数据库
NoSQL优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活性,半结构化数据
- 没有复杂的关系
缺点:
- 没有标准化
- 有限的查询功能
- 最终一致是不直观的程序
NoSQL分类:
- 列存储:
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势 - 文档存储:
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系散据库的某些功能 - Key-value存储:
可以通过key快速查询到其value,一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) - 图存储:
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据 - XML存储:
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath
| SQL术语 | MongoDB术语 | 解释说明 |
|---|---|---|
| database | database | 数据库 |
| table | collecion | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id设置为主键 |
文档:
{name:“张三”,age:20,hobby:{“看书”,“旅游”,“唱歌”}}
注意:
- 文档中的键/值对是有序的。
- 文档的键必须是字符串
如果将文档类比成数据库中的行,那么集合就可以类比成数据库的表
在mongodb中的集合是无模式的,也就是说集合中存储的文档的结构可以是不同的,比如下面的两个文档可以同时存入到一个集合中:
{“name”:”hyl”}
{“name”:”hyl”,”age”:1}
| Type | Number | String | Notes |
|---|---|---|---|
| Double | 1 | “double” | —– |
| 字符串 | 2 | “string” | —– |
| 对象 | 3 | “object” | —– |
| 数组 | 4 | “array” | —– |
| 二进制数据 | 5 | “binData” | —– |
| 未定义 | 6 | “undefined” | 已过期 |
| ObjectId | 7 | “objectId” | —– |
| Boolean | 8 | “bool” | —– |
| 日期 | 9 | “date” | —– |
| 空 | 10 | “null” | —– |
| 正则表达式 | 11 | “regex” | —– |
| DBPointer | 12 | “dbPointer” | 已过期 |
| JavaScript(代码) | 13 | “javascript” | 此数据类型用于将JavaScript代码存储到文档中 |
| 符号 | 14 | “symbol” | 已过期 |
| JavaScript(带范围) | 15 | “javascriptWithScope” | —– |
| 32位整数 | 16 | “int” | —– |
| 时间戳 | 17 | “timestamp” | —– |
| 64位整数 | 18 | “long” | —– |
| Decimal128 | 19 | “decimal” | New in version 3.4 |
| Min key | -1 | “minKey” | —– |
| Max key | 127 | “maxKey” | —– |
操作mongoDB数据库
创建数据库:
如果数据库不存在则创建数据库,否则切换到指定的数据库1
use 数据库名
查看所有数据库:
1
show dbs
注意:刚创建的数据库是不能显示的.必须插入数据库才能显示
查看当前正在使用的数据库
1
db
或:
1
db.getName()
删除数据库:
1
db.dropDatabase()
插入数据
1
db.student.insert({name:"hyl",age:18,gender:1,address:"北京"})
断开连接:
1
exit
操作集合
查看当前数据库下有哪些集合
1
show collections
创建集合
1
db.createCollection("集合名")
或者:
创建一个空的集合并添加一个文档1
db.集合名.insert(document)
删除当前数据库中的集合
1
db.集合名.drop(document)
操作文档
插入文件
使用 insert()方法插入文档
1
db.集合名.insert(document)
eg:
1
2db.student.insert(
{name:"hyl",age:18,gender:1,address:"北京"})如果要插入多条数据:
注意要添加中括号:1
2
3db.student.insert(
[{name:"hyl",age:18,gender:1,address:"北京"},
{name:"dsz",age:15,gender:0,address:"广州"},])使用save方法插入文档:
1
db.集合名.save(文档)
如果不指定_id字段,save()方法类似于 Insert()方法.如果指定_id字段,则会更新_id字段的数据.
1
2db.student.save(
{name:"hyl",age:18,gender:1,address:"北京"})1
2
3db.student.save(
{_id:ObjectId(5995096201 723fe2a0d8d17"},name:"poi",age:22,gender:7 address:"石家庄",isDelete:e}
)
文档更新:
udate()方法用于更新已经存在的文档
1
2
3
4
5
6
7
8
9db.集合名.update(
query,
update,
{
upset:<boolean>,
multi:<boolean>,
writeConcern:<document>
}
)参数说明:
- query:
updata的查询条件,类似于sql里的update语句内where后面的内容. - update:
update的对象和一些更新的操作符($set,$inc)等 - upset:
可选.如果不存在update的记录,是否当成新数据插入,true为插入,False为不插入(默认False) - multi:
可选.如果查找到多条数据,是否更新全部数据,否则只更新一条数据(默认False) - writeConcern:
可选,抛出异常的级别.
