第7章 数据清洗和准备 本章讨论处理缺失数据、重复数据、字符串操作和其它分析数据转换的⼯具。下⼀章,我会关注于⽤多种⽅法合并、重塑数据集。
7.1 处理缺失数据 pandas对象的所有描述性统计默认都不包括缺失数据。
pandas使⽤浮点值NaN(Not a Number)表示缺失数据。我们称其为哨兵值,它表示不可⽤not available。
检测哨兵值很简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import pandas as pdimport numpy as npstring_data = pd.Series(['aardvark' , 'artichoke' , np.nan, 'avocado' ,None ]) print (string_data)print (string_data.isnull())
NaN的处理方法
滤除缺失数据
对于⼀个Series,dropna返回⼀个仅含⾮空数据和索引值的Series:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import pandas as pdimport numpy as npfrom numpy import nan as NAdata = pd.Series([1 , NA, 3.5 , NA, 7 ]) print (data)print (data.dropna())print (data[data.notnull()])
对于DataFrame对象,dropna默认丢弃含有缺失值的行 (默认axis=0):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import pandas as pdimport numpy as npfrom numpy import nan as NAdata = pd.DataFrame([[1. , 6.5 , 3. ], [1. , NA, NA], [NA, NA, NA], [NA, 6.5 , 3. ]]) print (data)print (data.dropna())print (data.dropna(how='all' ))print (data.dropna(axis=1 ))print (data.dropna(axis=0 ))df = pd.DataFrame(np.random.randn(7 , 3 )) df.iloc[:4 , 1 ] = NA df.iloc[:2 , 2 ] = NA print (df)print (df.dropna())print (df.dropna(thresh=2 ))
填充缺失数据
fillna⽅法:
通过⼀个常数调⽤fillna,就会将缺失值替换为那个常数值
通过⼀个字典调⽤fillna,就会对不同的列 填充不同的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import pandas as pdimport numpy as npfrom numpy import nan as NAadict = {'col1' :[1. , 1. , NA,NA], 'col2' :[6.5 , NA, NA,6.5 ], 'col3' :[3.0 , NA, NA,3.0 ],} df = pd.DataFrame(adict,index=['a' ,'b' ,'c' ,'d' ]) print (df)print (df.fillna(0 ))print (df.fillna('hyl' ,axis=1 ))print (df.fillna({'col1' : 0.5 , 'col3' : 0 }))print (df.T.fillna({'b' :'uu' }).T)
fillna的其他参数:
inplace:
method:
limit:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import pandas as pdimport numpy as npfrom numpy import nan as NAadict = {'col1' :[1. , 1. , NA,NA], 'col2' :[6.5 , NA, NA,6.5 ], 'col3' :[3.0 , NA, NA,3.0 ],} df = pd.DataFrame(adict,index=['a' ,'b' ,'c' ,'d' ]) print (df)a = df.fillna(0 , inplace=True ) print (a)print (df)df = pd.DataFrame(np.random.randn(6 , 3 )) df.iloc[2 :, 1 ] = NA df.iloc[4 :, 2 ] = NA print (df)print (df.fillna(method='ffill' ))print (df.fillna(method='ffill' , limit=2 ))print (df.fillna('hyl' ,limit=2 ))
注意:value参数不一定要是参数,大可以传入其他值
1 2 3 4 5 6 7 8 9 data = pd.Series([1. , NA, 3.5 , NA, 7 ]) print (data.fillna(data.mean()))
7.2 数据转换 本节讲过滤、清理以及其他的转换⼯作。
移除重复数据:
duplicated:
drop_duplicates:
df.drop_duplicates([‘k1’]):
keep:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import pandas as pdimport numpy as npdata = pd.DataFrame({'k1' : ['one' , 'two' ] * 3 + ['two' ], 'k2' : [1 , 1 , 2 , 3 , 3 , 4 , 4 ]}) print (data)print (data.duplicated())print (data.drop_duplicates())data['v1' ] = range (7 ) print (data)print (data.drop_duplicates(['k1' ]))print (data.drop_duplicates(['k1' , 'k2' ], keep='last' ))
