读取文件的方法 正常的读取文件的方法 1 2 3 def read_file (file_route ): with open (file_route,r'' ) as f: print (f.readlines())
使用生成器1 1 2 3 4 def read_file (file_route ): with open (file_route,r'' ) as f: for line in f: yield line
使用生成器2 1 2 3 def read_file (file_route ): with open (file_route,r'' ) as f: yield from f
漂亮的读取文件的方法 1 2 3 4 5 6 7 def read_file (file_route ): with open (file_route,'r' ) as f: yield from iter (f.readline,'' ) file_route = r'D:\trainingfile\training.txt' for line in read_file(file_route): print (line)
使用mmap(处理超大文件) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import mmapdef read_file (file_route ): with open (file_route, "r+" ) as f: mm = mmap.mmap(f.fileno(), 0 ) yield from iter (mm.readline,b'' ) mm.close() if __name__=="__main__" : file_route = r'D:\trainingfile\training.txt' for line in read_file(file_route): print (line)
os的常用操作 os操作 (文件和目录操作)
文件和目录操作 和Linux及其相近
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import osprint (os.getcwd())print (os.listdir(r'D:\trainingfile' ))os.mkdir('123' ) os.rmdir('123' ) os.rename('test.py' ,'test2.py' ) os.remove('13.py' )
os.walk方法,主要用来遍历一个目录内各个子目录和子文件。
1 2 3 4 5 6 import osfor root, dirs, files in os.walk(r'D:\trainingfile' ): print (root) print (dirs) print (files)
os.path操作 (路径操作) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import osos.path.join(r'c:\a\b' ,r'c\d' ) os.path.split(r'c:\a\b\c\d.py' ) os.path.splitext(r'c:\a\b\c\d.py' ) os.path.isdir(r'c:\a\b\c\d.py' ) os.path.isfile(r'c:\a\b\c\d.py' ) os.path.exists(r'd:\note' ) os.path.exists(r'D:\trainingfile\config.py' ) os.path.dirname(r'D:\trainingfile\config.py' ) os.path.dirname(r'D:\trainingfile' )
获取目录下所有文件(深度优先-递归版) 1 2 3 4 5 6 7 8 9 10 import osdef print_dir_content (dir_name ): for child in os.listdir(dir_name): print (child) new_dir = os.path.join(dir_name,child) if os.path.isdir(new_dir): print_dir_content(new_dir) print_dir_content(r'F:\乱七八糟\360安全浏览器下载\chrome\下载\messing\小说' )
获取目录下所有文件(深度优先-迭代版) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import osdef print_dir_content (dir_name ): stack = [dir_name] while stack: cur = stack.pop() print (cur) if os.path.isdir(cur): stack.extend([os.path.join(dir_name,child) for child in os.listdir(cur)]) print_dir_content(r'F:\乱七八糟\360安全浏览器下载\chrome\下载\messing\小说' )
获取目录下所有文件(广度优先-迭代版) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import osdef print_dir_content (dir_name ): queue = os.listdir(dir_name) while queue: tmp = [] for child in queue: print (child) new_dir = os.path.join(dir_name,child) if os.path.isdir(new_dir): tmp.extend(os.listdir(new_dir)) queue = tmp print_dir_content(r'F:\乱七八糟\360安全浏览器下载\chrome\下载\messing\小说' )
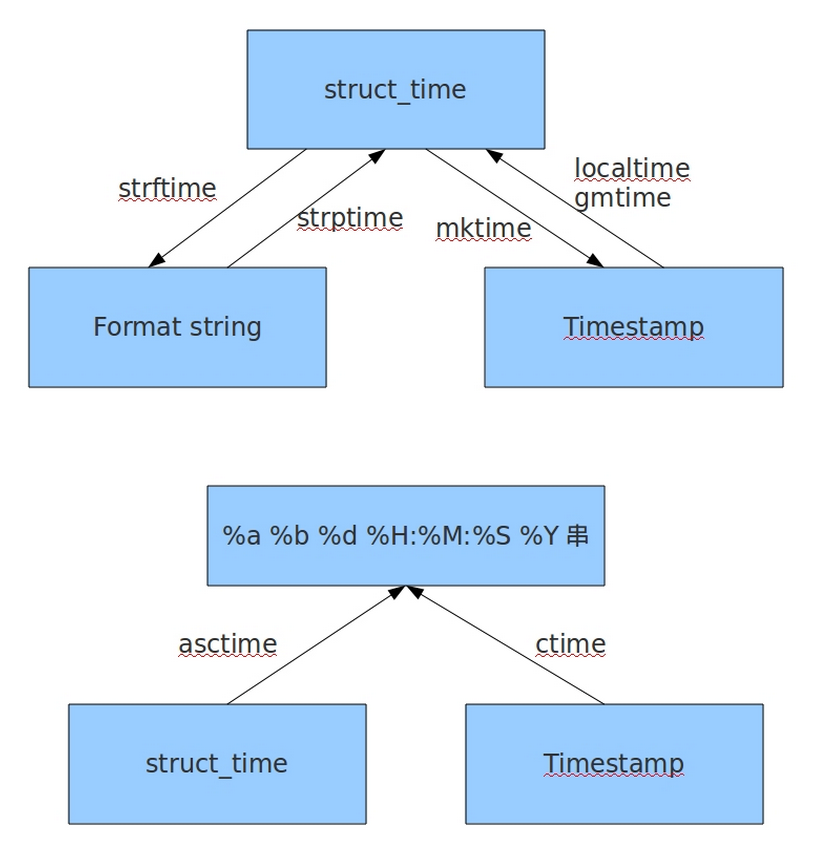
Time模块
time模块基于Unix Timestamp。
datetime模块基于time进行了封装,提供更多函数。
这两个模块都处理事件,但是对于时间的封装却不同 。
