print ('子进程结束' ) if __name__ == '__main__' : print ('父进程启动' ) p = Process(target=run) p.start() print ('父进程结束' )
父进程并没有等着子进程结束.
如果要让父进程等待子进程结束:使用p.join()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import timefrom multiprocessing import Processdef run (): print ('子进程启动' ) time.sleep(3 ) print ('子进程结束' ) if __name__ == '__main__' : print ('父进程启动' ) p = Process(target=run) p.start() p.join() print ('父进程结束' )
所以一般我们设计的时候就是在一个父进程里创建多个子进程,子进程同时运行.
全局变量在多个进程中不能共享
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import timefrom multiprocessing import Processnum = 1 def run (): print ('子进程开始' ) global num num += 1 print ('子进程结束' ,num) if __name__ == '__main__' : print ('父进程启动' ) p = Process(target=run) p.start() p.join() print ('父进程结束' ,num)
在子进程里修改全局变量对于父进程没有影响
原因:
启动大量子进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import timeimport osimport randomfrom multiprocessing import Pooldef run (name ): print (f'子进程{name} 启动:{os.getpid()} ' ) start = time.time() time.sleep(random.randint(1 ,4 )) end = time.time() print (f'子进程{name} 结束:{os.getpid()} --{end-start:.01 f} ' ) if __name__ == '__main__' : print ('父进程启动' ) p = Pool(4 ) for i in range (5 ): p.apply_async(run, args=(i,)) p.close() p.join() print ('父进程结束' )
进程间的通讯:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import osimport timefrom multiprocessing import Process, Queuedef write (q ): print ('启动写子进程' ) for each in ['a' ,'b' ,'c' ]: q.put(each) time.sleep(1 ) print ('结束写子进程' ) def read (q ): print ('启动读子进程' ) while True : value = q.get(True ) print (f'value= {value} ' ) print ('结束读子进程' ) if __name__ == '__main__' : print ('父进程开始' ) q = Queue() pw = Process(target=write,args=(q,)) pr = Process(target=read,args=(q,)) pw.start() pr.start() pw.join() pr.terminate() print ('父进程结束' )
在一个进程的内容,要同时干多件事,就需要同时运行多个子任务,我们把进程内的这些子任务叫做线程.
线程是共享内存空间的并发执行的多任务,每一个线程都共享一个进程的资源.
线程是最小的执行单元,而进程由至少一个线程组成,如何调用进程和线程,完全由操作系统决定,程序自己不能决定.
任何进程默认都会启动一个线程,称为主线程.主线程可以启动新的子线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import threadingimport timedef run (): print (f'子线程{threading.current_thread().name} 启动' ) time.sleep(2 ) print (123 ) time.sleep(2 ) print (f'子线程{threading.current_thread().name} 结束' ) if __name__ == '__main__' : print (f'主线程{threading.current_thread().name} 启动' ) t = threading.Thread(target=run,name='root_thread' ) t.start() print (f'主线程{threading.current_thread().name} 结束' )
可以看到,主线程并没有等待子线程结束.
线程间共享数据,所以会出现数据混乱.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import threading num = 0 def run (n ): global num for i in range (10000000 ): num += n num -= n if __name__ == '__main__' : t1 = threading.Thread(target=run,args=(6 ,)) t2 = threading.Thread(target=run,args=(9 ,)) t1.start() t2.start() t1.join() t2.join() print (num)
这时可以使用线程锁 来解决
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import threading lock = threading.Lock() num = 0 def run (n ): global num for i in range (10000000 ): lock.acquire() try : num += n num -= n finally : lock.release() if __name__ == '__main__' : t1 = threading.Thread(target=run,args=(6 ,)) t2 = threading.Thread(target=run,args=(9 ,)) t1.start() t2.start() t1.join() t2.join() print (num)
锁阻塞了多线程的并发执行,包含锁的某段代码实际上之恩能够以单线程模式执行,所以效率大大降低了.