利⽤函数或映射进⾏数据转换
map:实现元素级 转换以及其他数据清理⼯作的便捷⽅式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import pandas as pdimport numpy as npdata = pd.DataFrame({'food' : ['bacon' , 'pulled pork' , 'bacon' , 'Pastrami' , 'corned beef' , 'Bacon' , 'pastrami' , 'honey ham' , 'nova lox' ], 'ounces' : [4 , 3 , 12 , 6 , 7.5 , 8 , 3 , 5 , 6 ]}) print (data)meat_to_animal = { 'bacon' : 'pig' , 'pulled pork' : 'pig' , 'pastrami' : 'cow' , 'corned beef' : 'cow' , 'honey ham' : 'pig' , 'nova lox' : 'salmon' } lowercased = data['food' ].str .lower() print (lowercased)data['animal' ] = lowercased.map (meat_to_animal) print (data)result = data['food' ].map (lambda x: meat_to_animal[x.lower()]) print (result)
map, applymap apply的区别:
map:
applymap:
apply:
替换值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import pandas as pdimport numpy as npdata = pd.Series([1. , -999. , 2. , -999. , -1000. , 3. ]) print (data)print (data.replace(-999 , np.nan))print (data.replace([-999 , -1000 ], np.nan))print (data.replace([-999 , -1000 ], [np.nan, 0 ]))print (data.replace({-999 : np.nan, -1000 : 0 }))
重命名轴索引
使用map
使用rename
可以传入函数映射
可以传入字典实现部分标签的更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import pandas as pdimport numpy as npdata = pd.DataFrame(np.arange(12 ).reshape((3 , 4 )), index=['Ohio' , 'Colorado' , 'New York' ], columns=['one' , 'two' , 'three' , 'four' ]) print (data)transform = lambda x: x[:4 ].upper() print (data.index.map (transform))data.index = data.index.map (transform) print (data)print (data.rename(index=str .title, columns=str .upper))result = data.rename(index={'OHIO' : 'INDIANA' }, columns={'three' : 'peekaboo' }) print (result)x = data.rename(index={'OHIO' : 'INDIANA' }, inplace=True ) print (x)
离散化和⾯元划分
为了便于分析,连续数据常常被离散化或拆分为面元(bin)。⾯元。
使用pandas.cut函数:cats = pd.cut(ages, bins)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import pandas as pdimport numpy as npages = [20 , 22 , 25 , 27 , 21 , 23 , 37 , 31 , 61 , 45 , 41 , 32 ] bins = [18 , 25 , 35 , 60 , 100 ] cats = pd.cut(ages, bins) print (type (cats))print (cats)print (cats.codes)print (cats.categories)print (pd.value_counts(cats))cats = pd.cut(ages, [18 , 26 , 36 , 61 , 100 ], right=False ) print (cats)ages = [20 , 22 , 25 , 27 , 21 , 23 , 37 , 31 , 61 , 45 , 41 , 32 ] bins = [18 , 25 , 35 , 60 , 100 ] group_names = ['Youth' , 'YoungAdult' , 'MiddleAged' , 'Senior' ] cats = pd.cut(ages, bins, labels=group_names) print (cats)data = np.random.rand(20 ) print (data)print (pd.cut(data, 4 , precision=2 ))