time模块提供struct_time类, 即(time tuple, p_tuple, 时间元组)
datetime模块常用datetime和timedelta类,也提供了date、time类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timep_tuple = time.localtime() print (p_tuple) print (time.time()) print (time.mktime(p_tuple)) print (time.asctime(p_tuple)) print (time.ctime(time.time())) print (time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime()))s = '2016-08-25 16:30:58' print (time.strptime(s, "%Y-%m-%d %H:%M:%S" ))
字典两种排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 d= {'a' :24 ,'g' :52 ,'i' :12 ,'k' :33 } for val,key in sorted (zip (d.values(),d.keys())): print (val,key) x = sorted (d,key=lambda x:d[x]) print (x)
列表有索引错误,但是没有切片错误 1 2 3 4 list = ['a' ,'b' ,'c' ,'d' ,'e' ]print (list [10 ]) print (list [10 :])
集合操作 1 2 3 4 a = t | s b = t & s c = t – s d = t ^ s
创建单例的方法 法一 : 使用基类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class A : __instance = None def __new__ (cls,*args,**kwargs ): if not cls.__instance: cls.__instance = super ().__new__(cls) return cls.__instance def __init__ (self,name ): self.name = name a1 = A('hyl' ) a2 = A('dsz' ) print (id (a1)) print (id (a2)) print (a1.name) print (a2.name)
法二 : 使用类装饰器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def singleton (cls ): instances = {} def wrap (*args,**kwargs ): if cls not in instances: instances[cls] = cls(*args,**kwargs) return instances[cls] return wrap @singleton class A : pass a1 = A() a2 = A() print (a1 is a2)
法三 : 使用元类 1 2 3 4 5 6 7 8 9 10 11 12 13 class Singleton (type def __call__ (cls, *args, **kwargs ): if not hasattr (cls, '_instance' ): cls._instance = super ().__call__(*args, **kwargs) return cls._instance class Foo (metaclass=Singleton ): pass foo1 = Foo() foo2 = Foo() print (foo1 is foo2)
设计实现遍历目录与子目录,抓取.pyc文件 法一 : 使用递归 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import osdef find_pyc (dir_name ): children = os.listdir(dir_name) for child in children: child_route = os.path.join(dir_name,child) if os.path.isdir(child_route): yield from find_pyc(child_route) if os.path.isfile(child_route) and os.path.splitext(child_route)[-1 ] == '.pyc' : yield child_route if __name__ == '__main__' : for file in find_pyc(r'D:\note\Celery\_trainingfile\workspace' ): print (file)
法二 : 使用os.walk 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import osdef find_pyc (dir_route ): res = [] for root,_,files in os.walk(dir_route): for file in files: if os.path.splitext(file)[-1 ] == '.pyc' : res.append(os.path.join(root,file)) return res if __name__ == '__main__' : x= find_pyc(r'D:\note\Celery\_trainingfile\workspace' ) print (x)