- query:
示例:将李雷的年龄更新为25
1
db.student.update({name:"lilei"},{$set:{age:25}})
将所有名字是李雷的人年龄更新为25
1
db.student.update({name:"lilei"},{$set:{age:25}},{mutil:true})
save()方法通过传入的文档替换已有文档:
1
2
3
4
5
6db.集合名.save(
document,
{
writeConcern:<document>
}
)
文档删除
说明:在执行 removel()函数前,先执行find命令来判断执行的条件是否存在是一个良好习惯
1
2
3
4
5
6
7db.集合名.remove(
query,
{
justOne:<boolean>,
writeConcern:<document>
}
)- query:
可选,删除文档的条件 - justOne:
可选,如果为tureen或1,则只删除一个文档 - writeConcern:
可选,抛出异常的级别.
- query:
eg:删除名字为tom的学生
1
2
3db.student.remove({name:"tom"})
db.student.remove({name:"tom"},{justOne:"true"})
文档查询:
find()方法:
1
2
3
4// 查询集合下所有的文档
db.集合名.find()
db.student.find()1
2
3
4
5
6
7
8
9
10
11// 查询指定列
db.集合名.find(
query,
{
<key>:1,
<key>:1
}
)
// 查看年龄为18的所有人的姓名,性别:
db.student.find({age:18},{name:1,age:1})query:查询条件
key:要显示的字段,1表示显示pretty()方法以格式化的方式来显示文档
1
bd.student.find().pretty()
findOne():方法查询匹配结果哦第一条数据
1
db.student.findOne({gender:0})
查询条件操作符:
$gt,$gte,$lt,$lte:大于,大于等于,小于,小于等于.1
2
3
4db.集合名.find(<key>:{$gt:<value>})
// 查询年龄大于20的学生
db.student.find({age:{$gt:20}})1
2// 查询年龄大于20,小于40的学生
db.student.find({age:{$gte:20,$lte:40}})等于使用冒号
:1
db.student.findOne({gender:0})
使用id进行查询:
1
db.student.find({"_id":ObjectId("59995084b019723fe2a0d8d14")})
id查询某个结果集的数据条数
1
db.student.find().count()
查询某个字段的值当中是否包含另一个值
1
2// 查询名字包含yl的学生
db.student.find({name:/yl/})ObjectId()查询某个字段的值是否以另一个值开头
1
2// 查询名字以h开头的学生
db.student.find({name:/^h/})
and,or:
1
2
3db.集合名.find(条件1,条件2,条件3....)
db.student.find({age:{$gt:16},gender:0})1
2
3
4
5db.集合名.find({
$or:[{条件1},{条件2},{条件3}....]
})
db.student.find({$or:[{age:{$gt:16}},{gender:0}]})1
2
3
4
5db.集合名.find({
条件1,
条件2,
$or:[{条件3},{条件4}]
})limit,skip:
limit():读取指定数量的数据记录
1
db.student.find().limit(2)
skip():跳过指定数量的数据
1
2// 跳过前三条
db.student.find().skip(3)limit与skip联合使用:
实现分页功能1
db.student.find().skip(3).limit(2)
排序:
1
db.集合名.find().sort(<key>:1|-1)
1表示升序,-1表示降序
1
db.student.find().sort(age:1)
Redis
终端运行redis:
进入目录,执行redis-cli.exe
- redis是key-vaue的数据,所以每个数据都是一个键值对
- 键的类型是字符串
- 值的类型分为五种:
- 字符串string
- 哈希hash
- 列表list
- 集合set
- 有序集合zset
- 数据操作的全部命令http://redis.cn/commands.html
字符串string
String是 redis最基本的类型,最大能存储512M的数据.
string类型是二进制安全的,即可以存储任何数据、比如数字,图片、序列化对象等
设置
设置键值:
set key value1
set a_key "a_value"
设置值键值及过期时间,以秒为单位
setex key seconds value1
setex a_key 10 "a_value"
设置多个键值:
1
mset key1 value1 key2 value2 key3 value3
获取:
- 根据键获取值,如果将不存在者None
get key - 根据多个键获取多个值
get key1 key2 key3…
- 根据键获取值,如果将不存在者None
运算
要求:值是字符串类型的数字
将key对应的值加1/减1:
1
2incr key1
decr key2将key对应的值加n/减n:
1
2incrby key intnum
decrby key intnum
其他
- 追加值(比如给字符串最后加一个标点符号)
append key value - 获取值长度
strlen key
- 追加值(比如给字符串最后加一个标点符号)
key
查找键:
keys pattern
(注意:pattern支持正则)1
2# 查找全部
keys *判断键是否存在,如果存在返回1,不存在返回0:
exsits key查看键对应的value类型:
type key删除键及对应的值
del key1 key2 key3…
设置过期时间(以秒为单位):
expire key seconds查看有效时间(以秒为单位):
ttl key
哈希hash
用于存储对象
1
{name:"tom",age:18}
设置:
设置单个值:
hset key field value1
2hset student1 name hyl
hset student1 age 18设置多个值:
hmset key filed1 value1 filed2 value2…1
hmset student1 name hyl age 18
获取:
获取一个属性的值:
hget key filed1
hget student1 name
获取多个属性的值:
1
hmget student1 name age gander
获取所有属性和值:
1
hgetall student1
获取所有的属性:
1
hkeys student1
获取所有的值:
1
hvals student1
返回包含属性的个数:
1
hlen student1
其他:
判断属性是否存在:
1
hexists student1 name
删除属性及值
1
2
3hdel key field1 field2...