qcut是⼀个⾮常类似于cut的函数,它可以根据样本分位数对数据进⾏⾯元划分.因此可以得到大小基本相等的面元 :(每个面元的元素数量基本相等)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import pandas as pdimport numpy as npdata = np.random.randn(1000 ) cats = pd.qcut(data, 4 ) print (cats)print (pd.value_counts(cats))ca = pd.qcut(data, [0 , 0.1 , 0.5 , 0.9 , 1. ]) print (ca)print (pd.value_counts(ca))
检测和过滤异常值:
np.sign(df):根据数据的值是正还是负,返回1或-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import pandas as pdimport numpy as npdata = pd.DataFrame(np.random.randn(1000 , 4 )) print (data.describe())col = data[2 ] print (col[np.abs (col) > 3 ])print (data[(np.abs (data) > 3 ).any (axis=1 )])data[np.abs (data) > 3 ] = np.sign(data) * 3 print (data.describe())
排列和随机采样:
numpy.random.permutation():
df.take():
df.sample(n=3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import pandas as pdimport numpy as npdf = pd.DataFrame(np.arange(5 * 4 ).reshape((5 , 4 ))) print (df)sampler = np.random.permutation(5 ) print (sampler)print (df.take([1 ],axis=1 ))print (df.take(sampler))print (df.sample(n=3 ))
计算指标/哑变量
前期知识预备:
在构建回归模型时,如果自变量X为连续性变量,回归系数β可以解释为:在其他自变量不变的条件下,X每改变一个单位,所引起的因变量Y的平均变化量;如果自变量X为二分类变量,例如是否饮酒(1=是,0=否),则回归系数β可以解释为:其他自变量不变的条件下,X=1(饮酒者)与X=0(不饮酒者)相比,所引起的因变量Y的平均变化量。
但是,当自变量X为多分类变量 时,例如职业、学历、血型、疾病严重程度等等,此时仅用一个回归系数来解释多分类变量之间的变化关系,及其对因变量的影响,就显得太不理想。
此时,我们通常会将原始的多分类变量转化为哑变量,每个哑变量只代表某两个级别或若干个级别间的差异,通过构建回归模型,每一个哑变量都能得出一个估计的回归系数,从而使得回归的结果更易于解释,更具有实际意义。
哑变量:也叫虚拟变量( Dummy Variables)
分类型变量:
哑变量:
D1
D2
D3
腺癌
0
0
0
粘液腺癌
1
0
0
印戒细胞癌
0
1
0
特殊类型癌
0
0
1
也就是说我们引进了3个变量来表达上述4种病理类型,3个变量分别是D1、D2和D3。
为什么不引入4个变量呢?伍德里奇在《计量经济学导论》中说“如果某个定性变量有m种互相排斥的类型,则模型中只能引入m-1个虚拟变量,否则会陷入虚拟变量陷阱,产生完全共线性。”感兴趣的可以了解一下。不感兴趣的,知道某一个变量如果有m个互斥的分类设成m-1个哑变量 就ok了。
==设置哑变量就是为了将分类变量数量化==,然后纳入分析模型进行分析。哑变量的引入,扩大了回归分析中自变量的纳入范围,也就是说分类变量也可以纳入回归分析啦。
参考资料:回归模型中的哑变量是个啥?何时需要设置哑变量?
将分类变量(categorical variable)转换为哑变量或指标矩阵。
get_dummies函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import pandas as pdimport numpy as npse = pd.Series({'key' : ['hyl' ,'dsz' ,'czj' ,'gzr' ,'hyl' ,'gzr' ]}) print (se)print (pd.get_dummies(se['key' ]))df = pd.DataFrame({'key' : ['b' , 'b' , 'a' , 'c' , 'a' , 'b' ]}) print (df)print (pd.get_dummies(df['key' ]))df = pd.DataFrame({'key' : ['b' , 'b' , 'a' , 'c' , 'a' , 'b' ], 'data1' : range (6 )}) print (df)print (pd.get_dummies(df['key' ]))
注意:
df[['data1']]:DataFrame类型df['data1']:Series类型
index对象具有字典的映射功能:
get_loc(value):获得一个标签的索引值
get_indexer(values):获得一组标签的索引值,当值不存在则返回-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import pandas as pdimport numpy as npdf = pd.DataFrame({'key' : ['b' , 'b' , 'a' , 'c' , 'a' , 'b' ], 'data1' : range (6 )}) print (df)x = pd.get_dummies(df['key' ]) print (type (x))print (x)dummies = pd.get_dummies(df['key' ], prefix='hyl' ) print (dummies)df_with_dummy = df[['data1' ]].join(dummies) print (df_with_dummy)print (type (df[['data1' ]]))print (type (df['data1' ]))