字符串的操作题目 全字母短句 PANGRAM 是包含所有英文字母的句子.实现一个方法 get_missing_letter, 传入一个字符串采纳数,返回参数字符串变成一个 PANGRAM 中所缺失的字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from string import ascii_lowercasefrom collections import OrderedDictdef get_missing_letter (string ): d = OrderedDict() d = d.fromkeys(ascii_lowercase,0 ) string = string.lower() for s in string: if s in ascii_lowercase: d[s] = True for char,appear in d.items(): if not appear: print (char) get_missing_letter("A quick brown for jumps over the lazy dog" )
不使用内置api,将字符串 "123" 转换成 123 1 2 3 4 5 6 7 8 def change (str_nums ): res = 0 for str_num in str_nums: num = ord (str_num) - ord ('1' ) + 1 res = res*10 + num return res print (change('1382' ))
统计一个文本中单词频次最高的10个单词 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import refrom heapq import nlargestdef top10 (file_name ): def yield_word (file_name ): with open (file_name,'r' ) as f: for line in f: lineone = re.sub(r'\W+' ,' ' ,line) yield from lineone.split() res = {} for word in yield_word(file_name): res[word] = res.get(word,0 ) + 1 return nlargest(10 ,res,key=lambda x:res[x]) if __name__ == '__main__' : route = r'D:\trainingfile\config.yaml' print (top10(route))
返回索引 注意 : index是list和tuple的方法
1 2 3 4 x = 1 y = [1 ,2 ,3 ,5 ] print (y.index(x))
复杂排序 传入list,让所有奇数都在偶数前面,而且奇数升序排列,偶数降序排序
1 2 3 def func (alist ): return sorted (alist,key=lambda x: int (x) % 2 == 0 and 20 - int (x) or int (x)) print (func([1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ]))
搜索旋转数组 假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。
示例 1:
输入: nums = [2,5,6,0,0,1,2], target = 0
示例 2:
输入: nums = [2,5,6,0,0,1,2], target = 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution (object def search (self, nums, target ): left = 0 right = len (nums) while left < right: mid = left + (right - left) // 2 if nums[mid] == target: return mid if nums[mid] >= nums[left]: if nums[left] <= target < nums[mid]: right = mid else : left = mid + 1 else : if nums[mid] < target <= nums[right]: left = mid + 1 else : right = mid return -1 s = Solution() print (s.search([4 ,5 ,6 ,7 ,0 ,1 ,2 ],6 ))
遍历一个object的所有属性,并print每一个属性名 使用dir方法
常用的装饰器写法 使用函数作为装饰器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from time import perf_counterdef deco (func ): def wrap (*args,**kwargs ): start = perf_counter() func(*args,**kwargs) print (f'{perf_counter() - start :0.2 f} ' ) return wrap @deco def func (): return [num for num in range (1 ,11177771 )] func()
使用类作为装饰器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from time import perf_counterclass TimeCounter : def __init__ (self,func ): self.func = func def __call__ (self,*args,**kwargs ): start = perf_counter() self.func(*args,**kwargs) print (perf_counter() - start) @TimeCounter def func (): return [num for num in range (1 ,11177771 )] func()
一行代码解决阶乘函数 1 2 from functools import reduceprint (reduce(lambda x,y:x*y,range (1 ,5 )))
一行代码实现将1-N 的整数列表以3为单位分组 1 2 3 4 N =10 print ([[num for num in range (N+1 )][i:i+3 ] for i in range (1 ,N+1 ,3 )])