hdel student1 name gender获取指定field的长度:
1
hstrlen student1 age
列表list
概述:
列表的元素类型为 string,按照插入顺序排序,在列表的头部或尾部添加元素.
其实就是一个双向队列.设置:
在头部插入:
1
2
3lpush key value1 value2....
lpush students hyl在尾部插入:
1
rpush key value
在一个元素的前|后插入新元素:
1
linsert key before|after pivot value
1
2# 在students对应的列表中,在hyl元素的后面添加一个dsl
linsert students after hyl dsl设置指定索引的元素值:
1
lset key index value
1
2# 在students对应的列表中,将索引值为2的元素的值改为40
lset students 2 40
获取:
弹出key对应的list的第一个元素.
1
lpop key
弹出key对应的list的最后一个元素.
1
rpop key
注意:索引值可以是负数,表示偏移量是从另外一边开始
返回存储在key的列表中的指定范围的元素:
1
lrange key start end
1
2# 弹出index0-2的元素
lrange students 0 21
2# 弹出全部的元素
lrange students 0 -1
其他:
裁剪列表:改为原集合的一个子集
1
ltrim key start end
注意包含上下限:
eg:ltrim students 0 1:获取前两个元素返回list长度
1
llen key
返回列表中索引对应的值
1
2
3
4lindex key index
# 获取students对应的列表中索引值为20的元素
lindex students 20
集合set
无序集合,==元素类型为string类型==.
设置:
添加元素
1
2
3
4sadd key menber1 menber2...
# 添加一个集合,集合元素为hyl,gzr,dsz
sadd students hyl gzr dsz获取:
返回key集合中所有元素
1
2
3
4smembers key
# 返回students对应的集合的所有元素
sadd students返回集合元素个数:
1
2
3scard key
scard students
其他:
交集:
1
sinter key1 key2 key3...
差集
1
sdiff key1 key2 key3...
合集
1
sunion key1 key2 key3...
判断元素是否在集合中
1
sismumber key member
有序集合zset
有序集合,元素类型为 Sting,元素具有唯一性,不能重复
每个元素都会关联一个double类型的 score(表示权重)通过权重进行大小排序,元素的 score可以相同.设置:
添加
1
zadd key score1 member1 score2 member2...
获取:
返回指定范围的元素(第几个元素到第几个元素)
1
2
3
4zrange key start end
# 查看全部的数据
zrange students 0 -1返回元素个数
1
zcard key
返回有序集合key中,score在min和max之间的元素
1
zcount key min max
返回有序集合key中,成员 member的 score值
1
2
3
4zscore key member
# 查看students中hyl的权重
zscore students hyl
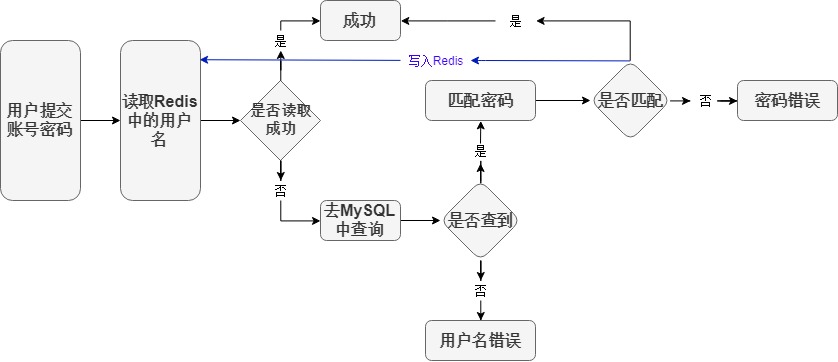
redis其实一般是用于缓存的.(因为redis的查询速度很快)
- 公司使用MySQL存储全部数据,使用redis存储常用数据(比如说账号密码)
- 用户登录时,服务器先去redis查询该用户
- 如果查询成功,那么直接从redis返回数据(不经过MySQL)
- 如果查询失败,那么再去MySQL里查询数据.
然后把查询过来的数据存储到Redis里