1 2 3 4 5 6 7 8 9 10 11 12 13 lock.acquire() try : num += n num -= n finally : lock.release() with lock: num += n num -= n
由于可以存在多个锁,不同的线程持有不同的锁,并试图获取其他的锁,可能造成死锁,导致多个线程挂起,只能靠操作系统强制终止.
第二种解决方法:使用ThreadLocal:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import threadinglocal = threading.local() num = 0 def run (x,n ): x += n x -= n def func (n ): local.x = num for i in range (1000000 ): run(local.x,n) print (f'{threading.current_thread().name} ------{local.x} ' ) if __name__ == '__main__' : t1 = threading.Thread(target=func,args=(6 ,)) t2 = threading.Thread(target=func,args=(9 ,)) t1.start() t2.start() t1.join() t2.join() print (num)
local:
使用进程来实现socket边监听边响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import socket,threadingserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.bind(('192.168.75.1' , 8081 )) server.listen(5 ) print ('服务器启动,等待客户端的连接' )def run (ck ): while True : data = ck.recv(1024 ).decode('utf-8' ) print (f'收到数据: {data} ' ) sendData = "this is server's response" .encode('utf-8' ) ck.send(sendData) while True : clientSocket, clientAddress = server.accept() print (f'客户端 {clientAddress} 连接成功' ) t = threading.Thread(target=run,args=(clientSocket,)) t.start()
1 2 3 4 5 6 7 8 9 10 11 12 import socketclient = socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(('192.168.75.1' ,8081 )) while True : data = input ('请输出给服务器发送的数据' ).encode('utf-8' ) client.send(data) info = client.recv(1024 ).decode('utf-8' ) print (f'服务器响应为: {info} ' )
信号量控制线程数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import threading,timesem = threading.Semaphore(3 ) def run (): with sem: for i in range (4 ): print (f'{threading.current_thread().name} ---{i} ' ) time.sleep(1 ) if __name__ == "__main__" : for i in range (5 ): threading.Thread(target=run).start()
上面代码:
1 2 for i in range (5 ): threading.Thread(target=run).start()
只有五个线程执行完毕才会结束.sem = threading.Semaphore(3)限定了同时最多只有3个线程.所以这段代码会先执行3个线程,然后在执行2个线程.(每个线程打印0-3)
凑够一定数量的线程才能执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import threading,timebar = threading.Barrier(4 ) def run (): print (f'{threading.current_thread().name} ---start' ) time.sleep(1 ) bar.wait() print (f'{threading.current_thread().name} ---end' ) if __name__ == "__main__" : for i in range (6 ): threading.Thread(target=run).start()
上面代码,需要执行完6个线程才会结束.bar.wait()时会等待,凑够4个线程才会执行.
定时线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import threadingdef run (): print ('hello world' ) if __name__ == "__main__" : t = threading.Timer(5 ,run) t.start() t.join() print ('父线程结束' )
线程通讯
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import threading,timedef func (): event = threading.Event() def run (): for i in range (5 ): event.wait() event.clear() print (i) threading.Thread(target=run).start() return event if __name__ == "__main__" : e = func() for _ in range (5 ): time.sleep(2 ) e.set ()
当执行e = func()的时候就已经启动线程了,但是执行到event.wait()的时候线程被挂起.e.set()的时候线程恢复.
如果去掉event.clear(),则是等待2秒后直接打印0,1,2,3,4
其实wait和clear和e.set()只是设置一个标志符而已:
执行event.wait()则把flag位置为False(False就是阻塞),
遇到e.set()就把flag设置为True.
event.clear()再次把flag设置为True.