如果DataFrame中的某⾏同属于多个分类,则事情就会有点复杂。
1 2 3 4 5 6 movies.dat的内容为: 1::Toy Story (1995)::Animation|Children's|Comedy 2::Jumanji (1995)::Adventure|Children's|Fantasy 3::Grumpier Old Men (1995)::Comedy|Romance 4::Waiting to Exhale (1995)::Comedy|Drama
有三列,电影id,标题,分类.可以发现,一部电影有很多的分类
现在要找出所有的分类,并且构建指标(找出每部电影含有和不含有的分类):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 import pandas as pdimport numpy as npmnames = ['movie_id' , 'title' , 'genres' ] movies = pd.read_table('datasets/movielens/movies.dat' , sep='::' , header=None , names=mnames) print (movies.head())all_genres = [] for x in movies.genres: all_genres.extend(x.split('|' )) genres = pd.unique(all_genres) print (type (genres))print (genres)print ('-------------------' )zero_matrix = np.zeros((len (movies), len (genres))) dummies = pd.DataFrame(zero_matrix, columns=genres) for i, gen in enumerate (movies.genres): indices = dummies.columns.get_indexer(gen.split('|' )) dummies.iloc[i, indices] = 1 movies_windic = movies.join(dummies.add_prefix('Genre_' )) print (movies_windic.iloc[0 ])
⼀个对统计应⽤有⽤的秘诀是:结合get_dummies和诸如cut之类的离散化函数 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import pandas as pdimport numpy as npnp.random.seed(12345 ) values = np.random.rand(10 ) print (values)bins = [0 , 0.2 , 0.4 , 0.6 , 0.8 , 1 ] categories = pd.cut(values, bins) print (categories)print (pd.get_dummies(categories))
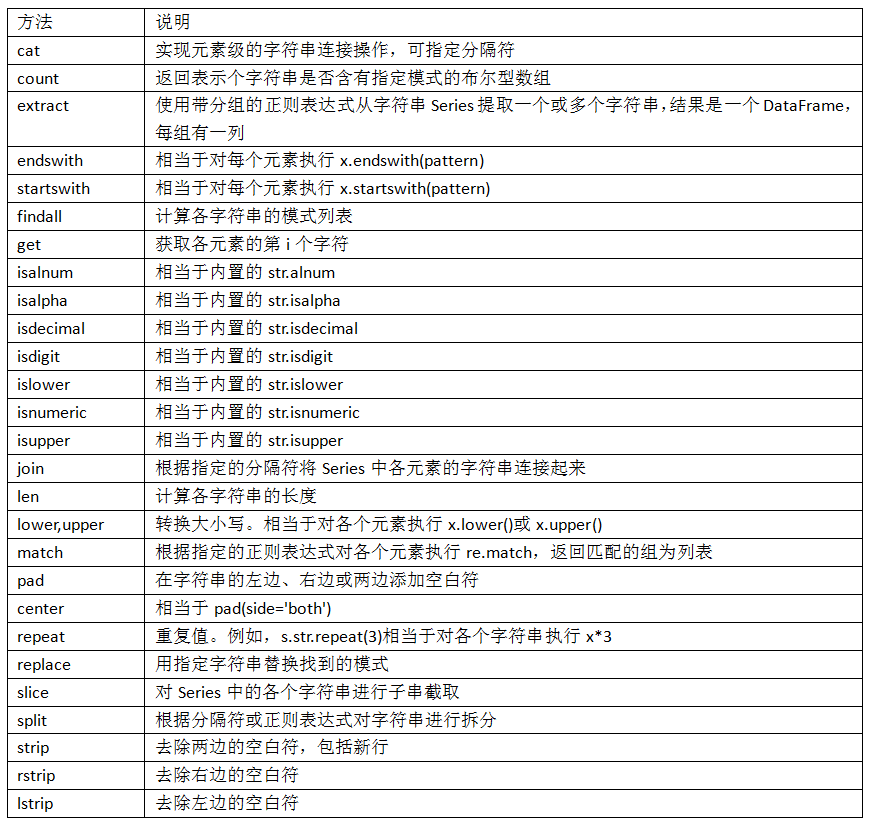
7.3 字符串操作 字符串对象⽅法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 val = 'a,b, guido' print (val.split(',' ))pieces = [x.strip() for x in val.split(',' )] print (pieces)val = '::' .join(pieces) print (val)print (val.find('guido' ))print (val.count(':' ))print (val.replace(':' ,'' ))
正则:re.split方法
1 2 3 4 5 import retext = 'hyl is \t sb' print (re.split('\s' ,text))
pandas的⽮量化字符串函数
就像前面说的,series.map能将函数映射到数据上,但是如果存在NA(null)就会报错。
pandas调用python的原生字符串方法要加一个str,有点类似于Scrapy
==pandas调用正则也是在前面添加str==
也就是说,pandas的字符串方法和正则表达式共用一个str属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 import reimport pandas as pdimport numpy as npdata = {'Dave' : 'asdasd dave@google.com' , 'Steve' : 'asdasd steve@gmail.com' , 'Rob' : 'asdasd rob@gmail.com' , 'Wes' : np.nan} data = pd.Series(data) print (data)print (data.str .contains('gmail' ))pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}' result = data.str .findall(pattern, flags=re.IGNORECASE) print (result)matches = data.str .match(pattern, flags=re.IGNORECASE) print (matches)print (matches.str .get(1 ))print (matches.str [0 ])print (data.str [:5 ])
部分⽮量化字符串⽅法