生产者和消费者
回忆进程间通讯
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import threading,time,queue,randomdef product (id ,q while True : num = random.randint(0 ,1000 ) q.put(num) print (f'生产者{id } 生产了{num} 数据放入了队列' ) time.sleep(3 ) q.task_done() def customer (id ,q while True : item = q.get() if item is None : break print (f'消费者{id } 消费了{item} 数据' ) time.sleep(2 ) q.task_done() if __name__ == "__main__" : q = queue.Queue() for i in range (4 ): threading.Thread(target=product,args=(i,q)).start() for i in range (3 ): threading.Thread(target=customer,args=(i,q)).start()
线程调度:
线程1打印0,2,4,6,8
线程2打印1,3,5,7,9
现在想设计一段程序按序打印0-9
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import threading,timecond = threading.Condition() def run1 (): with cond: for i in range (0 ,10 ,2 ): print (threading.current_thread().name,i) time.sleep(1 ) cond.wait() cond.notify() def run2 (): with cond: for i in range (1 ,10 ,2 ): print (threading.current_thread().name,i) time.sleep(1 ) cond.notify() cond.wait() if __name__ == "__main__" : threading.Thread(target=run1).start() threading.Thread(target=run2).start()
解释:
注意run1和run2的wait和notify顺序不可改变
进程与线程:
多任务的实现原理:
多进程:
主进程就是Master,其他进程就是Worker
优点:稳定性高:
缺点:
创建进程的代价大:
操作系统能同时运行的进程数有限:
多线程:
主线程就是Master,其他线程就是Worker
优点:
多线程模式通常比多进程快一点,但是也快不到哪去
在Windows下,多线程的效率比多进程要高
缺点:
计算密集型vs IO密集型:
计算密集型
IO密集型
进程和线程的形象比喻:
计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。
假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。
进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
一个车间里,可以有很多工人。他们协同完成一个任务。线程就好比车间里的工人。一个进程可以包括多个线程。
车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫“互斥锁” (Mutual exclusion,缩写Mutex),防止多个线程同时读写某一块内存区域。
还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。
这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做”信号量”(Semaphore),用来保证多个线程不会互相冲突。
操作系统的设计,因此可以归结为三点:
通俗点说:
异步与同步:
异步:多任务,多个任务之间执行没有先后顺序,可以同时运行,执行的先后顺序不会有什么影响,存在的多条运行主线
同步:多任务,多个任务之间执行的时候要求有先后顺序,必须一个先执行完成之后,另一个才能继续执行,只有一个主线
阻塞:从调用者的角度出发,如果在调用的时候,被卡住,不能再继续向下运行,需要等待,就说是阻塞。
非阻塞:从调用者的角度出发,如果在调用的时候,没有被卡住,能够继续向下运行,无需等待,就说是非阻塞。
协程 子程序/子函数:
概述:
eg:
1 2 3 4 5 6 7 8 9 10 11 12 def func1 (): print (1 ) print (2 ) print (3 ) def func2 (): print ('x' ) print ('y' ) print ('y' )
看起来A.B执行过程有点像线程,但协程的特点在于是一个线程
优点:与线程相比,协程的执行效率极高,因为只有一个线程,也不存在同时写变量的冲突,在协程中共享资源不加锁,只需要判断状态
python对协程的支持是通过generator实现的
1 2 3 4 5 6 7 8 9 10 11 12 def run (): print (1 ) yield 10 print (2 ) yield 20 print (3 ) yield 3 m = run() print (next (m))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def func (): data = '' r = yield data print (r,data) r = yield data print (r,data) r = yield data print (r,data) if __name__ == "__main__" : f = func() print (f.send(None )) print (f.send('hyl' )) print (f.send('123' ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def product (c ): c.send(None ) for i in range (5 ): print (f'---生产者生产数据{i} ' ) r = c.send(i) print (f'***消费者消费数据{r} ' ) c.close() def customer (): data = 1000 while True : n = yield data print (f'+++消费者消费数据{n} ' ) data += 1 c = customer() product(c)
注意这两个函数的关系有点像master和worker的关系.
customer不断的被挂起,然后又被调用,之后又被挂起.